环境
windows 7
jdk 1.8
idea 2021.2
1. Spark 3.1.2 20211107
目的
在 windows 本地 可以在 IDE中 ,用java 写spark,并在里面执行
前置
已经安装 jdk1.8。
注意, 没有安装scala
安装开发工具 IDE IDEA
从官网下载 IDEA, 这里 2021.2, 安装, 想办法注册 ,找来淘宝
添加安装路径/bin 到 环境变量 Path中:
spark安装包配置
将之前从官网下载的 spark包,spark-3.1.2-bin-hadoop3.2.tgz,解压,
E:\Programs\spark-3.1.2-bin-hadoop3.2\spark-3.1.2-bin-hadoop3.2
添加环境变量
SPARK_HOME=E:\Programs\spark-3.1.2-bin-hadoop3.2\spark-3.1.2-bin-hadoop3.2
Path 追加 %SPARK_HOME%\bin;
hadoop安装包配置
正常解压配置
将之前从官网下载的 hadoop包,hadoop-3.3.1.tar.gz,解压后,
E:\Programs\hadoop-3.3.1\hadoop-3.3.1
添加环境变量
HADOOP_HOME,指向这个路径
Path 追加 %HADOOP_HOME%\bin;
添加额外库
如果不添加 hadoop.dll 到 windows中,跑spark程序会报 错误 UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows错误
参考这篇博文里的解决办法, ref "报java.lang.UnsatisfiedLinkError错误, 2021/07/04, Joker_Jiang3"
从 https://github.com/4ttty/winutils/tree/master/hadoop-3.0.0/bin 这个链接 下载 hadoop.dll , winutils.exe
hadoop.dll --> %HADOOP_HOME%bin, %HADOOP_HOME%sbin
winutils.exe --> %HADOOP_HOME%bin
注意: 虽然这里 是 3.0.0 版本,与 本地hadoop 3.3.1版本不一致, 但是还是可以用的
创建工程
在IDEA 创建一个java 工程, 这里路径: D:\code\java\projects\idea\Project1
菜单, 文件->项目结构 -> 库, 添加 spark库,
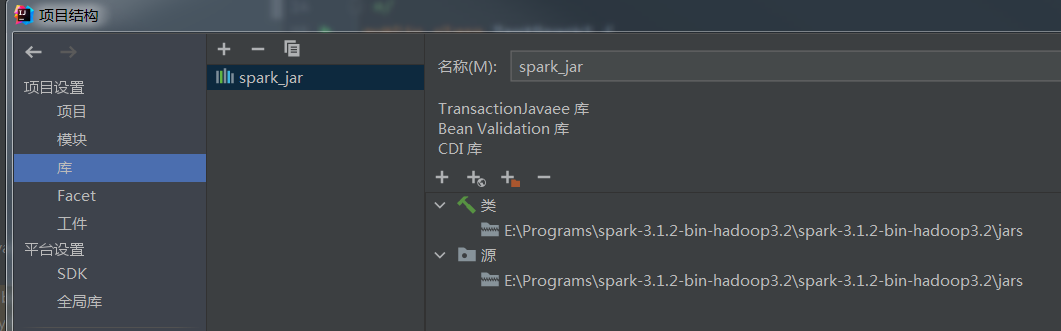
然后在模块的依赖中 添加 这个库
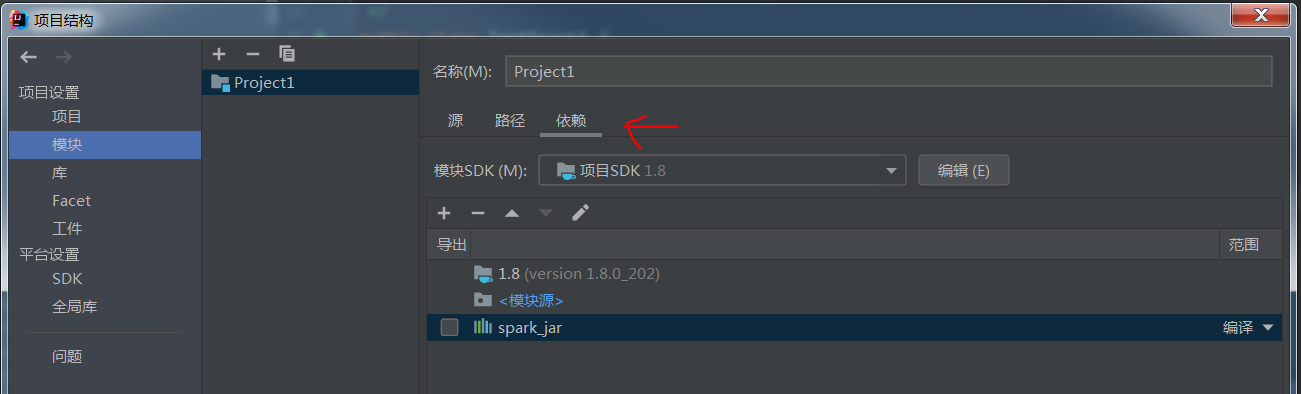
添加成功后

执行测试程序
准备测试程序
TestSpak1.java


import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import scala.Tuple2; import java.util.Arrays; import java.util.List; /** * @Description: spark的WordCount实战 */ public class TestSpark1 { public static void main(String[] args) { //文本文件的hdfs路径 String inputPath = "file:///code/java/projects/idea/data/input/wordcount.txt"; //输出结果文件的hdfs路径 String outputPath = "file:///code/java/projects/idea/data/output/wordcount_out"; SparkConf sparkConf = new SparkConf().setAppName("Spark WordCount Application (java)"); JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf); //导入文件 JavaRDD<String> textFile = javaSparkContext.textFile(inputPath); JavaPairRDD<String, Integer> counts = textFile //每一行都分割成单词,返回后组成一个大集合 .flatMap(s -> Arrays.asList(s.split(" ")).iterator()) //key是单词,value是1 .mapToPair(word -> new Tuple2<>(word, 1)) //基于key进行reduce,逻辑是将value累加 .reduceByKey((a, b) -> a + b); //先将key和value倒过来,再按照key排序 JavaPairRDD<Integer, String> sorts = counts //key和value颠倒,生成新的map .mapToPair(tuple2 -> new Tuple2<>(tuple2._2(), tuple2._1())) //按照key倒排序 .sortByKey(false); //取前10个 List<Tuple2<Integer, String>> top10 = sorts.take(10); //打印出来 for(Tuple2<Integer, String> tuple2 : top10){ System.out.println(tuple2._2() + "\t" + tuple2._1()); } //分区合并成一个,再导出为一个txt保存在hdfs javaSparkContext.parallelize(top10).coalesce(1).saveAsTextFile(outputPath); //关闭context javaSparkContext.close(); } }
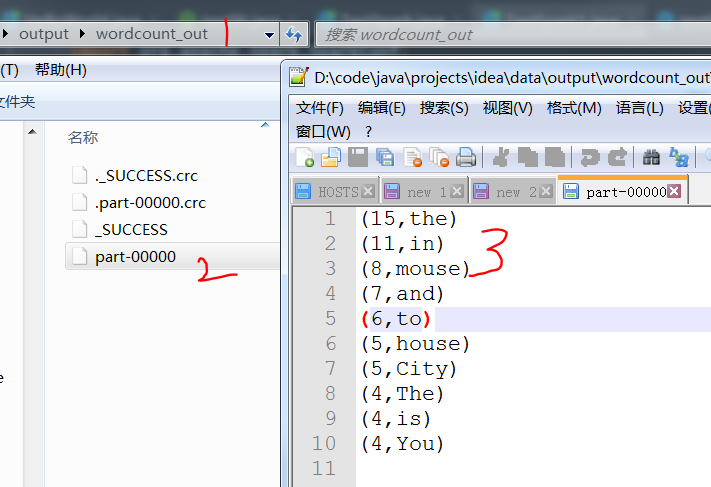
这个一个wordcount程序, 从 windows本地 读取文件,输出到 本地,
注意输出目录 file:///code/java/projects/idea/data/output/wordcount_out , wordcount_out在本地不需要提前创建,
程序执行成功后, 会生成这个目录
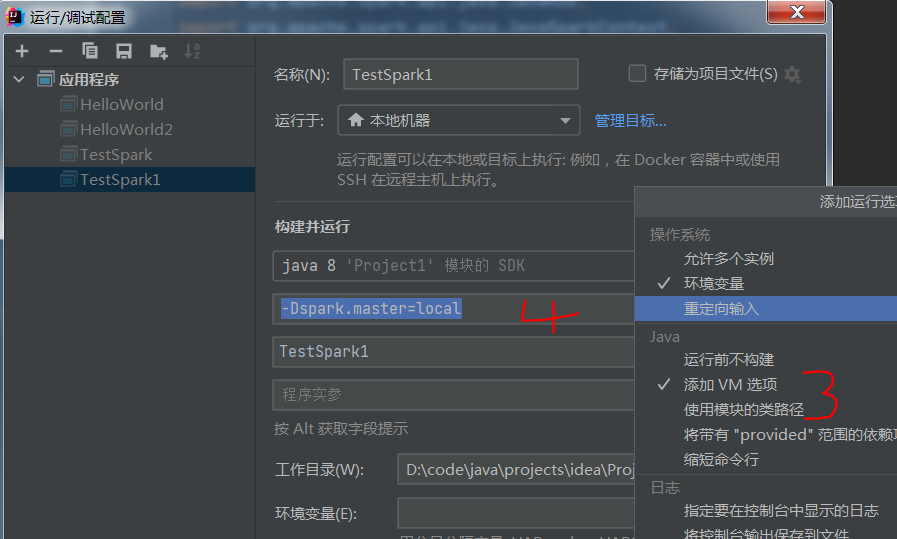
执行前,配置一个地方
菜单 运行->编辑配置 -> 修改选项 -> 添加VM选项, 添加 -Dspark.master.local
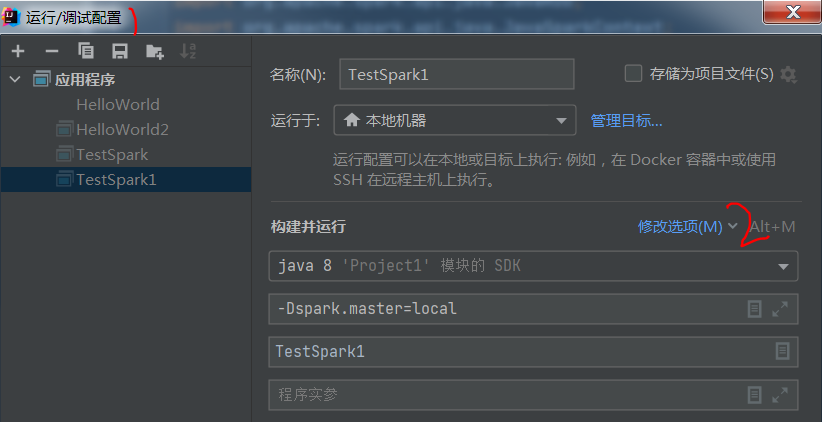
执行
准备一个数据文件,
file:///code/java/projects/idea/data/input/wordcount.txt,存放英文吧
在IDEA 中运行