参考
http://open.163.com/newview/movie/free?pid=M6UTT5U0I&mid=M6V2U1HL4
问题是给定字符串x和y,求出两个当中最长的公共子序列。比如x=abcdef y=acefg,那么他们的最长公共子序列就是acef。就是x的所有的子字符串与y所有的子字符串,如果有相同的,那么就是一个公共子序列,最后求出最长的一个。
建议观看上面的公开课,讲的非常好。本文思路是根据上面的公开课总结实践的。
一
我们先看看求一个字符串的所有子序列,有什么规律。比如给定一个字符串abc,那么有多少子序列呢?a b c ab ac bc abc还有一个空,就是2^3。按照上面公开课讲的非常通俗易懂,就是字符串一共有n个字符,那么每一位的字符都有两个状态----0-不是子序列的一员 1-是子序列的一员。那么总共的种类就是2^n种。这是最坏的情况,字符串中没有相同的字符,如果有,结果会比这个少。但是计算就是这么计算的。
了解了上面,那么我们进一步判断,如果给定一个x的子序列x1,那么怎么判断y中是否含有呢?简单的方法就是从x1的起始位置和y的起始位置开始判断,如果相同,每个索引加一,直到x1/y的字符串判断结束。如果不匹配,那么y索引加一,再从x1的开头开始计算。
这种是穷举法,肯定能得到结果,但是时间和空间都是最差的。我们先实现看看(穷举法排列组合可以参考排列组合)
struct MNODE { string substr; MNODE* pnext; MNODE() { pnext = nullptr; } }; MNODE* msubstr(string& srcstr, int index, int sublen) { MNODE* tmpp = nullptr; MNODE* prep = nullptr; if (index >= sublen && sublen > 0) { if (sublen == 1) { for (int i = 0; i < index; i++) { MNODE* ftpn = nullptr; if (tmpp == nullptr) { tmpp = new MNODE; prep = tmpp; ftpn = tmpp; } else { ftpn = new MNODE; prep->pnext = ftpn; prep = ftpn; } ftpn->substr = srcstr[i]; } } else if (sublen > 1) { MNODE* nsub = msubstr(srcstr, index - 1, sublen - 1); tmpp = nsub; while (nsub != nullptr) { nsub->substr = nsub->substr + srcstr[index - 1]; prep = nsub; nsub = nsub->pnext; } nsub = msubstr(srcstr, index - 1, sublen); prep->pnext = nsub; while (nsub != nullptr) { nsub = nsub->pnext; } } } return tmpp; } bool comps(string& sstr, string& dstr) { int sindex = 0; int dindex = 0; for (int i = sindex; i < sstr.size(); i++) { if (dindex == dstr.size()) { break; } for (int j = dindex; j < dstr.size(); j++) { if (sstr[i] == dstr[j]) { sindex++;
dindex = j + 1; break; } } } if (sindex == sstr.size() && dindex <= dstr.size()) { return true; } return false; } int main() { string a = "abcdef"; string b = "acefg"; for (int i = a.size(); i > 0; i--) { MNODE* psubstr = msubstr(a, a.size(), i); while (psubstr != nullptr) { if (comps(psubstr->substr, b)) { cout << psubstr->substr << endl; } MNODE* tmpp = psubstr; psubstr = tmpp->pnext; delete tmpp; } } char inchar; cin >> inchar; }
根据排列组合的方式获取所有的子串,然后匹配,可以列出所有的公共子串,按照从长倒短打印。
二
那么我们有没有更好的解法呢?按照上面的公开课,我们可以这样计算。LCS(x,y)表示计算x和y的最长公共子串。那么C(i,j)表示当前x的子串从0-i和y的子串从0-j的最长公共子串。那么推导公式就是,如果x[i]=y[j],那么C(i,j) = C(i-1, j-1)+1;如果x[i]!=y[j],那么C(i,j)=max(C(i-1,j),C(i,j-1))。
描述下来就是求x中0-i组成的字符串与y中0-j组成的字符串的最长公共子串,是有两部分推导来的
如果x当前索引的字符串等于y当前索引的字符串,那么最长公共子串就是i-1与j-1的最长公共子串加上当前的字符。这个很好理解,就是已知前面的最长公共子串,如果当前相等,那么加上就好了。
如果不相等呢?我们需要分两步判断,就是先把i-1加一,算一下当前的最长公共子串,再把j-1加一算一下当前的最长公共子串,然后判断哪一个长,就更新哪一个结果。
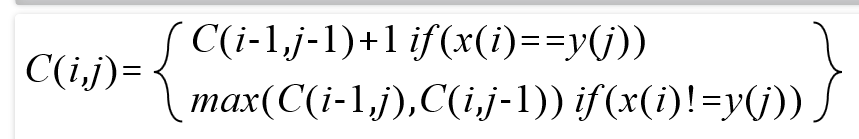
上面就是推导公式。
公开课中对其进行了证明
第一条证明,假设z(1,k)表示C(i,j)的最长公共子串,有k个元素,从1-k,当前x(i)==y(j),那么z(k)==x(i)==y(j)。去掉当前的k,那么LCS(i-1,j-1)就等于z(1,k-1)。对于这个,我们有一个问题,就是必须保证z(1,k-1)是LCS(i-1,j-1),不然我们后面的推论就是错误的,因为如果不是最长公共子串,那么后续的加上1也不是。公开课中用了一个反证法,比如存在w是一个比z(1,k-1)更长的子串,那么|w|(用|w|表示字符串w的长度)一定大于k-1,那么把w拼接上x(i)或y(j),那么|w+x(i)|肯定大于k,这与我们一开始设定的z(1,k)是最长公共子串冲突。所以z(1,k-1)肯定是取出x(i)和y(j)之后剩下的字符串的最长公共子串。同样的方法可以证明第二条定理。
那么动态规划的特征是什么,对于什么样的问题可以使用动态规划呢?
第一条就是存在最优子结构。也就是一个问题的最优解,包含了子问题的最优解。如果子问题不是最优解,那么也不可能是总问题的最优解。
上面的公式最坏的情况是什么?按照公开课说的,就是一直是第二条规则。因为第一条规则,不需要计算,直接加一,索引各加一;第二条规则是只有一个索引加一,还需要分别计算两次。
怎么优化呢?按照公开课讲的,我们可以看一下这个公式有没有什么规律,如果是第一条,那么没什么可以省略的,因为已经很简单了,直接更新数据就好了。如果是第二条呢?举个例子,我们看一下第二步计算的分解
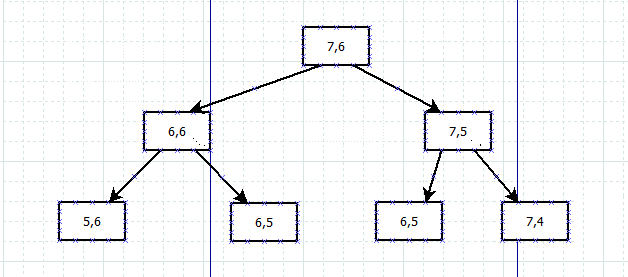
我们没有继续往下分,这里就可以看出,有重复,两个[6,5],计算了两遍,并且还是靠近树的根的位置,就导致重复计算的内容更多,那么如何优化呢?这里大家估计都想到了,就是把一个[6,5]记录下来,到下一个计算的时候,判断一下,如果有,就不再重复计算了,这样就用空间替换了时间,并且是非常可观的,因为记录结果花不了多少空间,但是确实能节省很多时间。
这里就引出了动态规划的第二个特征,重叠子问题。就是我们在计算的过程中,因为分解问题导致会出现重复的子问题,我们可以使用备忘法,就是上面说的,记录一下这个问题的答案,下次碰到直接获取就好了。
但是这样并没有减少太多的运算,因为什么呢?主要还是因为第二个规则,如果x(i)!=y(j),因为我们仅仅能利用i和j相同时的重复计算,但是并不能严格使用i-1和j-1的结果。比如x=abc123kmnp,y=kmnpabc456,那么最长公共子串是kmnp,当我们计算到x和y的c的下一位时,所得的子串并不能通过前面的abc来判断,因为随着不断的遍历,最长公共子串是kmnp而不是abc,并且求kmnp与abc没有任何关系。
这个方法就不实现了,每一小步都是上面的一个穷举法,只不过如果碰到一样的可以减少一次计算。
公开课最后给出了这个问题的最终方法。这个方法在动态规划的题中很多人用到了,可惜没有人给出这种思路出自哪里,如何使用。
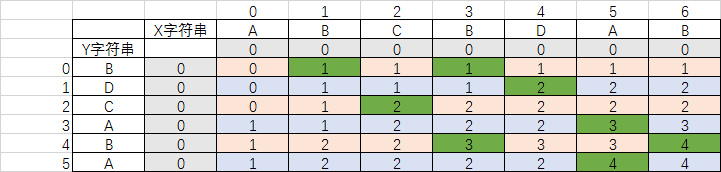
上面是给定的一个例子求ABCBDAB与BDCABA的最长公共子序列。有多个解,比如BCBA和BDAB。看上面的图,我们把两个字符串用一个二维数组表示,每个元素是x(i)与y(j)的对应关系。数组中灰色的是默认填充0,表示的是,x和y字符串对应空字符串的时候,那么肯定都是没有相同的元素。然后我们一行一行的比较(每行颜色我用了淡橙色和淡蓝色区分),第一行对于x(0)和y(0),我们知道A与B不相等,所以他们的相同的子串的个数是0,也就是最长公共字序列是0,也就是空字符串。x(1)与y(0)比较发现B与B是相等的,所以就在上一次计算得出的公共子序列基础上加1(这样我们前面的每次计算都是有用的,没有额外的开销),到了x(2)和y(0),因为C与B不相等,所以当前就等于前面已经求得的公共子序列,也就是1.这里也用到了上面的推导公式,如果相同就加1,不相同就等于LCS(x(i-1),y(j-1))分别加上i和j,求得的两个公共子序列的最大值。那好,到了x(3)和y(0),这时有一个B和B相等,为什么还是1呢?根据公式推导如果x(i)==y(j),那么当前的最长公共子串等于LCS(x(i-1),y(j-1))+1,因为要退两个,也就是x(2)和y(-1),是0,所以LCS(x(3),y(0))还是1.从图标中可以看出,如果相等,那么就是左上角顶格的数字加一,如果不等,就是前一格或是上一格的最大值。前一格就是LCS(x(i-1), y(j)),上一格就是LCS(x(i), y(j-1));同样相等的话就是左上角的加一,左上角就是LCS(x(i-1),y(j-1))。真是完美的解决方案,非常形象,也很好理解,也很好记。把数学和几何完美的结合在一起。那么最长公共子串怎么求呢?很简单,一行一行的扫描或是一排一排的扫描,在上一次结果所在的i,j位置往后,第一次数字增加的地方就是公共子串的位置,为了求最长的公共子串,我们可以得到最大的数值,然后逆向操作,第一次数字减少的地方就是公共子串的元素。
上面的递归的方法用的是自顶向下的逻辑,这个方法用的是自底向上的逻辑
void lcs() { string a = "abc123kmnp"; string b = "kmnpabc456"; int* lcsmap = new int[a.size() * b.size()](); int maxnum = 0; int maxi = 0; int maxj = 0; for (int j = 0; j < b.size(); j++) { for (int i = 0; i < a.size(); i++) { if (a[i] == b[j]) { if (i > 0 && j > 0) { *(lcsmap + a.size() * i + j) = *(lcsmap + a.size() * (i - 1) + j - 1) + 1; } else { *(lcsmap + a.size() * i + j) = 1; } } else { if (i > 0 && j > 0) { *(lcsmap + a.size() * i + j) = max((*(lcsmap + a.size() * (i - 1) + j)), (*(lcsmap + a.size() * i + j - 1))); } else if (i > 0) { *(lcsmap + a.size() * i + j) = *(lcsmap + a.size() * (i - 1) + j); } else if (j > 0) { *(lcsmap + a.size() * i + j) = *(lcsmap + a.size() * i + j - 1); } } if (*(lcsmap + a.size() * i + j) > maxnum) { maxnum = *(lcsmap + a.size() * i + j); maxi = i; maxj = j; } } } string slcs; for (int j = maxj; j >= 0; j--) { for (int i = maxi; i >= 0; i--) { if (a[i] == b[j] && *(lcsmap + a.size() * i + j) == maxnum) { maxi = i; maxnum--; slcs = a[i] + slcs; break; } } } cout << slcs; }