前言
以下内容是个人学习之后的感悟,转载请注明出处~
Batch归一化
在神经网络中,我们常常会遇到梯度消失的情况,比如下图中的sigmod激活函数,当离零点很远时,梯度基本为0。为了
解决这个问题,我们可以采用Batch归一化。
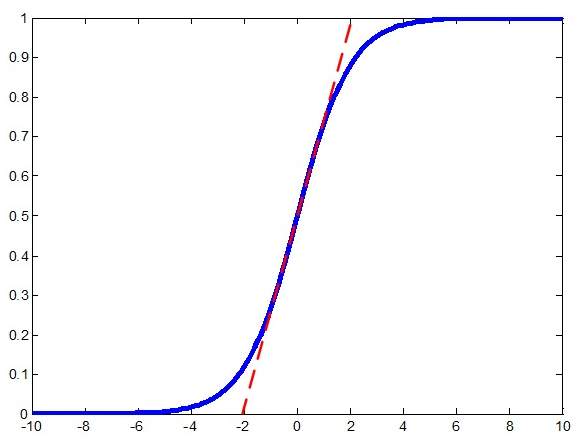
通过BN法,我们将每层的激活值都进行归一化,将它们拉到均值为0、方差为1的区域,这样大部分数据都从梯度趋于0变
换到中间梯度较大的区域,如上图中红线所示,从而解决梯度消失的问题。但是做完归一化后,函数近似于一个线性函数,多
层网络相当于一层,这不是我们想要的效果,故又加入了两个参数γ、β,整体步骤如下所示:
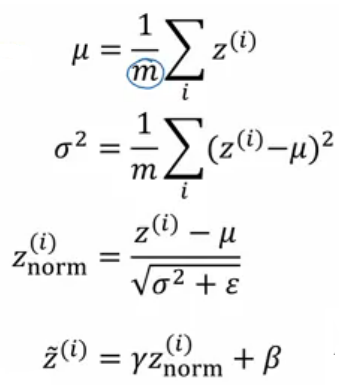
参数的加入固然可以解决问题,但是如何求解参数又增加了任务量。求法很简单,和求Wx+b中的W、b参数一样,不断
迭代减去代价函数对于Υ、β的倒数。
此算法的优势:
(1) 可以使用更高的学习率。如果每层的scale不一致,实际上每层需要的学习率是不一样的,同一层不同维度的scale往往也需
要不同大小的学习率,通常需要使用最小的那个学习率才能保证损失函数有效下降,Batch Normalization将每层、每维的scale
保持一致,那么我们就可以直接使用较高的学习率进行优化。
(2) 移除或使用较低的dropout。 dropout是常用的防止overfitting的方法,而导致overfit的位置往往在数据边界处,如果初始化权重
就已经落在数据内部,overfit现象就可以得到一定的缓解。论文中最后的模型分别使用10%、5%和0%的dropout训练模型,与之前
的40%-50%相比,可以大大提高训练速度。
(3) 降低L2权重衰减系数。 还是一样的问题,边界处的局部最优往往有几维的权重(斜率)较大,使用L2衰减可以缓解这一问题,
现在用了Batch Normalization,就可以把这个值降低了,论文中降低为原来的5倍。
(4) 取消Local Response Normalization层。 由于使用了一种Normalization,再使用LRN就显得没那么必要了。而且LRN实际上
也没那么work。
(5) 减少图像扭曲的使用。 由于现在训练epoch数降低,所以要对输入数据少做一些扭曲,让神经网络多看看真实的数据。
以上是全部内容,如果有什么地方不对,请在下面留言,谢谢~