Spark SQL主要提供了两个工具来访问hive中的数据,即CLI和ThriftServer。前提是需要Spark支持Hive,即编译Spark时需要带上hive和hive-thriftserver选项,同时需要确保在$SPARK_HOME/conf目录下有hive-site.xml配置文件(可以从hive中拷贝过来)。在该配置文件中主要是配置hive metastore的URI(Spark的CLI和ThriftServer都需要)以及ThriftServer相关配置项(如hive.server2.thrift.bind.host、hive.server2.thrift.port等)。注意如果该台机器上同时运行有Hive ThriftServer和Spark ThriftServer,则hive中的hive.server2.thrift.port配置的端口与spark中的hive.server2.thrift.port配置的端口要不一样,避免同时启动时发生端口冲突。
启动CLI和ThriftServer之前都需要先启动hive metastore。执行如下命令启动:
[root@BruceCentOS ~]# nohup hive --service metastore &
成功启动后,会出现一个RunJar的进程,同时会监听端口9083(hive metastore的默认端口)。


先来看CLI,通过spark-sql脚本来使用CLI。执行如下命令:
[root@BruceCentOS4 spark]# $SPARK_HOME/bin/spark-sql --master yarn
上述命令执行后会启动一个yarn client模式的Spark程序,如下图所示:

同时它会连接到hive metastore,可以在随后出现的spark-sql>提示符下运行hive sql语句,比如:

其中每输入并执行一个SQL语句相当于执行了一个Spark的Job,如图所示:

也就是说执行spark-sql脚本会启动一个yarn clien模式的Spark Application,而后出现spark-sql>提示符,在提示符下的每个SQL语句都会在Spark中执行一个Job,但是对应的都是同一个Application。这个Application会一直运行,可以持续输入SQL语句执行Job,直到输入“quit;”,然后就会退出spark-sql,即Spark Application执行完毕。
另外一种更好地使用Spark SQL的方法是通过ThriftServer,首先需要启动Spark的ThriftServer,然后通过Spark下的beeline或者自行编写程序通过JDBC方式使用Spark SQL。
通过如下命令启动Spark ThriftServer:
[root@BruceCentOS4 spark]# $SPARK_HOME/sbin/start-thriftserver.sh --master yarn
执行上面的命令后,会生成一个SparkSubmit进程,实际上是启动一个yarn client模式的Spark Application,如下图所示:

而且它提供一个JDBC/ODBC接口,用户可以通过JDBC/ODBC接口连接ThriftServer来访问Spark SQL的数据。具体可以通过Spark提供的beeline或者在程序中使用JDBC连接ThriftServer。例如在启动Spark ThriftServer后,可以通过如下命令使用beeline来访问Spark SQL的数据。
[root@BruceCentOS3 spark]# $SPARK_HOME/bin/beeline -n root -u jdbc:hive2://BruceCentOS4.Hadoop:10003
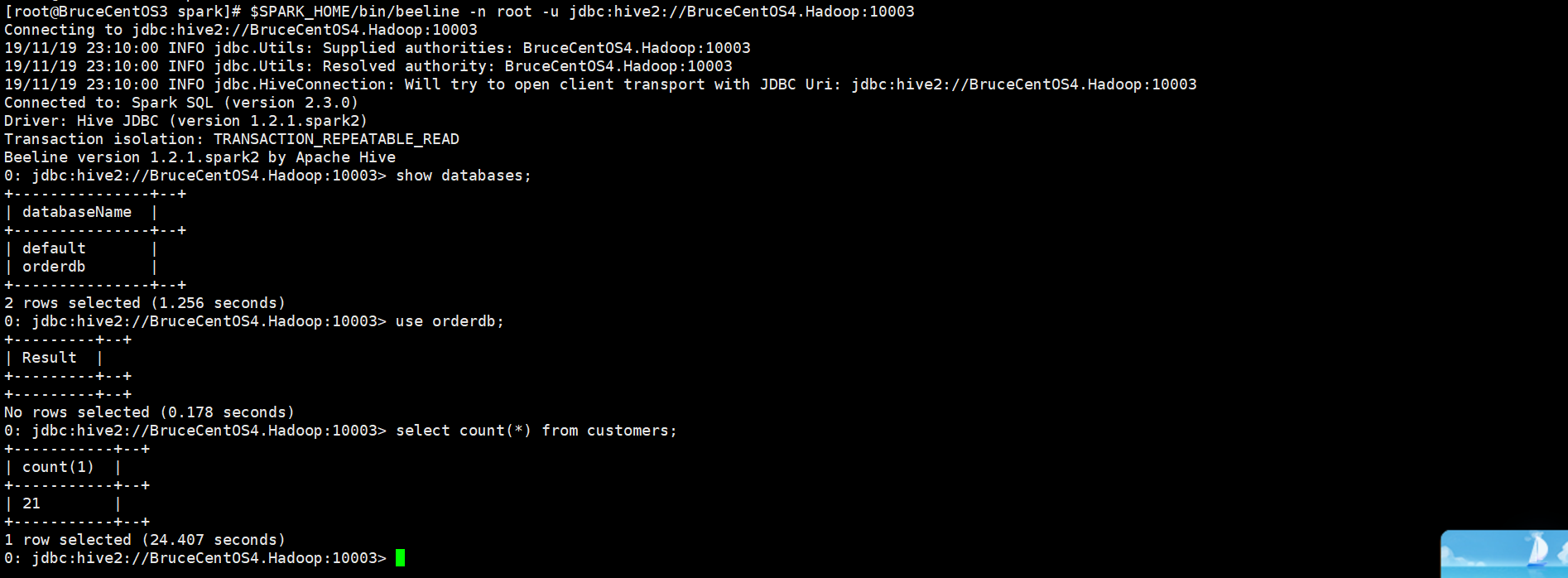
上述beeline连接到了BruceCentOS4上的10003端口,也就是Spark ThriftServer。所有连接到ThriftServer的客户端beeline或者JDBC程序共享同一个Spark Application,通过beeline或者JDBC程序执行SQL相当于向这个Application提交并执行一个Job。在提示符下输入“!exit”命令可以退出beeline。
最后,如果要停止ThriftServer(即停止Spark Application),需要执行如下命令:
[root@BruceCentOS4 spark]# $SPARK_HOME/sbin/stop-thriftserver.sh

综上所述,在Spark SQL的CLI和ThriftServer中,比较推荐使用后者,因为后者更加轻量,只需要启动一个ThriftServer(对应一个Spark Application)就可以给多个beeline客户端或者JDBC程序客户端使用SQL,而前者启动一个CLI就启动了一个Spark Application,它只能给一个用户使用。