1. 普通查询的用法
org.apache.lucene.search.IndexSearcher
public void search(Query query, Collector results)
其中
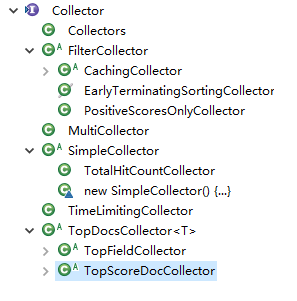
Collector定义
/**
* <p>Expert: Collectors are primarily meant to be used to
* gather raw results from a search, and implement sorting
* or custom result filtering, collation, etc. </p>
*
* <p>Lucene's core collectors are derived from {@link Collector}
* and {@link SimpleCollector}. Likely your application can
* use one of these classes, or subclass {@link TopDocsCollector},
* instead of implementing Collector directly:
*
* <ul>
*
* <li>{@link TopDocsCollector} is an abstract base class
* that assumes you will retrieve the top N docs,
* according to some criteria, after collection is
* done. </li>
*
* <li>{@link TopScoreDocCollector} is a concrete subclass
* {@link TopDocsCollector} and sorts according to score +
* docID. This is used internally by the {@link
* IndexSearcher} search methods that do not take an
* explicit {@link Sort}. It is likely the most frequently
* used collector.</li>
*
* <li>{@link TopFieldCollector} subclasses {@link
* TopDocsCollector} and sorts according to a specified
* {@link Sort} object (sort by field). This is used
* internally by the {@link IndexSearcher} search methods
* that take an explicit {@link Sort}.
*
* <li>{@link TimeLimitingCollector}, which wraps any other
* Collector and aborts the search if it's taken too much
* time.</li>
*
* <li>{@link PositiveScoresOnlyCollector} wraps any other
* Collector and prevents collection of hits whose score
* is <= 0.0</li>
*
* </ul>
*
* @lucene.experimental
*/
Collector的层次结构
2 lucene-group
提供了分组查询GroupingSearch,对应相应的collector
3.实例:
public Map<String, Integer> groupBy(Query query, String field, int topCount) { Map<String, Integer> map = new HashMap<String, Integer>(); long begin = System.currentTimeMillis(); int topNGroups = topCount; int groupOffset = 0; int maxDocsPerGroup = 100; int withinGroupOffset = 0; try { FirstPassGroupingCollector c1 = new FirstPassGroupingCollector(field, Sort.RELEVANCE, topNGroups); boolean cacheScores = true; double maxCacheRAMMB = 4.0; CachingCollector cachedCollector = CachingCollector.create(c1, cacheScores, maxCacheRAMMB); indexSearcher.search(query, cachedCollector); Collection<SearchGroup<String>> topGroups = c1.getTopGroups(groupOffset, true); if (topGroups == null) { return null; } SecondPassGroupingCollector c2 = new SecondPassGroupingCollector(field, topGroups, Sort.RELEVANCE, Sort.RELEVANCE, maxDocsPerGroup, true, true, true); if (cachedCollector.isCached()) { // Cache fit within maxCacheRAMMB, so we can replay it: cachedCollector.replay(c2); } else { // Cache was too large; must re-execute query: indexSearcher.search(query, c2); } TopGroups<String> tg = c2.getTopGroups(withinGroupOffset); GroupDocs<String>[] gds = tg.groups; for(GroupDocs<String> gd : gds) { map.put(gd.groupValue, gd.totalHits); } } catch (IOException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("group by time :" + (end - begin) + "ms"); return map; }
几个参数说明:
groupField: 分组域groupSort: 分组排序topNGroups: 最大分组数groupOffset: 分组分页用withinGroupSort: 组内结果排序maxDocsPerGroup: 每个分组的最多结果数withinGroupOffset: 组内分页用
参考资料
https://blog.csdn.net/wyyl1/article/details/7388241