一、 准备资源
1) DOM4J 的 jar 包
2) Jaxen 的 jar 包
3) Xpath 中文文档
1 <?xml version="1.0" encoding="UTF-8"?> 2 <books> 3 <book id="1001"> 4 <name>软件工程</name> 5 <author>王一一</author> 6 <price>66</price> 7 </book> 8 <book id="1002"> 9 <name>计算机网络</name> 10 <author>乔二二</author> 11 <price>89</price> 12 </book> 13 </books>
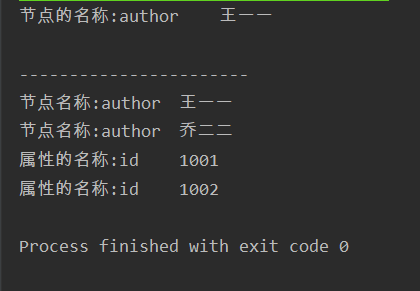
1 import java.util.List; 2 3 import org.dom4j.Attribute; 4 import org.dom4j.Document; 5 import org.dom4j.DocumentException; 6 import org.dom4j.Node; 7 import org.dom4j.io.SAXReader; 8 9 public class Test { 10 public static void main(String[] args) throws DocumentException { 11 //(1)SAXReader对象 12 SAXReader reader=new SAXReader(); 13 //(2)读取XML文件 14 Document doc=reader.read("book.xml"); 15 //得到第一个author节点 16 Node node=doc.selectSingleNode("//author"); 17 System.out.println("节点的名称:"+node.getName()+" "+node.getText()); 18 //获取所有的author 19 System.out.println(" -----------------------"); 20 List<Node> list=doc.selectNodes("//author"); 21 for (Node n : list) { 22 System.out.println("节点名称:"+n.getName()+" "+n.getText()); 23 } 24 //选择有id属性的book元素 25 List<Attribute> attList=doc.selectNodes("//book/@id"); 26 for (Attribute att : attList) { 27 System.out.println("属性的名称:"+att.getName()+" "+att.getText()); 28 } 29 } 30 }