1.设计动机与目标
Bigtable的设计动机:
(1)需要存储的数据种类繁多
包括URL、网页内容、用户的个性化设置在内的数据都是Google需要经常处理的
(2)海量的服务请求
Google运行着目前世界上最繁忙的系统,它每时每刻处理的客户服务请求数量是普通的系统根本无法承受的
(3)商用数据库无法满足需求
一方面现有商用数据库的设计着眼点在于其通用性。
另一方面对于底层系统的完全掌控会给后期的系统维护、升级带来极大的便利。
Bigtable应达到的基本目标:
(1)广泛的适用性
Bigtable是为了满足一系列Google产品而并非特定产品的存储要求。
(2)很强的可扩展性
根 据 需要随 时可以 加入 或撤销 服务 器
(3)高可用性
确保几乎所有的情况下系统都可用
(4)简单性
底层系统的简单性既可以减少系统出错的概率 ,也为上层应用的开发带来便利
2.数据模型
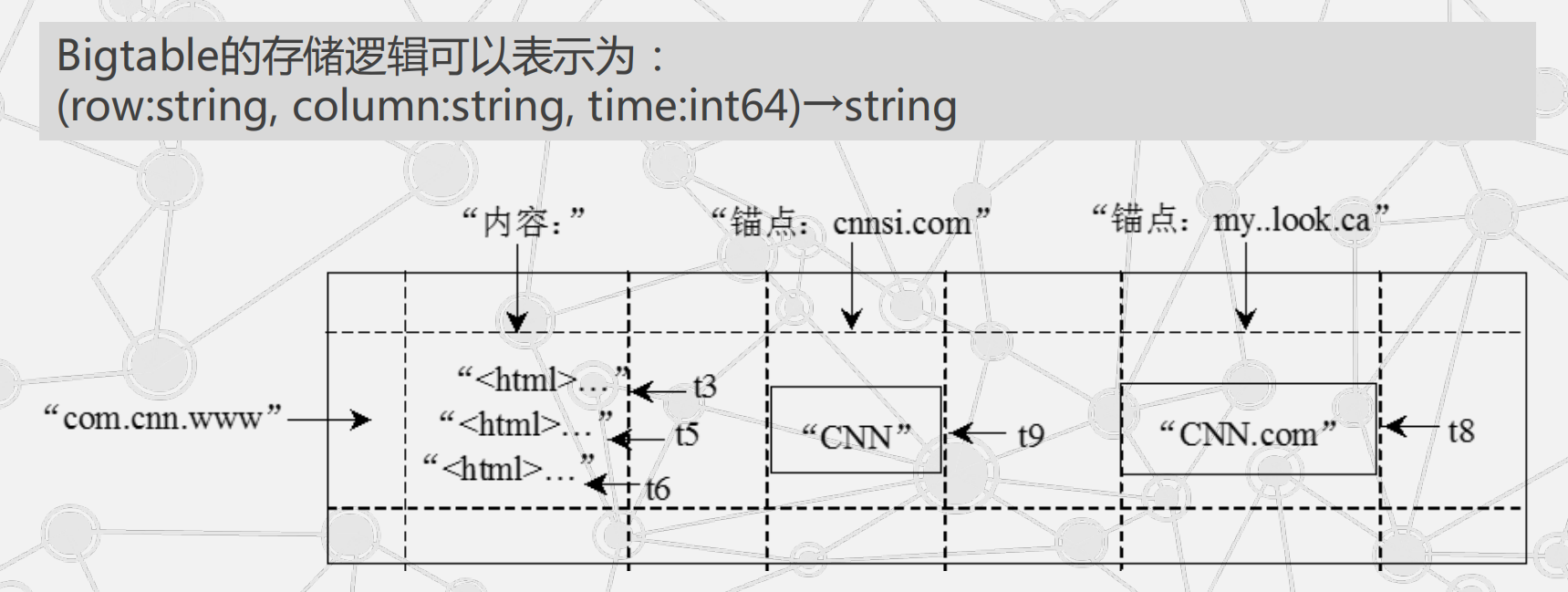
Bigtable是一个分布式多维映射表,表中的数据通过一个行关键字(Row Key)、一个列关键字(Column Key)以及一个时间戳(Time Stamp)进行索引
行:

Bigtable的行关键字可以是任意的字符串,但是大小不能够超过64KB
表中数据都是根据行关键字进行排序的,排序使用的是词典序
同一地址域的网页会被存储在表中的连续位置
倒排便于数据压缩,可以大幅提高压缩率
列:
将其组织成所谓的列族(Column Family)
族名必须有意义,限定词则可以任意选定
组织的数据结构清晰明了,含义也很清楚
族同时也是Bigtable中访问控制(Access Control)的基本单元
时间戳:
Google的很多服务比如网页检索和用户的个性化设置等都需要保存不同时间的数据,这些不同的数据版本必须通过时间戳来区分。
Bigtable中的时间戳是64位整型数,具体的赋值方式可以用户自行定义
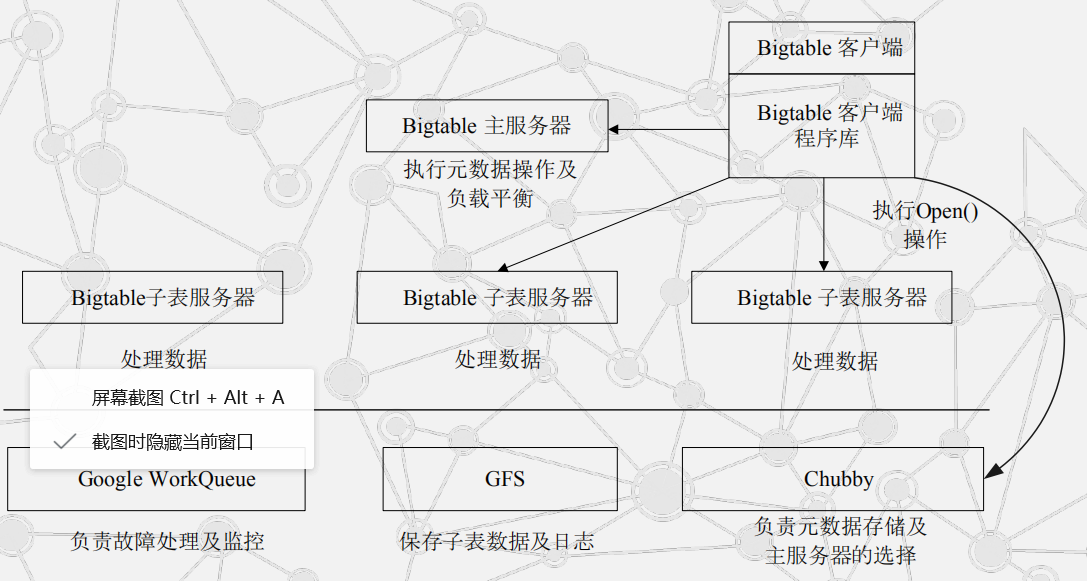
3.Bigtable的系统架构
Bigtable的基本架构:
Bigtable中Chubby的主要作用:
(1)选取并保证 同一时 间内 只有一 个主服务器( Master Server )。
(2)获取子表的位置信息。
(3)保存Bigtable的模式信息及访问控制列表。
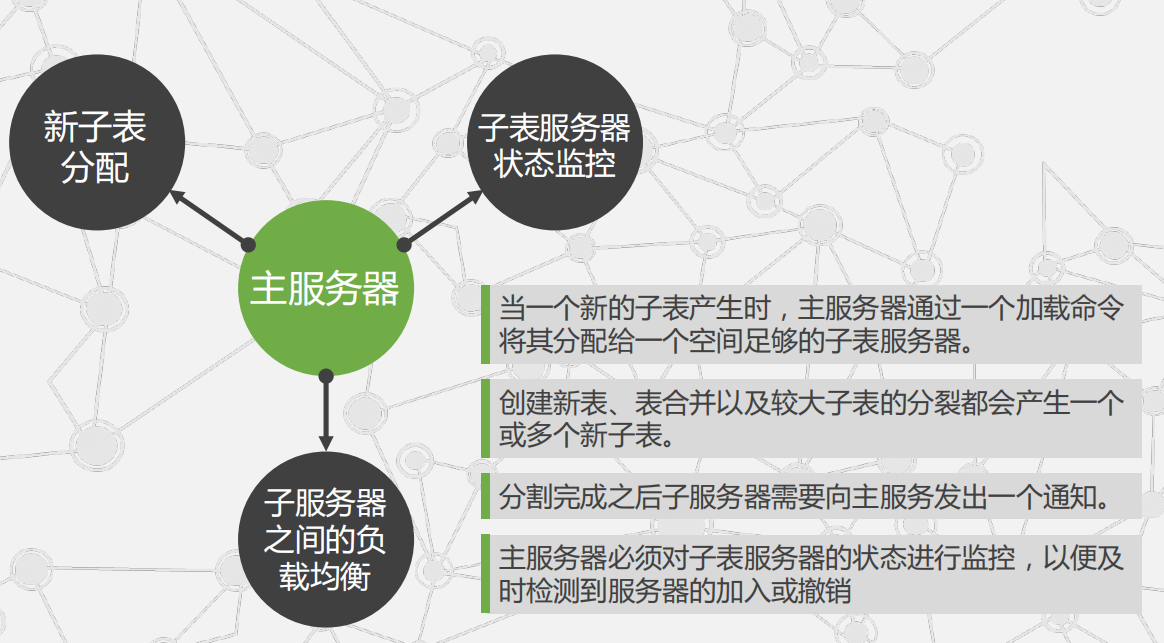
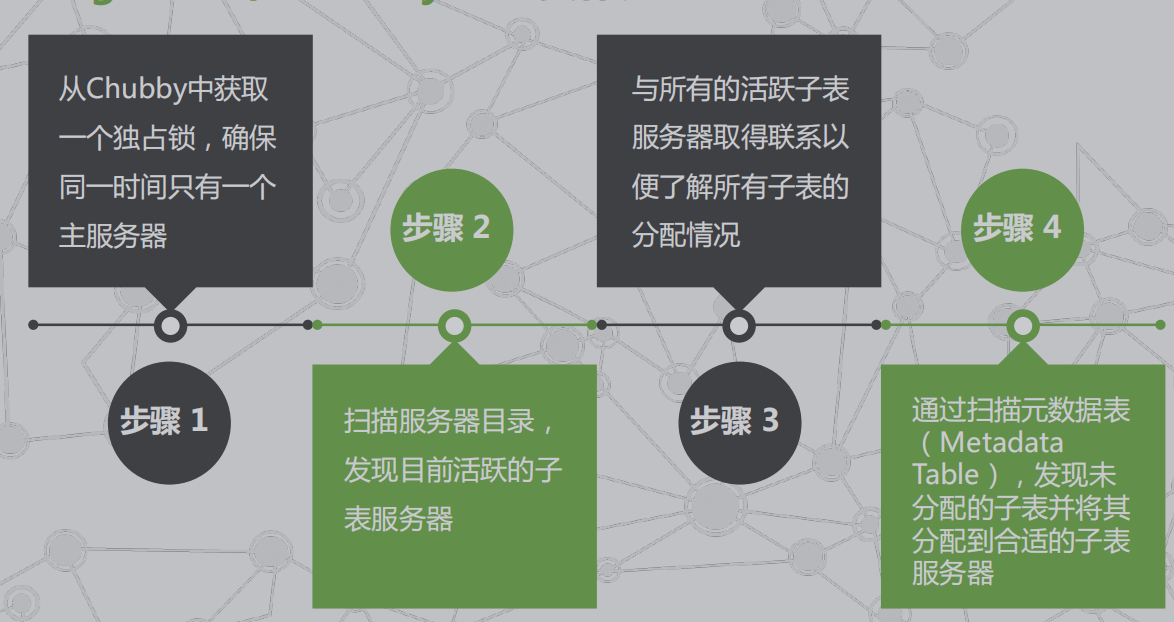
4.Bigtable的主服务器
5.Bigtable的子表服务器
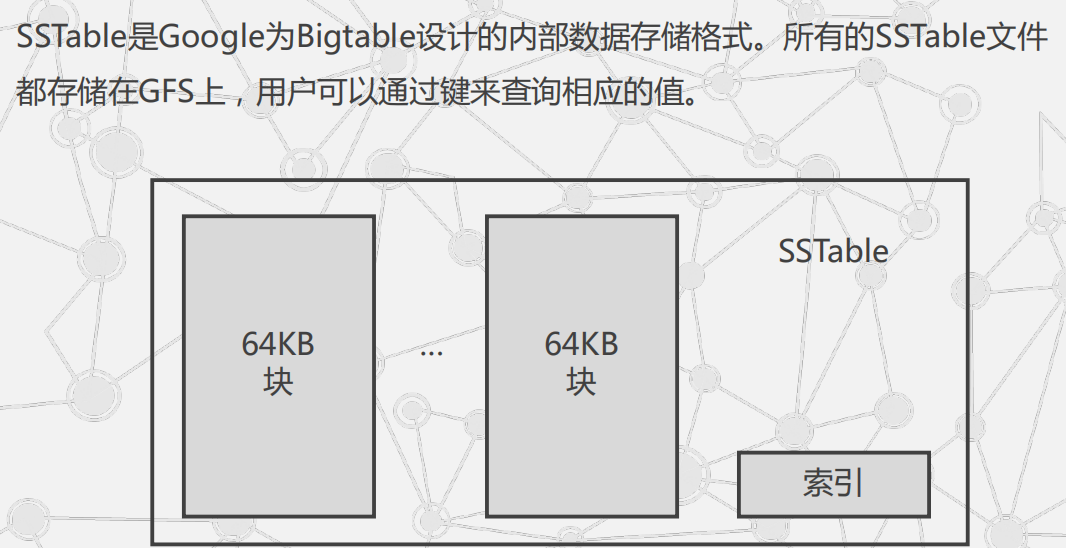
SSTable格式示意图:
不同子表的SSTable可以共享
每个子表服务器上仅保存一个日志文件
Bigtable规定将日志的内容按照键值进行排序
每个子表服务器上保存的子表数量可以从几十到上千不等,通常情况下是100个左右
子表服务器的实际组成:
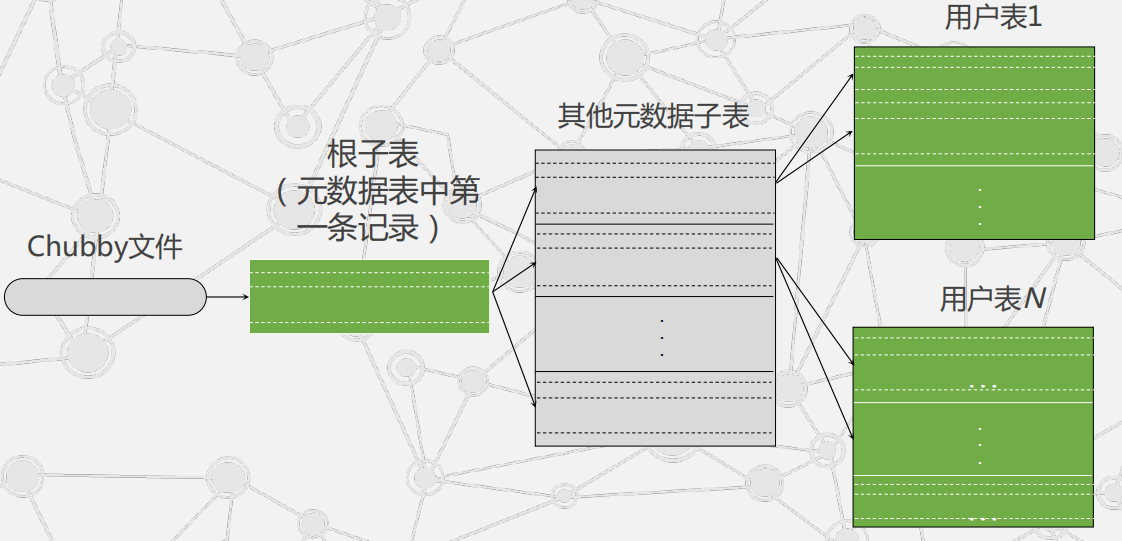
子表地址组成:
Bigtable系统的内部采用的是一种类似B+树的三层查询体系
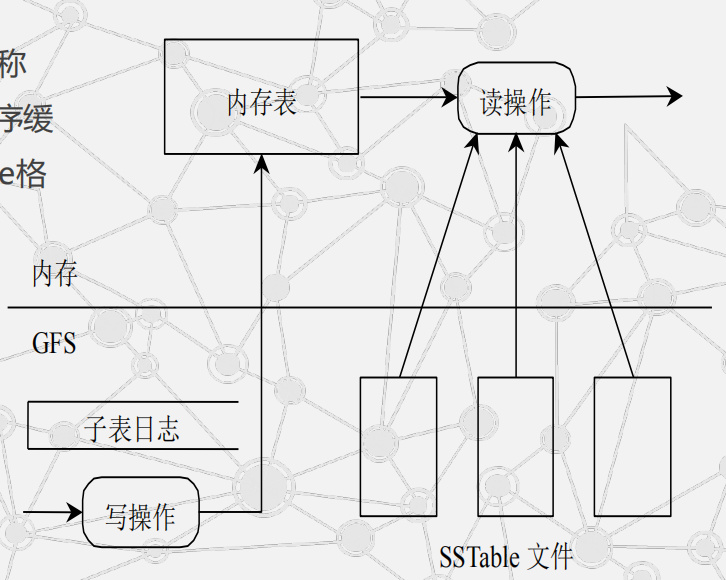
BigTable的数据存储:
较新的数据存储在内存中一个称为内存表(Memtable)的有序缓冲里,较早的数据则以SSTable格式保存在GFS中。
BigTable的读写操作:
读和写操作有很大的差异性
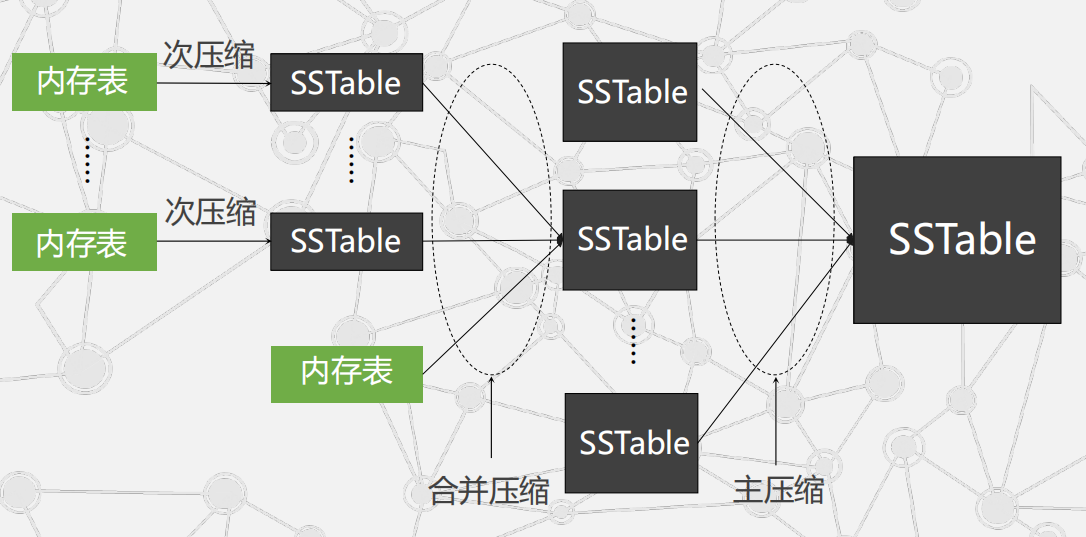
三种形式压缩之间的关系:
6.Bigtable的性能优化
(1)局部性群组 (2)压缩(3)布隆过滤器