1.英文
#读取
with open('steve.txt','r',encoding='utf-8')as f:
novel = f.read()
#清洗数据
sep = " .!@#%&*;:',.?/_“’”"
for ch in sep:
novel=novel.replace(ch,' ')
#字母换成小写
novel = novel.lower()
strnovel = novel.split()
print(strnovel,len(strnovel))
#分词后转为集合
strset = set(strnovel)
noMean = {'is','and','a','this','the','a','in','at','on','to','s','his','3','1983'}
strset = strset - noMean
print(strset,len(strset))
#将集合中词统计出现次数
strdict={}
for word in strset:
strdict[word] = strnovel.count(word)
print(strdict,len(strdict))
wordlist = list(strdict.items())
#排序
wordlist.sort(key=lambda x:x[1],reverse=True)
print(wordlist)
#输入TOP20
for i in range(20):
print(wordlist[i])

2.中文小说
#-*- coding:utf-8 -*-
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
with open('doupo.txt','r',encoding='utf-8') as f:
doupo = f.read()
#清洗
sep = " ,.?;:'!*#-_"
for quchu in sep:
doupo = doupo.replace(quchu,' ')
#分词
wordList = jieba.cut(doupo)
print(type(wordList))
#词频分析
data={}
for word in wordList:
if len(word) == 1:
continue
else:data[word] = data.get(word,0)+1
result = list(data.items())
result.sort(key=lambda x:x[1],reverse=True)
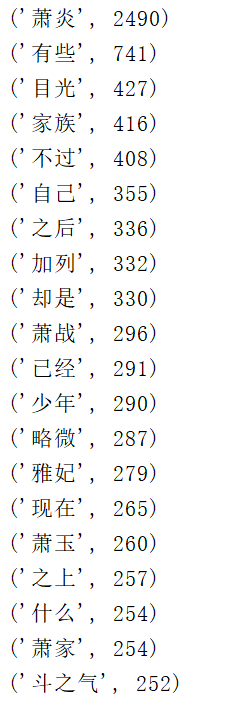
for top_20 in range(20):
print(result[top_20])
wordSplit = " ".join(dict(result))
wc = WordCloud(background_color="black", # 设置背景颜色
# mask = "图片", #设置背景图片
max_words=2000, # 设置最大显示的字数
# stopwords = "", #设置停用词
font_path="C:\Windows\Fonts\NotoSansHans-Black_0.otf",
# 设置中文字体,使得词云可以显示(词云默认字体是“DroidSansMono.ttf字体库”,不支持中文)
max_font_size=40,
# 设置字体最大值
random_state=30, # 设置有多少种随机生成状态,即有多少种配色方案
)
mywc = wc.generate(wordSplit) # 生成词云
# 展示词云图
plt.imshow(mywc)
plt.axis("off")
plt.show()
wc.to_file('myword.jpg') # 保存图片文件