Introduction
本文设计了Frame-Guided Region-Aligned model(FGRA)。模型结构包含两个分支:全局分支和局部分支。全局分支用来提取全局的特征,局部分支再细分为区域对齐机制和特征聚合策略。FGRA可以对视频的每一帧的区域进行对齐,在遇到类似下图的姿态、尺寸失调的情况也能够提取出鲁棒的时空线索。

Proposed Method
(1)问题定义:
假定一个probe视频序列为:![]() ,其中N为视频序列的长度,D为图像的维度;gallery视频序列为:
,其中N为视频序列的长度,D为图像的维度;gallery视频序列为:![]() 。
。
(2)框架概述:
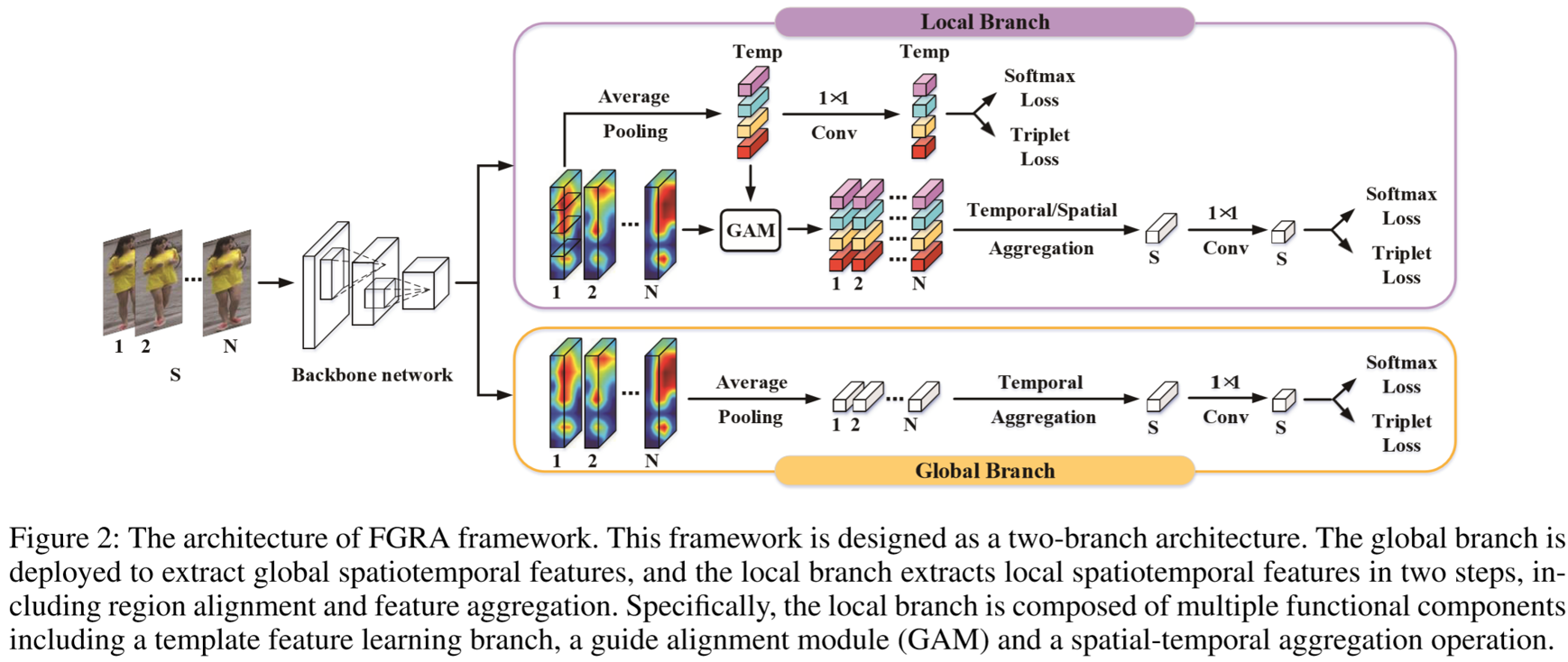
输入视频序列![]() 到骨干网络中,提取出帧级特征
到骨干网络中,提取出帧级特征![]()
![]() ,随后分别通过两个分支提取到全局特征和局部特征
,随后分别通过两个分支提取到全局特征和局部特征![]() 。
。
全局特征提取模块:对所有帧级特征进行平均池化,将特征压缩到通道维度,再采用时间注意力机制对各帧进行加权平均,最后用1*1卷积压缩到1024维度的视频级全局特征。
局部特征提取模块:采用了区域对齐机制和特征聚合策略,提取得到的局部特征划分为:![]() ,其中
,其中![]() 为划分的区域数量。将区域特征
为划分的区域数量。将区域特征![]() 和帧级特征
和帧级特征![]() 放入Guide Alignment Module(GAM)中得到区域对齐后的特征
放入Guide Alignment Module(GAM)中得到区域对齐后的特征![]() ,最后通过时空注意力机制等得到视频级局部特征。
,最后通过时空注意力机制等得到视频级局部特征。
(3)区域对齐机制:
可以解决两个问题:对齐行人的身体区域;判断哪部分区域包含更多的信息。
① 时间特征学习:每一帧的上一帧都能提供信息线索,本模块把第一帧作为参考帧,并将其通过平均池化转为若干个特征向量![]() 。通过1*1卷积进行降维。
。通过1*1卷积进行降维。
② 引导对齐模块(GAM):
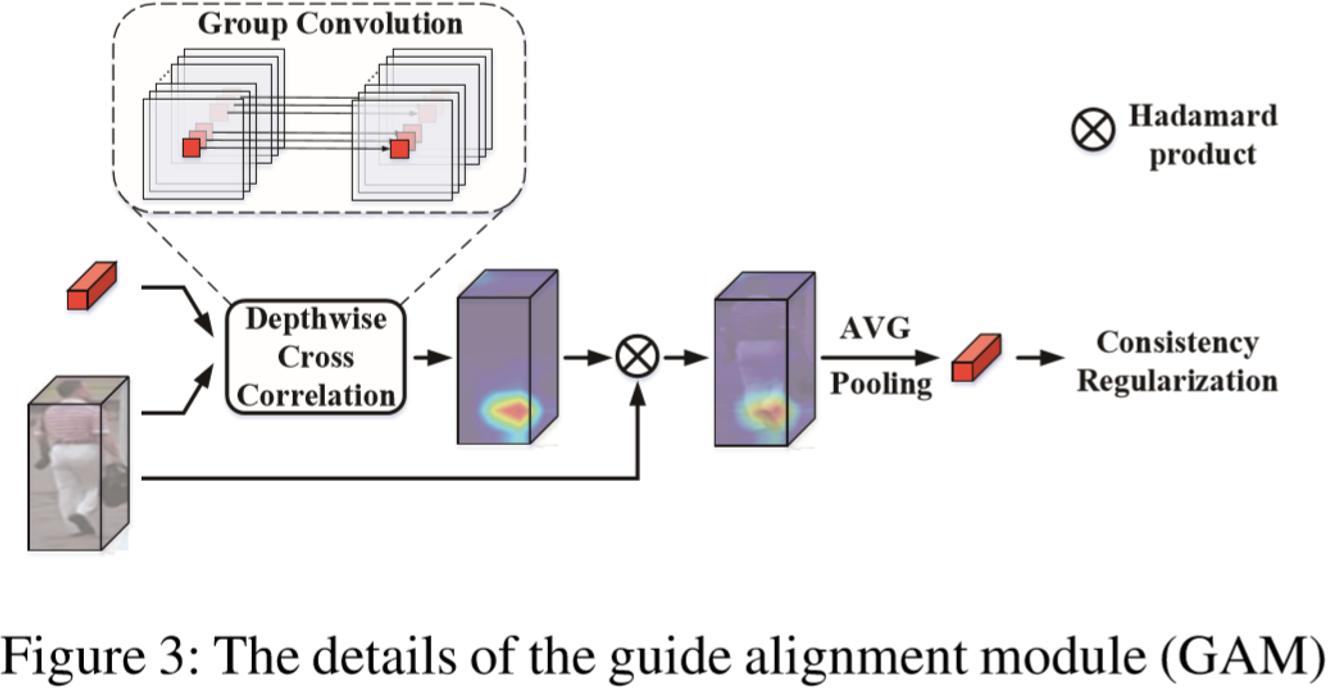
输入一个局部特征向量![]() 和单帧的特征向量
和单帧的特征向量![]() ,进行交叉计算求各个像素区域的相似度映射
,进行交叉计算求各个像素区域的相似度映射![]() ,计算如下:
,计算如下:![]() ,其中 * 可以视为组卷积,而
,其中 * 可以视为组卷积,而![]() 可以视为卷积核(计算方法为:depth-wise cross correlation)。再采用BN层和Sigmoid函数将元素单位化,最终采用Hadamard积获得该区域的局部特征
可以视为卷积核(计算方法为:depth-wise cross correlation)。再采用BN层和Sigmoid函数将元素单位化,最终采用Hadamard积获得该区域的局部特征![]() ,计算为:
,计算为:![]() 。
。
③ 一致性正则化(Consistency Regularization):采用了中心损失来保证对齐的一致性,具体为: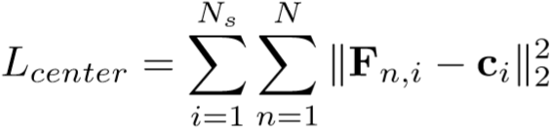 ,其中
,其中![]() 为N帧的局部特征
为N帧的局部特征![]() 的平均值。
的平均值。
(4)特征聚合策略:
通过上述步骤已经获得了对齐的局部特征,通过时空注意力机制将一个视频序列![]() 映射为了视频级局部特征
映射为了视频级局部特征![]() 。
。
① 时间对齐得分:计算每一帧所需要占的权重,它反映了对齐的特征包含了多少的信息量,计算为:![]() ,再采用Sigmoid函数:
,再采用Sigmoid函数: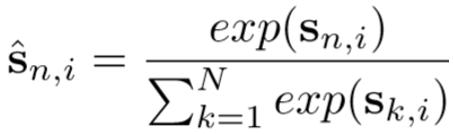 ,最后在时间维度进行加权,即:
,最后在时间维度进行加权,即:![]() 。
。
② 空间注意力特征学习:通过时间对齐得分的加权,得到了不同区域的局部特征![]() ,将其进行concat连接为
,将其进行concat连接为![]() ,传入卷积层生成空间注意力权重,即:
,传入卷积层生成空间注意力权重,即:![]() ,函数g(.)包含了一个1D卷积层、BN层、ReLU层。最后计算视频级局部特征为:
,函数g(.)包含了一个1D卷积层、BN层、ReLU层。最后计算视频级局部特征为:![]() 。
。
③ 全局、局部特征融合:![]() 。
。
(5)目标函数:
采用Softmax损失和三元组损失,具体如下:
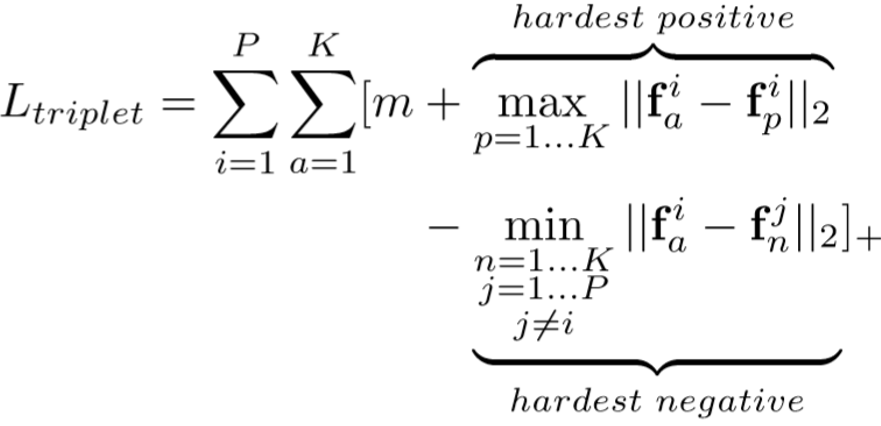
![]()
结合了一致性正规化项:
![]()
目标函数为:
![]()
Experiments
(1)实验设置:
① 数据集设置:iLIDS-VID,PRID-2011,MARS;
② 实验细节与参数设置:视频帧的长度 N = 6,采用随机抽取的方式;输入的帧大小为256*128,采用随机缩放、镜像翻转、随机擦除等数据增强技巧;mini-batch大小为64,其中为16个ID各4个视频段;分块大小为4块;三元组损失的边界参数为0.5;采用Adam优化器,weight decay 为0.0005;训练迭代次数为300次;学习率为0.03,每100次下降为0.1倍。
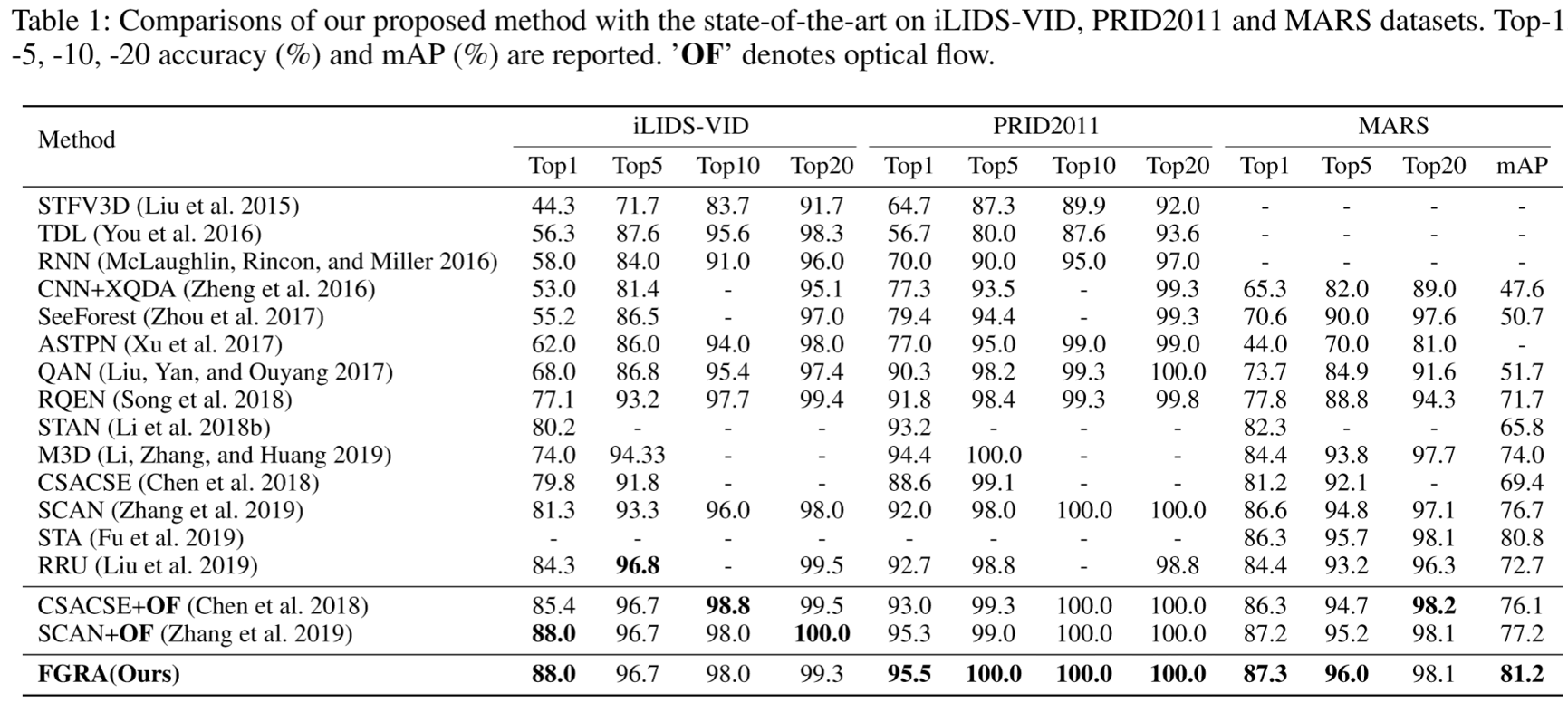
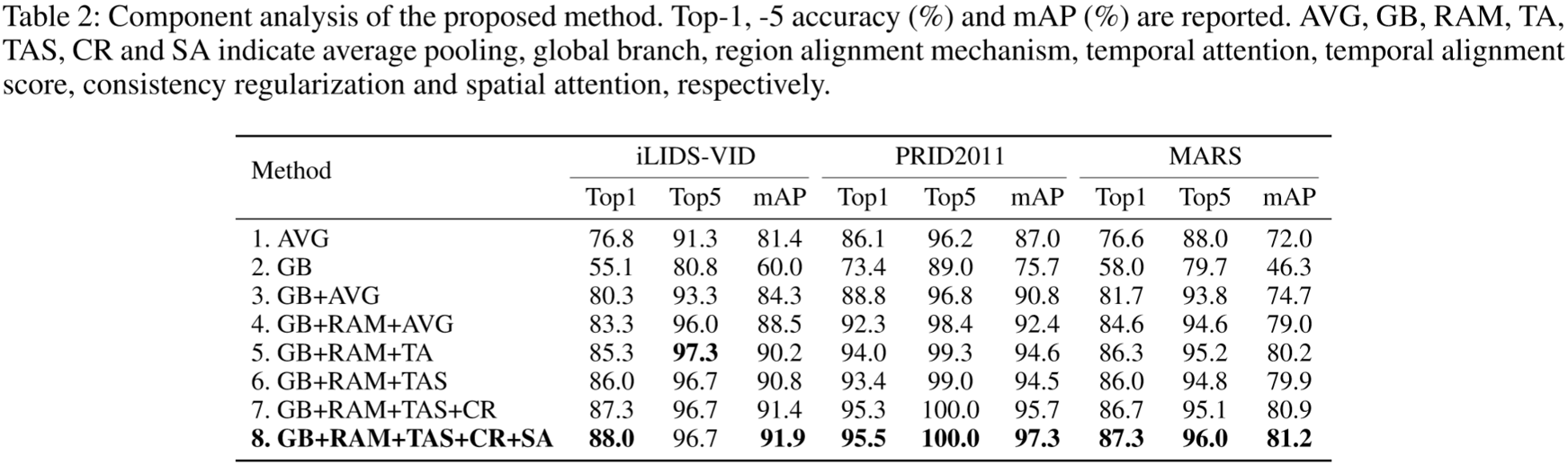
(2)实验结果: