namenode在管理元数据层面,除了去维护内存中的目录树以外,还需要维护磁盘上的元数据;
但是:
我们在做大数据的时候,都知道在服务器的处理速度中,它有一个金字塔模型:
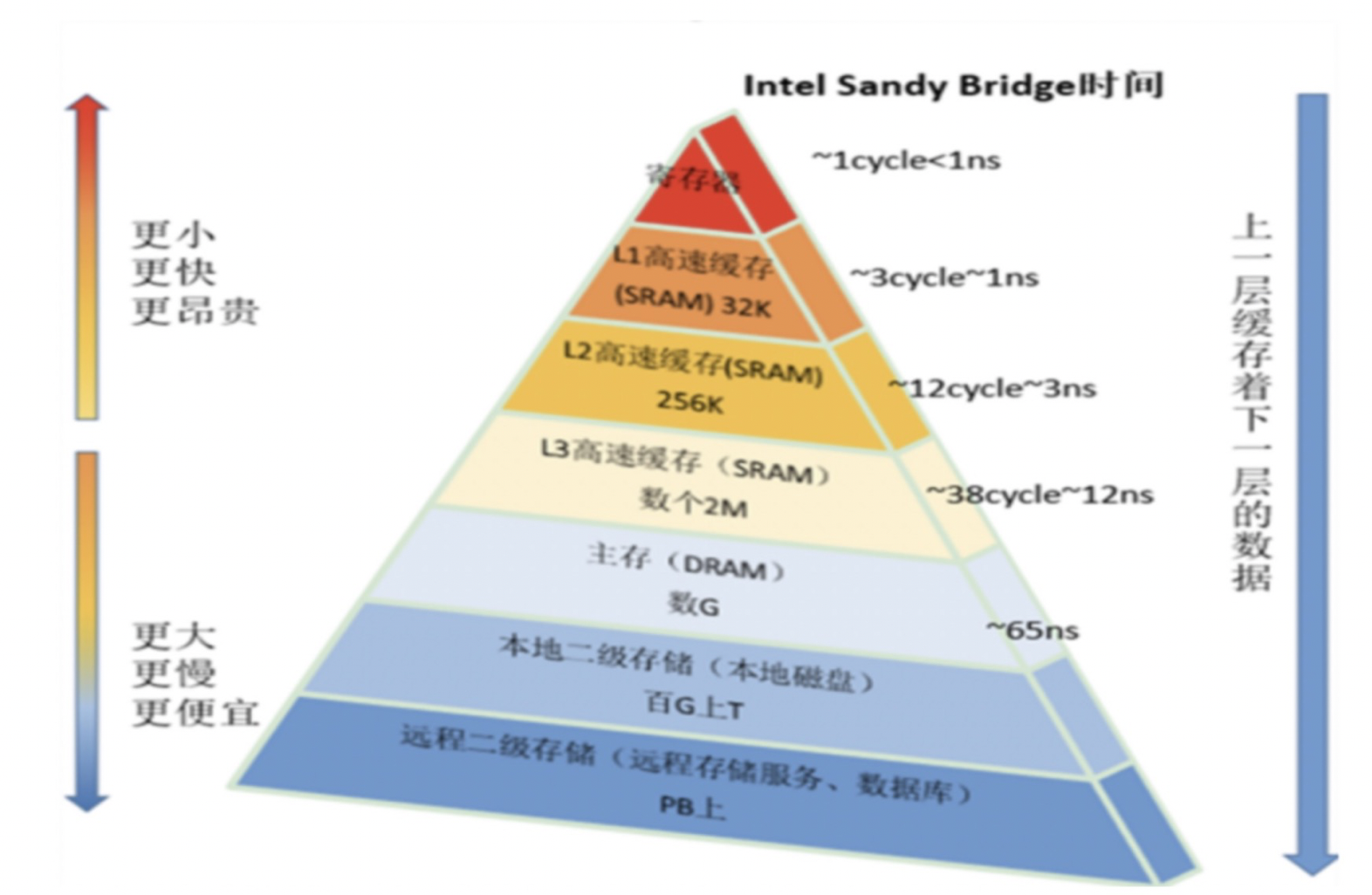
最慢的处理速度就是本地磁盘和二级存储;
但是我们生产环境中namenode可以说是整个集群的中心,我们会在hadoop的基础上提供:flink、spark、hbase等操作,这些操作会不停的以高并发的方式向namenode写元数据;
可能每秒钟就要2000 ~ 3000 甚至更高的并发(2000条大概300M左右);
双缓冲机制的简单介绍
首先是因为虽然元数据是首先写入内存的,但是你要知道元数据在内存中并不是安全的,所以namenode要将元数据刷新到磁盘里面;
但是namenode并不是直接写入磁盘的,而是采用双缓冲机制,先将数据写入到内存中,然后在从内存中写入到磁盘里面
模型大概涨这个样子:
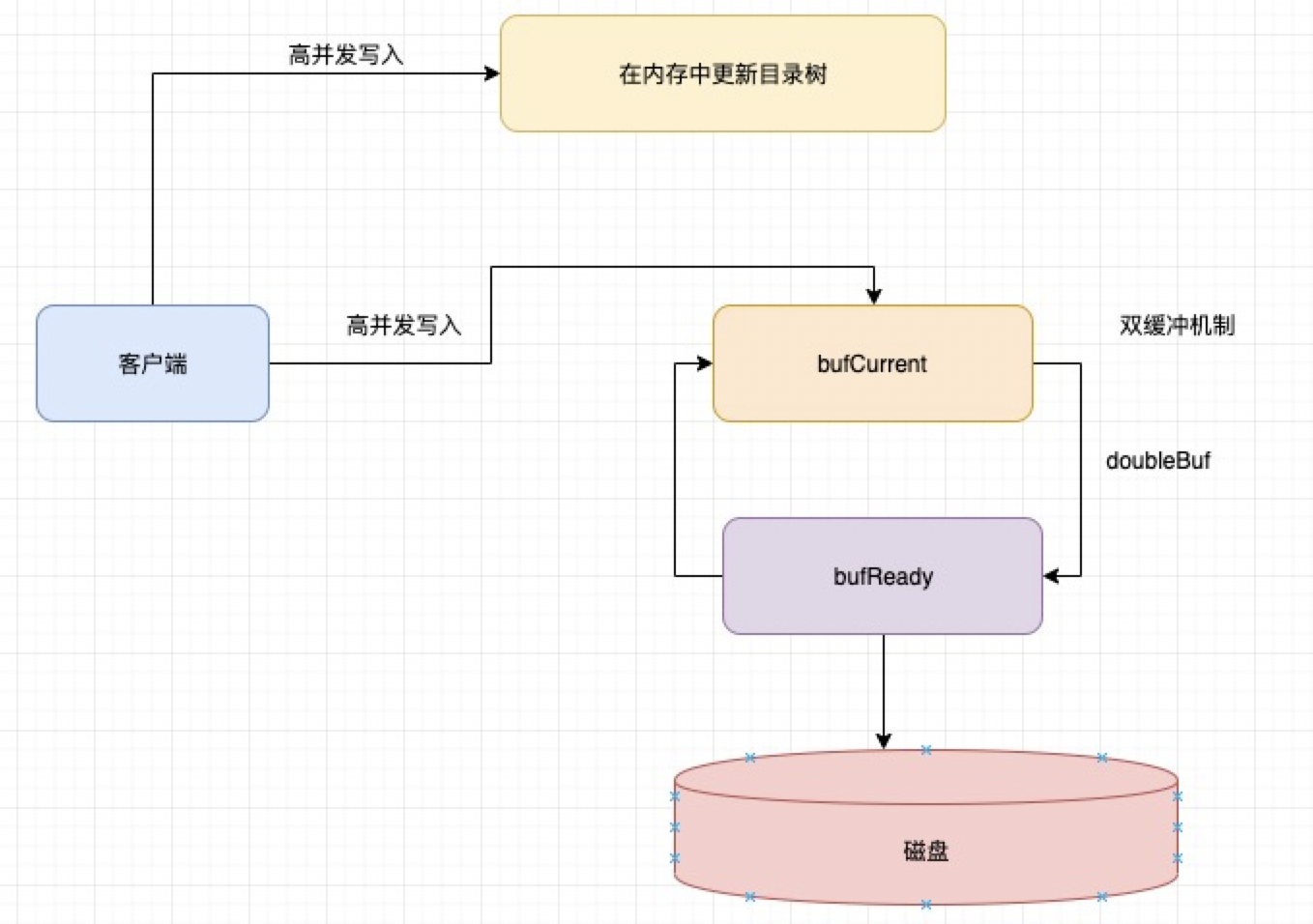
大概的步骤简单概述一下:
1、首先将元数据写入内存(bufCurrent)中 2、当满足一定条件的时候,我们会将两个内存进行交换 3、我们将bufCurrent里面的数据交换到bufReady里面,然后bufCurrent里面为空,继续接收写入内存的数据 bufReady里面保存的是写入内存里面的数据,然后偷偷刷到磁盘,刷完后清空内存 4、然后周而复始,bufCurrent永远去接收数据,然后会把数据传递给bufReady,bufReady在继续偷偷刷磁盘 那么通过这个这种双缓冲机制,就将原本写磁盘的操作变成了写内存操作。从而大大提高了效率
2、源码-hadoop是如何实现双缓冲的
通过源码提供的测试代码,创建一个文件夹。这样namenode就会维护一份元数据目录
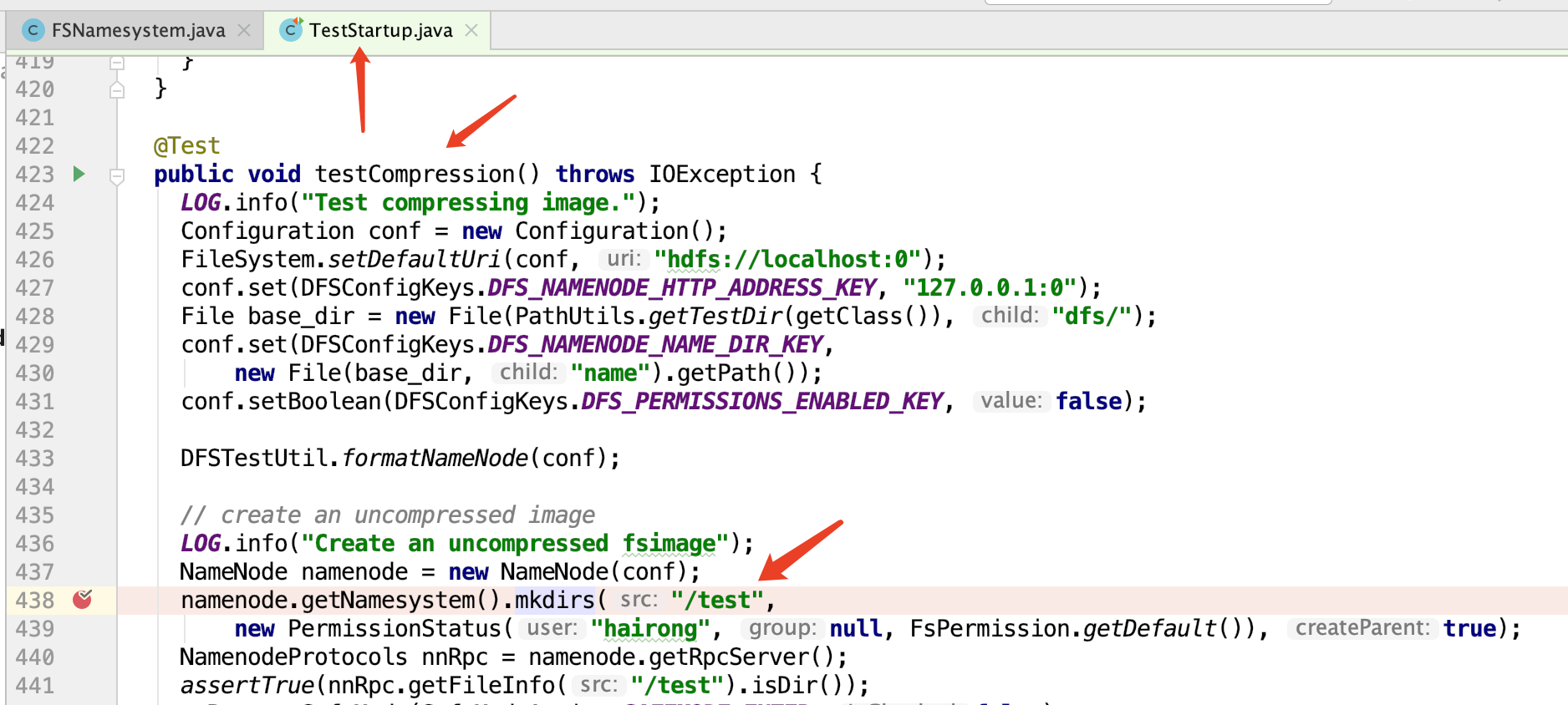
此时代码走到:
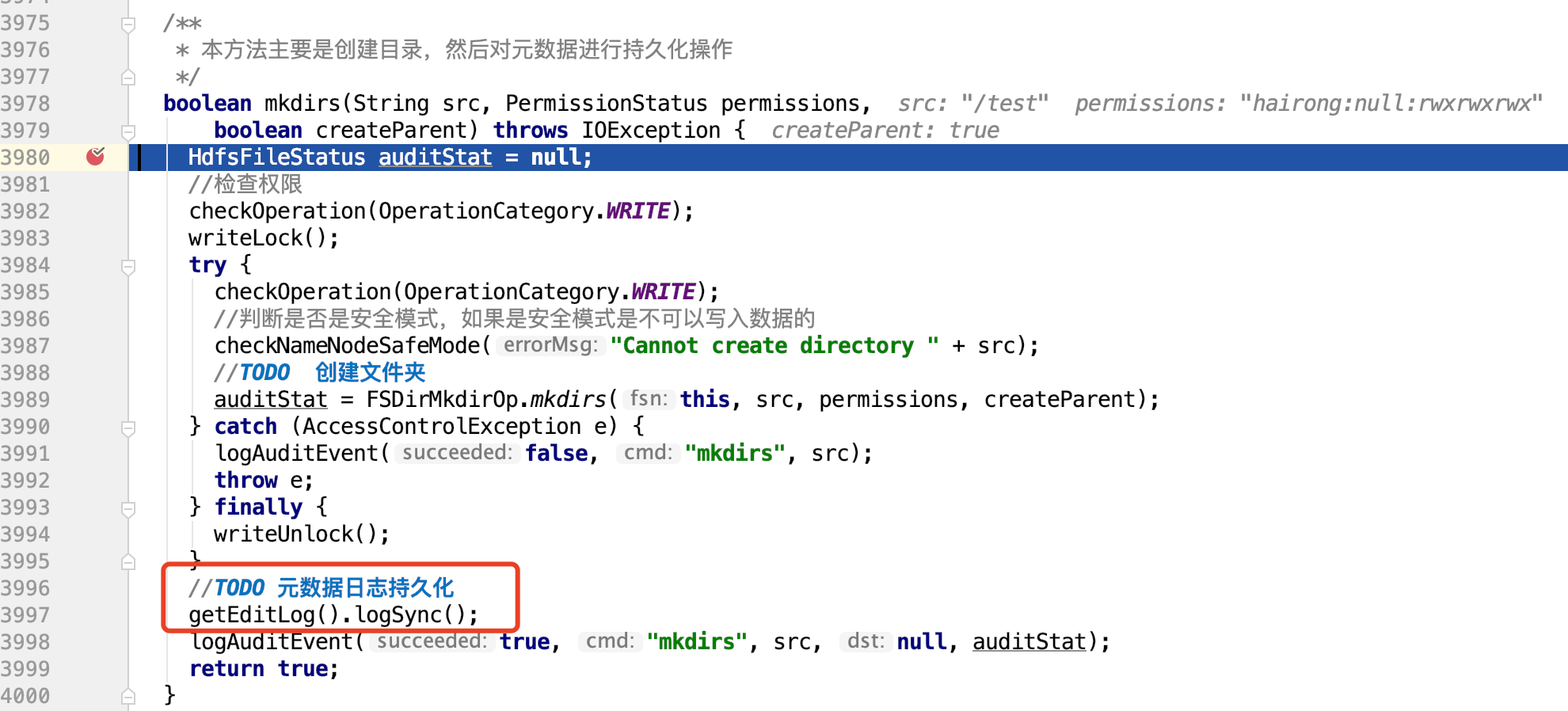
紧接着就是元数据刷新的地方:所以我们跟进源码getEditLog().logSync();
在logSync这个方法中,利用分段锁,实现安全高效存储数据
源码如下:
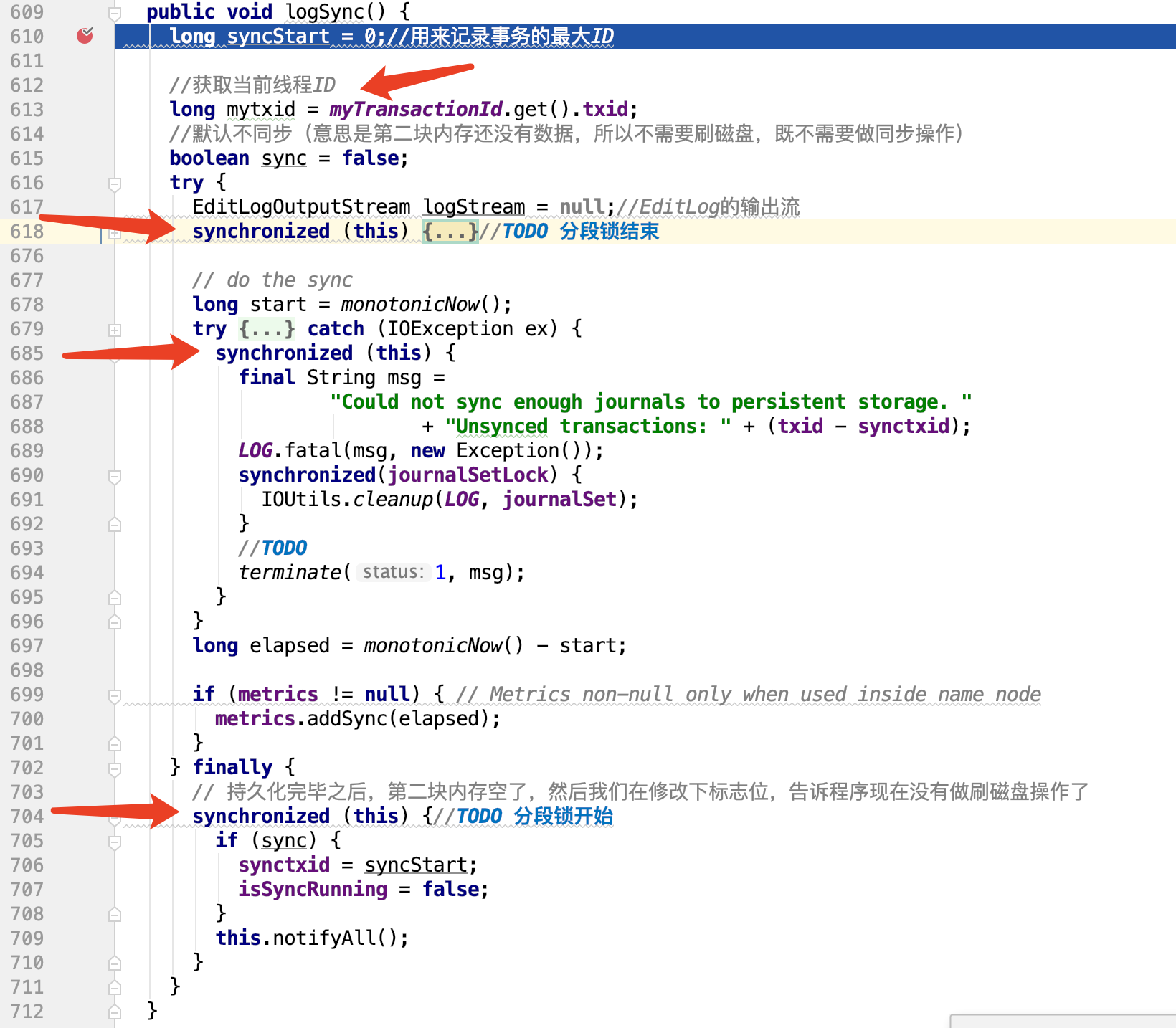
public void logSync() { long syncStart = 0;//用来记录事务的最大ID //获取当前线程ID long mytxid = myTransactionId.get().txid; //默认不同步(意思是第二块内存还没有数据,所以不需要刷磁盘,既不需要做同步操作) boolean sync = false; try { EditLogOutputStream logStream = null;//EditLog的输出流 synchronized (this) {//TODO 分段锁开始 try { printStatistics(false);//打印静态信息 /** * 如果当前工作的线程> 最大事务ID && 是同步状态的,那么说明当前线程正处于刷盘状态。 * 说明此事正处于刷盘状态,则等待1s * */ while (mytxid > synctxid && isSyncRunning) { try { wait(1000); } catch (InterruptedException ie) { } } // // If this transaction was already flushed, then nothing to do //如果当前的线程ID < 当前处理事务的最大ID,则说明当前线程的任务已经被其他线程完成了,什么也不用做了 if (mytxid <= synctxid) { numTransactionsBatchedInSync++; if (metrics != null) { // Metrics is non-null only when used inside name node metrics.incrTransactionsBatchedInSync(); } return; } //此事开启同步状态,开始刷盘 syncStart = txid; isSyncRunning = true;//开启同步 sync = true; //TODO 双缓冲区,交换数据 try { if (journalSet.isEmpty()) { throw new IOException("No journals available to flush"); } //双缓冲区交换数据 editLogStream.setReadyToFlush(); } catch (IOException e) { final String msg = "Could not sync enough journals to persistent storage " + "due to " + e.getMessage() + ". " + "Unsynced transactions: " + (txid - synctxid); LOG.fatal(msg, new Exception()); synchronized(journalSetLock) { IOUtils.cleanup(LOG, journalSet); } terminate(1, msg); } } finally { // 防止RuntimeException阻止其他日志编辑写入 doneWithAutoSyncScheduling(); } //editLogStream may become null, //so store a local variable for flush. logStream = editLogStream; }//TODO 分段锁结束 // do the sync long start = monotonicNow(); try { if (logStream != null) { //TODO 将缓冲区数据刷到磁盘(没有上锁) logStream.flush();///tmp/hadoop-angel/dfs/name/current } } catch (IOException ex) { synchronized (this) { final String msg = "Could not sync enough journals to persistent storage. " + "Unsynced transactions: " + (txid - synctxid); LOG.fatal(msg, new Exception()); synchronized(journalSetLock) { IOUtils.cleanup(LOG, journalSet); } //TODO terminate(1, msg); } } long elapsed = monotonicNow() - start; if (metrics != null) { // Metrics non-null only when used inside name node metrics.addSync(elapsed); } } finally { // 持久化完毕之后,第二块内存空了,然后我们在修改下标志位,告诉程序现在没有做刷磁盘操作了 synchronized (this) {//TODO 分段锁开始 if (sync) { synctxid = syncStart; isSyncRunning = false; } this.notifyAll(); } } }
上面方法大概流程就是:
1、首先创建一个写元数据需要的日志类:FSEditLog
主要用来记录高并发情况下,当前的事务ID、和元数据的缓冲流
2、然后准备双缓冲区的内存缓冲流
private TxnBuffer bufCurrent; // current buffer for writing private TxnBuffer bufReady; // buffer ready for flushing
所谓的双缓冲高并发,其实就是bufCurrent和bufReady互相交换数据,实现异步的读写
bufCurrent用来接收元数据
bufReady用来往磁盘写数据
//双缓冲区,交换数据 public void setReadyToFlush() { assert isFlushed() : "previous data not flushed yet"; TxnBuffer tmp = bufReady; bufReady = bufCurrent; bufCurrent = tmp; }
3、利用分段锁和事务ID,保证并发泄不出错