下面,我们从几个简单的爬虫开始我们的爬虫之旅
我们先来做一个通用的爬虫,作用是爬取一个搜索引擎的搜索结论。比方说用搜狗搜一下python这个关键字,注意看一下url:
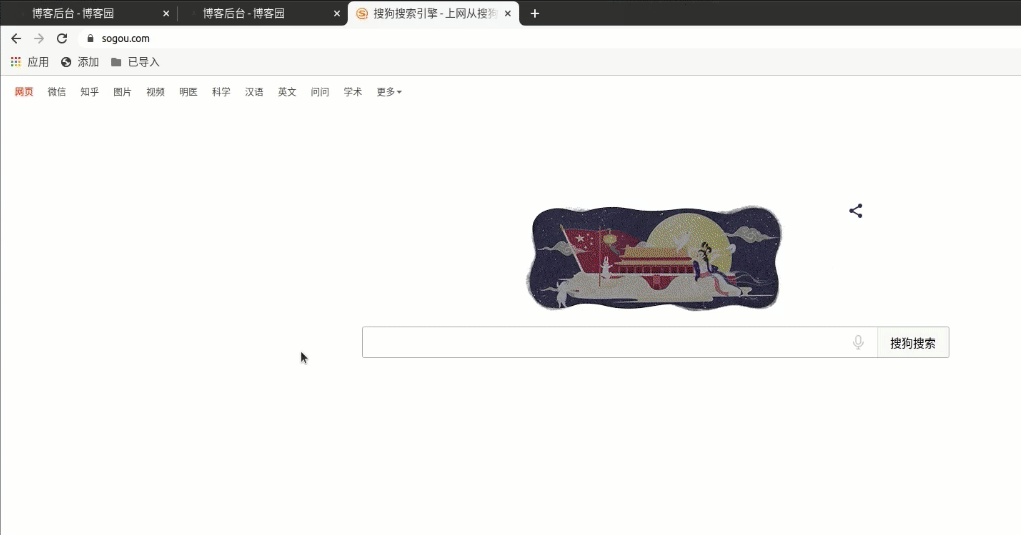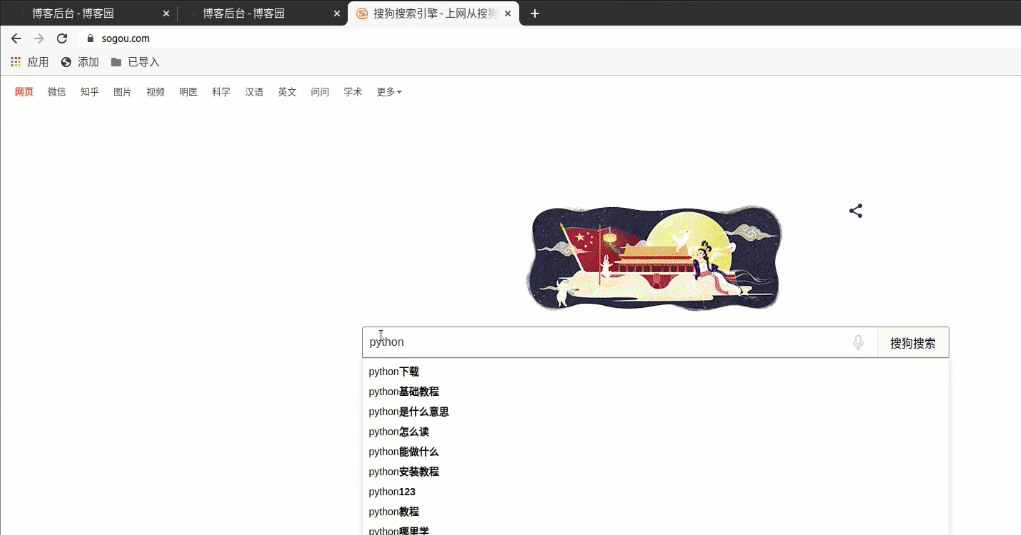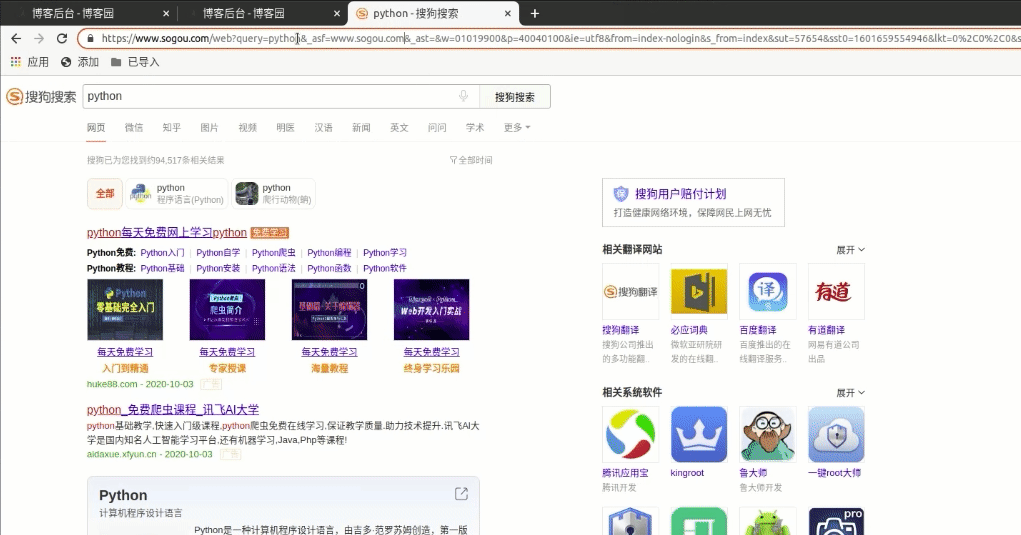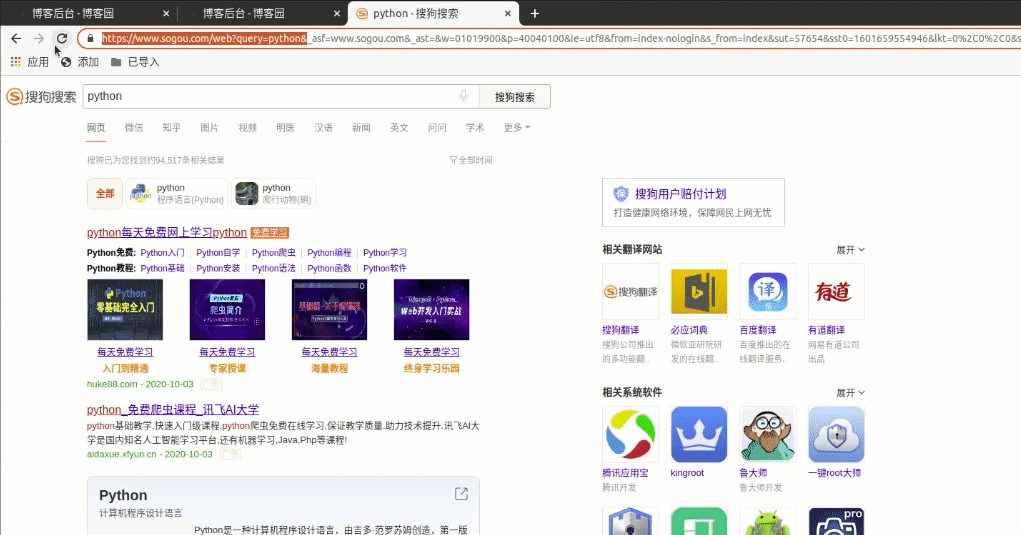
可以看出来这是个GET请求,参数可以直接看出来,也可以通过浏览器的抓包工具看一下
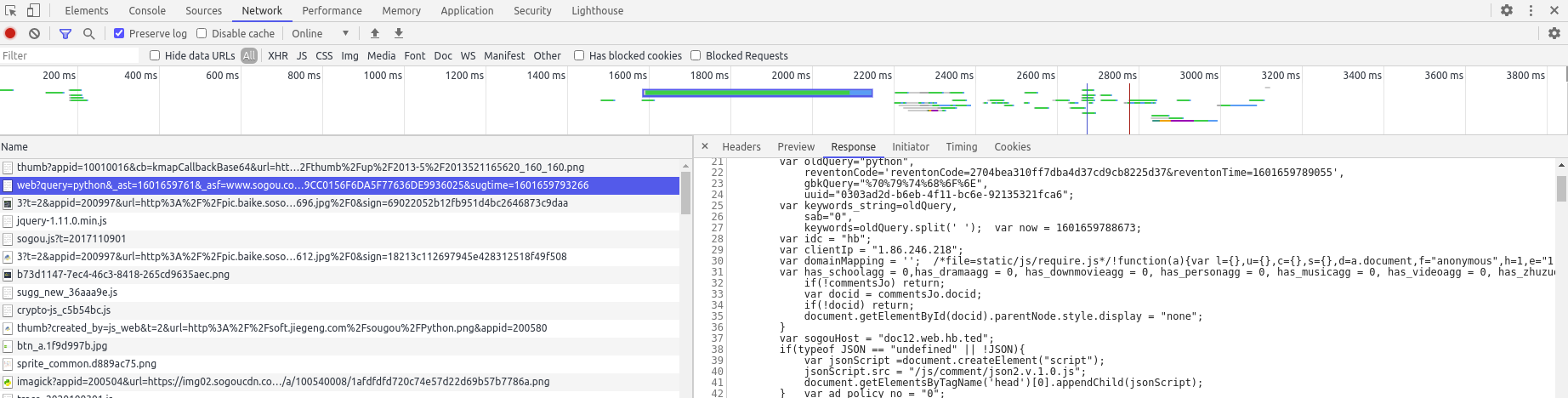
上面的图里大概演示了从哪里找到抓包工具,选中的就是我们请求的内容。可以看看右边那个对话框中的Headers选项卡里的内容,讲了请求头和响应头
请求头

响应头

请求头中选中的那一行User-Agent是几乎所有爬虫都要设置的一个内容,——UA伪装。
UA伪装和UA策略
服务器在拿到请求的时候,可以通过请求头里的参数User-Agent获取到请求载体的身份标识,如果是浏览器的话就允许访问数据,否则就屏蔽掉。这应该就是最原始的反爬策略了。所以我们就给爬虫加了个UA伪装,让他假装是一个浏览器
1 #!/usr/bin/python3 2 import requests 3 4 if __name__ == '__main__': 5 url = 'https://www.sogou.com/web' 6 headers = { 7 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36' 8 } 9 #处理url携带的参数 10 kw = input('word:') 11 12 param = { 13 'query':kw 14 } 15 16 respon = requests.get(url,params=param,headers=headers) 17 18 data = respon.text 19 file_name ='./'+ kw+'.html' 20 with open(file_name,'w',encoding='utf-8') as f: 21 f.write(data)
上面就是最简单的爬虫了。param里的key是从GET请求的参数来的
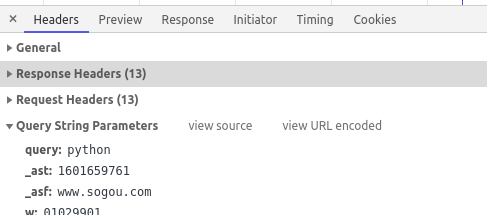
整个过程没什么难的,因为响应头里定义了数据的类型就是text,所以我们就在18行里的data就是respon.text的方式拿到数据的。
有很多的页面是通过AJAX请求来对页面部分刷新的,而这些刷新出来的内容正是我们需要的,这个爬虫要怎么做呢?

其实我们主要就是想拿到输入框下面的内容,注意看一下我们每输入一个字母就会队页面进行一下刷新,所以这应该是个AJAX请求
还是要看看抓包工具里的几个重要的参数
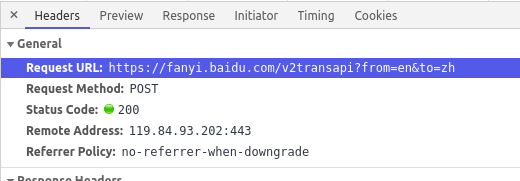
上面说明了AJAX请求的URL和方法
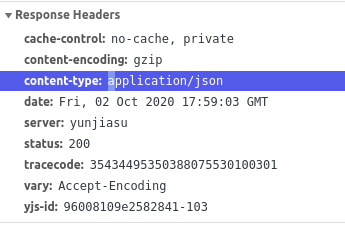
这里可以注意一下,返回的内容是个json对象
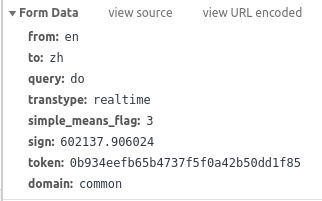
看看输入do以后的请求带的参数,主要是query,其实其他的都可以暂时忽略。
所以我们可以根据上面的内容来组织代码
1 # !/usr/bin/python3 2 import requests 3 4 if __name__ == '__main__': 5 url = 'https://fanyi.baidu.com/sug' 6 headers = { 7 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36' 8 } 9 10 word = input('word') 11 12 data = {'kw':word} 13 14 response = requests.post(url=url,headers=headers,data=data) 15 16 with open('./'+word,'w') as f: 17 f.write(response.json)
因为响应的内容是个json对象,所以最后一行的代码是response.json,这样就完成了数据的持久化。
从上面两个简单的爬虫入手,我们大概了解了如何通过浏览器的行为去构建一个爬虫。后面我们去爬一个稍微复杂的数据!