1 什么是购物篮分析
购物篮分析(Market basket analysis)是用来挖掘消费者已购买的或保存在购物车中物品组合规律的方法。这个概念适用于不同的应用,特别是商店运营。源数据集是一个巨大的数据 记录,购物篮分析的目的发现源数据集中不同项之间的关联关系。例如,购买鞋的顾客,有10%的可能也会买袜子,60%的买面包的顾客,也会买牛奶。这其中最有名的例子就是 "尿布和啤酒"的故事:
我们去沃尔玛超市会发现一个很有趣的现象:货架上啤酒与尿布竟然放在一起售卖,这看似两者毫不相关的东西,为什么会放在一起售卖呢?
原来,在美国,妇女们经常会嘱咐她们的丈夫下班以后给孩子买一点尿布回来,而丈夫在 买完尿布后,大都会顺手买回一瓶自己爱喝的啤酒(由此看出美国人 爱喝酒)。商家通过对一年多的原始交易记录进行详细的分析,发现了这对神奇的组合。于是就毫不犹豫地将尿布与啤酒摆放在一起售卖,通过它们的关联性,互相促进销售。“啤酒与尿布”的故事一度是营销界的神话。

2 关联规则
2.1 简介
那么问题来了,商家是如何发现啤酒与尿布两者之间的关联性呢?
这里就用到了关联规则挖掘。大致意思就是从大量数据中找出某两个 对象(暂且称为X, Y)的关联性。
关联规则就是从一种行为中发现与之相关联的另一种行为,即A→B,并用一定的概率度加以保 证。关联规则广泛的应用在零售业、金融业和互联网行业。运用在购物篮分析中,挖掘一般顾客在购买X产品的同时还会购买其他什么产品,于是制定相应营销策略,进行捆绑销售,增加销售量。
又如金融业中,预测银行客户需求,如果数据库中显示,某个高信用限额的客户更换了地址,这个客户很有可能新近购买了一栋更大的住宅,因此会有可能需要更高信用限 额,更高端的新信用卡,或者需要一个住房改善 贷款,这些产品都可以通过信用卡账单邮寄给客户。电子购物网站也使用关联规则进行挖掘,一些购物网站使用关联规则设置相应的交叉销售,也就是购买某种商品的顾客会看到相关的另外一种商品的广告。
2.2 如何来度量一个规则是否足够好?
有两个量,置信度(Confifidence)和支持度(Support)。
支持度( support):
支持度也就是A和B同时出现的频率,即P(AB)。如果A和B一起出现的频率非常小,那么就说明了A和B之间的联系并不大; 但若一起出现的频率非常频繁,那么A和B的关联性也就自然更大。上面例子的支持度就是: 800/10000*100%=8%。
置信度(confifidence):
置信度也称为可靠度,置信度表示了 这条规则有多大程度上值得可信。 也就是在A出现的情况下B出现的概率,即P(B|A),P(B|A)=P(AB)/P(A)。因此,上面例子的置信度就是: P(AB)=8%,P(A)=1000/10000*100%=10%,P(B|A)=8%/10%=80%
置信度揭示了B出现时,A是否一定会出现,如果出现则其大概有多大的可能出 现。如果置信度为100%,则说明了B出现时,A一定出现。那么,对这种情况而言,假设A和B是市场上的两种商品,就没有理由不 进行捆绑销售了。如果置信度太低,那么就会 产生这样的疑问,A和B关系并不大,也许与B关联的并不是A。
最小支持度:
它表示了一组物品集在统计意义上需要满足的最低程度。
最小可信度 :
它反映了关联规则的最低可靠程度。
2.3 购物篮分析的应用
购物篮分析的主要应用如下:
个性化推荐:在界面上 给用户推荐相关商品
组合优惠券:给购买过得用户发放同时购买组合内商品的优惠券
捆绑销售:将相关商品组合起来销售
3 描述性统计结果
数据集中一共有9835个记录,也就是9835个订单,其中有2159个订单只买了一件商品。整个数据集 总共有169种商品。
购买量最大的前五位商品分 别是:
whole milk (全脂牛奶),other vegetables (其他蔬菜),rolls/buns (甜点),soda (碳酸饮料), yogurt(酸奶)

4 Apriori关联分析
Apriori算法实现基本流程:
①选出满足支持度最小阈值的所有项集,即频繁项集;
②从频繁项集中找出满足最小置信度的所有规则。
其实apriori算法特别好理解,就是只计算频繁集都特别高的子集。比如在我们数据集中,频繁集最高的单个商品是whole milk(全脂牛奶),那么,在计算并集的时候,从这个商品开始入手计算。节省了运行次数和空间。
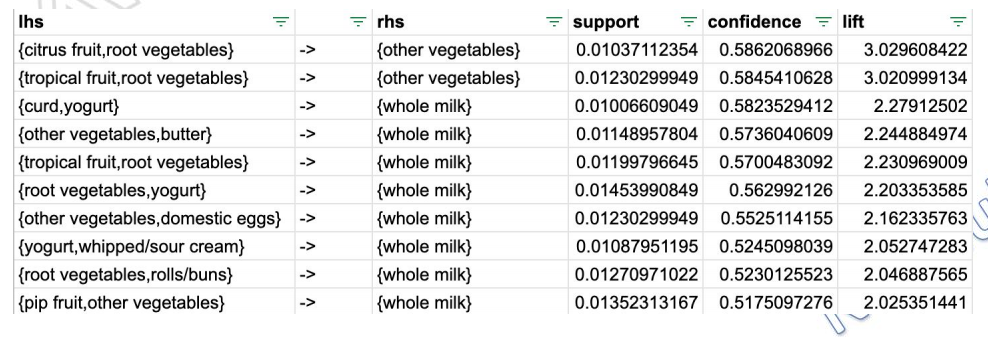
由于默认的支持度为10%,可信度为80%,对于当前的9835条交易记录来说过高,使得没有这样的交易满足这两个条件。因此,如果使用 Apriori算法的默认参数设置时将产生0条规则。故需要人为调整支持度和可信度,这里不妨将支持度设置为1%,即认为某种商品在购物篮中至少出现98次,可信度设置为30%,即认为同时出现某几种商品组合的概率为30%。