目录
网络结构
两大创新点
参考资料
第一个典型的CNN是LeNet5网络结构,但是第一个引起大家注意的网络却是AlexNet,Alex Krizhevsky其实是Hinton的学生,这个团队领导者是Hinton,于2012年发表论文。
AlexNet有60 million个参数和65000个 神经元,五层卷积,三层全连接网络,最终的输出层是1000通道的softmax。AlexNet利用了两块GPU进行计算,大大提高了运算效率,并且在ILSVRC-2012竞赛中获得了top-5测试的15.3%error rate, 获得第二名的方法error rate 是 26.2%,可以说差距是非常的大了,足以说明这个网络在当时给学术界和工业界带来的冲击之大。
|
网络结构 |
AlexNet的网络结构如下,在论文中输入图像写的是224,通过查阅资料了解到,应该是作者做了跳步,先对图像预处理,把224的图像转为了227:
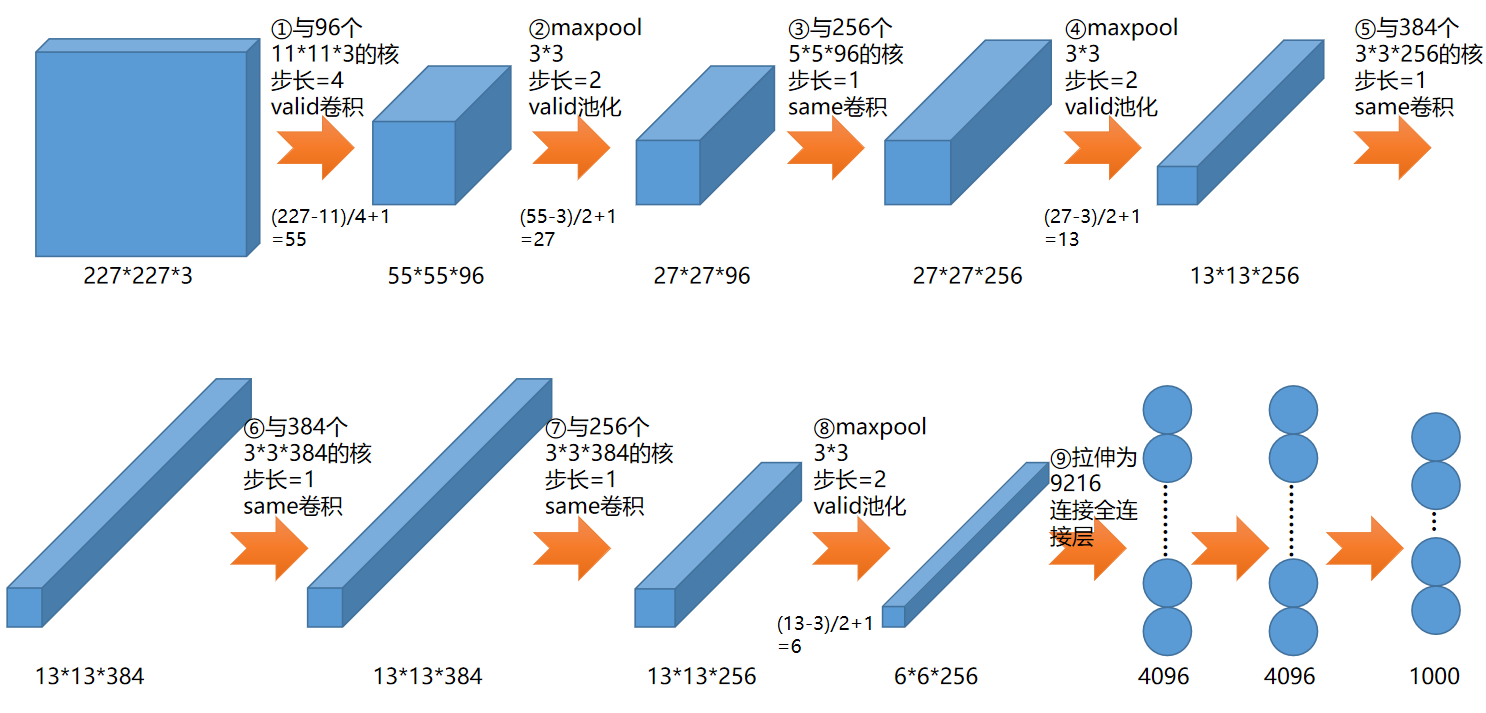
这个网络比较大,需要的训练数据也是ImageNet的数据集(上百GB),训练十分耗时,真正做图像分类可以使用微调的方式,这个会在后面将slim的时候展开,所以这里先给出网络结构的代码,帮助大家理解上面的图,我已经在pycharm中调试过,尺寸都是正确的。


import tensorflow as tf import numpy as np #输入 x=tf.placeholder(tf.float32,[None,227,227,3]) keep_prob=tf.placeholder(tf.float32) # ①与96个11*11*3的核,步长=4,valid卷积 w1=tf.Variable(tf.random_normal([11,11,3,96]),dtype=tf.float32,name='w1') l1=tf.nn.conv2d(x,w1,[1,4,4,1],'VALID') b1=tf.Variable(tf.random_normal([96]),dtype=tf.float32,name='b1') l1=tf.nn.bias_add(l1,b1) l1=tf.nn.relu(l1) # 结果为55*55*96 # ②maxpool,3*3,步长=2,valid池化 pool_l1=tf.nn.max_pool(l1,[1,3,3,1],[1,2,2,1],'VALID') # 结果为27*27*96 # ③与256个,5*5*96的核,步长=1,same卷积 w2=tf.Variable(tf.random_normal([5,5,96,256]),dtype=tf.float32,name='w2') l2=tf.nn.conv2d(pool_l1,w2,[1,1,1,1],'SAME') b2=tf.Variable(tf.random_normal([256]),dtype=tf.float32,name='b2') l2=tf.nn.bias_add(l2,b2) l2=tf.nn.relu(l2) # 结果为27*27*256 # ④maxpool,3*3,步长=2,valid池化 pool_l2=tf.nn.max_pool(l2,[1,3,3,1],[1,2,2,1],'VALID') # 结果为13*13*256 # ⑤与384个,3*3*256的核,步长=1,same卷积 w3=tf.Variable(tf.random_normal([3,3,256,384]),dtype=tf.float32,name='w3') l3=tf.nn.conv2d(pool_l2,w3,[1,1,1,1],'SAME') b3=tf.Variable(tf.random_normal([384]),dtype=tf.float32,name='b3') l3=tf.nn.bias_add(l3,b3) l3=tf.nn.relu(l3) # 结果为13*13*384 # ⑥与384个,3*3*384的核,步长=1,same卷积 w4=tf.Variable(tf.random_normal([3,3,384,384]),dtype=tf.float32,name='w4') l4=tf.nn.conv2d(l3,w4,[1,1,1,1],'SAME') b4=tf.Variable(tf.random_normal([384]),dtype=tf.float32,name='b4') l4=tf.nn.bias_add(l4,b4) l4=tf.nn.relu(l4) # 结果为13*13*384 # ⑦与256个,3*3*384的核,步长=1,same卷积 w5=tf.Variable(tf.random_normal([3,3,384,256]),dtype=tf.float32,name='w5') l5=tf.nn.conv2d(l4,w5,[1,1,1,1],'SAME') b5=tf.Variable(tf.random_normal([256]),dtype=tf.float32,name='b5') l5=tf.nn.bias_add(l5,b5) l5=tf.nn.relu(l5) # 结果为13*13*256 # ⑧maxpool,3*3,步长=2,valid池化 pool_l5=tf.nn.max_pool(l5,[1,3,3,1],[1,2,2,1],'VALID') # 结果为6*6*256 # ⑨拉伸为9216,全连接 pool_l5_shape=pool_l5.get_shape() num=pool_l5_shape[1].value*pool_l5_shape[2].value*pool_l5_shape[3].value flatten=tf.reshape(pool_l5,[-1,num]) # 结果为9216个神经元 # 第1个隐含层 fcW1=tf.Variable(tf.random_normal([num,4096]),dtype=tf.float32,name='fcW1') fc_l1=tf.matmul(flatten,fcW1) fcb1=tf.Variable(tf.random_normal([4096]),dtype=tf.float32,name='fcb1') fc_l1=tf.nn.bias_add(fc_l1,fcb1) fc_l1=tf.nn.relu(fc_l1) fc_l1=tf.nn.dropout(fc_l1,keep_prob) # 第2个隐含层 fcW2=tf.Variable(tf.random_normal([4096,4096]),dtype=tf.float32,name='fcW2') fc_l2=tf.matmul(fc_l1,fcW2) fcb2=tf.Variable(tf.random_normal([4096]),dtype=tf.float32,name='fcb2') fc_l2=tf.nn.bias_add(fc_l2,fcb2) fc_l2=tf.nn.relu(fc_l2) fc_l2=tf.nn.dropout(fc_l2,keep_prob) # 输出层 fcW3=tf.Variable(tf.random_normal([4096,1000]),dtype=tf.float32,name='fcW3') out=tf.matmul(fc_l2,fcW3) fcb3=tf.Variable(tf.random_normal([1000]),dtype=tf.float32,name='fcb3') out=tf.nn.bias_add(out,fcb3) out=tf.nn.relu(out) #"创建会话" session=tf.Session() session.run(tf.global_variables_initializer()) result=session.run(out,feed_dict={x:np.ones([1,227,227,3],np.float32), keep_prob:0.5}) #"打印最后的输出尺寸" print(np.shape(result))
|
两大创新点 |
AlexNet有两个较大的创新点,一个是使用了Relu激活函数,加快了模型的学习过程,这个已经在《深度学习面试题05:激活函数sigmod、tanh、ReLU、LeakyRelu、Relu6》介绍过;另一个就是加入了dropout,可以防止模型的过拟合。
|
参考资料 |
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
AlexNet-imagenet-classification-with-deep-convolutional-neural-networks