郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
Arxiv:https://arxiv.org/abs/1812.05905

Abstract
无模型的深度RL算法已成功应用于一系列具有挑战性的序列决策和控制任务。但是,这些方法通常面临两个主要挑战:高样本复杂性和超参数的脆弱性。这两个挑战都将这种方法的应用范围限制在现实世界之外。在本文中,我们描述了SAC算法,这是我们最近引入的基于最大熵RL框架的异策actor-critic算法。在这个框架中,actor的目标是同时最大化期望回报和熵。也就是说,要在完成任务的同时尽可能随机地动作。我们将SAC扩展为合并许多修改,这些修改可以加速训练并提高有关超参数的稳定性,包括自动调整温度超参数的约束公式。我们对一系列基准任务以及具有挑战性的实际任务(例如四足机器人的运动和灵巧的机器人操作)进行系统评估,以评估SAC。通过这些改进,SAC实现了最先进的性能,在样本效率和渐进性能方面优于以前的同策和异策方法。此外,我们证明,与其他异策算法相比,我们的方法非常稳定,在不同的随机种子上实现了相似的性能。这些结果表明,SAC是在现实世界中学习机器人任务有希望的候选。

参数化soft Q函数Qθ(st, at)和易处理的策略πΦ(at|st)。这些网络的参数为θ和Φ。可以将soft Q函数建模为表达神经网络,将策略建模为具有神经网络给出均值和协方差的高斯模型。
![]()
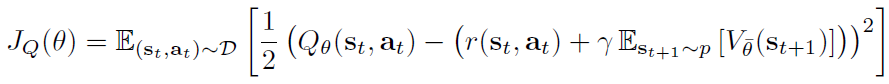
![]()
此更新利用了目标软Q函数,该目标的soft Q函数具有作为soft Q函数权重的指数移动平均而获得的参数![]() ,已证明可以稳定训练。
,已证明可以稳定训练。
![]()
![]()
其中 t 是输入噪声矢量,是从某个固定分布(例如球形高斯)采样的。
![]()
![]()
![]()