1、Spark SQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
为什么要学习Spark SQL?
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!同时Spark SQL也支持从Hive中读取数据。
2、Spark SQL的特点:
容易整合(集成)

统一的数据访问方式

兼容Hive
标准的数据连接

3、基本概念:Datasets和DataFrames
DataFrame
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,但在底层具有更丰富的优化。DataFrames可以从各种来源构建,
例如:
l 结构化数据文件
l hive中的表
l 外部数据库或现有RDDs
DataFrame API支持的语言有Scala,Java,Python和R。
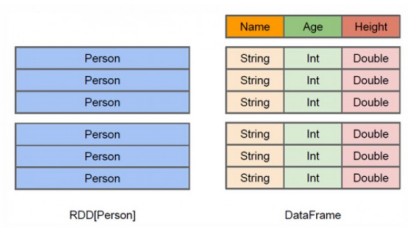
从上图可以看出,DataFrame多了数据的结构信息,即schema。
RDD是分布式的 Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化
Datasets
Dataset是数据的分布式集合。Dataset是在Spark 1.6中添加的一个新接口,是DataFrame之上更高一级的抽象。它提供了RDD的优点(强类型化,使用强大的lambda函数的能力)以及Spark SQL优化后的执行引擎的优点。一个Dataset 可以从JVM对象构造,然后使用函数转换(map, flatMap,filter等)去操作。 Dataset API 支持Scala和Java。 Python不支持Dataset API。
4、SparkSQL的API操作
一:DataFrame的操作(SQL风格)
编写代码如下:
package day04
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月23日21:42:35
* spark2.x
* 测试SparkSql
*/
object SqlTest1 {
def main(args: Array[String]): Unit = {
//1.构建SparkSession
val sparkSession: SparkSession = SparkSession.builder().appName("SqlTest1")
.master("local[2]").
getOrCreate()
//2.创建RDD
val dataRdd:RDD[String]=sparkSession.sparkContext.textFile("hdfs://hadoop01:9000/user.txt")
//3.切分数据
val splitRdd: RDD[Array[String]] = dataRdd.map(_.split(" "))
//4.封装数据
val rowRdd = splitRdd.map(x => {
val id = x(0).toInt
val name = x(1).toString
val age = x(2).toInt
//封装一行数据
Row(id,name,age)
})
//5.创建schema(描述DataFrame信息) sql=表
val schema: StructType = StructType(List(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
//6.创建DataFram
val userDF:DataFrame = sparkSession.createDataFrame(rowRdd,schema)
//7.注册表
userDF.registerTempTable("user_t")
//8.写sql
// val usql:DataFrame=sparkSession.sql("select * from user_t order by age")
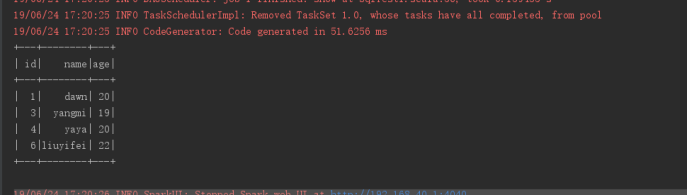
val usql:DataFrame=sparkSession.sql("select * from user_t where age > 18")
//9.查看结果 show databases;
usql.show()
//10.释放资源
sparkSession.stop()
}
}
这里读取的hdfs中的数据,数据如下:
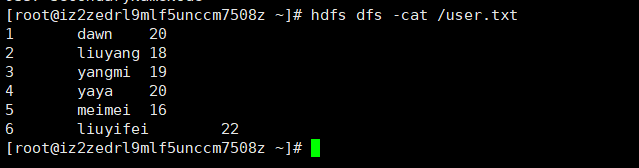
该程序的运行结果如下:
二:DataFrame的操作(DSL风格)
代码如下:
package day05
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月23日22:01:41
* DSL风格
*/
object SqlTest2 {
def main(args: Array[String]): Unit = {
//1.构建sparkSession
val sparkSession:SparkSession=SparkSession.builder()
.appName("SqlTest2").master("local[2]").getOrCreate()
//2.创建rdd
val dataRdd:RDD[String]=sparkSession.sparkContext.textFile("hdfs://hadoop01:9000/user.txt")
//3.切分数据
val splitRdd:RDD[Array[String]] = dataRdd.map(_.split(" "))
val rowRdd:RDD[Row]=splitRdd.map(x => {
val id=x(0).toInt
val name:String=x(1).toString
val age:Int=x(2).toInt
Row(id,name,age)
})
val schema:StructType=StructType(List(
//结构字段
StructField("id",IntegerType,true),
StructField("name",StringType,true),
StructField("age",IntegerType,true)
))
//4.rdd创建为dataFrame
val userDF: DataFrame = sparkSession.createDataFrame(rowRdd,schema)
//5.DSL风格 查询年龄大于18的 rdd dataFrame dataSet
import sparkSession.implicits._
val user1DF:Dataset[Row]=userDF.where($"age" > 18)
//6.关闭资源
user1DF.show()
sparkSession.stop()
}
}
前面创建DataFrame部分和上面SQL风格的代码是一样的。这里不用进行创建表等等操作,直接写DSL语句就行了。
运行结果和数据和SQL风格那个结果一样!!!
三:SparkSQL版的wordcount
代码如下:
package day05
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月23日22:20:31
* SparkSql版的WordCount
*/
object SqlWordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val sparkSession:SparkSession=SparkSession.builder().appName("SqlWordCount").master("local[2]").getOrCreate()
//2.加载数据 使用dataSet处理数据 dataSet是一个更加智能的rdd,默认有一列叫value,value存储的是所有数据
val datas: Dataset[String] = sparkSession.read.textFile("hdfs://hadoop01:9000/temp/word.txt")
//3.sparksql 注册表/注册视图 rdd.flatMap
import sparkSession.implicits._
val word: Dataset[String] = datas.flatMap(_.split(" "))
//4.注册视图
word.createTempView("wc_t")
//5.执行sql wordcount 默认就有一个value字段
val r: DataFrame = sparkSession.sql("select value as word,count(*) sum from wc_t group by value order by sum desc")
// val r: DataFrame = sparkSession.sql("select * from wc_t")
r.show
sparkSession.stop()
}
}
这里读取的是hdfs上的数据。数据如下:

运行结果如下:
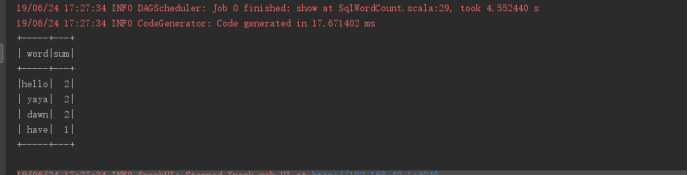
与第一个SQL风格不同的是,这里创建的是一个视图,而上面创建的是一个表。
四:Join操作(SQL风格)
代码如下:
package day05
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月23日22:30:37
* SQL方式 join操作
*/
object JoinDemo {
def main(args: Array[String]): Unit = {
//1.创建sparkSession
val sparkSession: SparkSession = SparkSession.builder().appName("JoinDemo").master("local[2]").getOrCreate()
import sparkSession.implicits._
//2.直接创建dataSet
val data1: Dataset[String] = sparkSession.createDataset(List("1 dawn 18","2 yaya 22","3 yangmi 16"))
//3.整理数据
val dataDS1:Dataset[(Int,String,Int)] = data1.map(x => {
val fields = x.split(" ")
val id:Int=fields(0).toInt
val name:String=fields(1).toString
val age:Int=fields(2).toInt
//元组输出
(id,name,age)
})
val dataDF1: DataFrame = dataDS1.toDF("id","name","age")
//2.创建第二份数据
val data2: Dataset[String] = sparkSession
.createDataset(List("18 young","22 old"))
val dataDS2: Dataset[(Int, String)] = data2.map(x => {
val fields: Array[String] = x.split(" ")
val age = fields(0).toInt
val desc = fields(1).toString
//元祖输出
(age, desc)
})
//3.转化为dataFrame
val dataDF2: DataFrame = dataDS2.toDF("dage","desc")
//4.注册视图
dataDF1.createTempView("d1_t")
dataDF2.createTempView("d2_t")
//5.写sql(join)
val r: DataFrame = sparkSession.sql("select age,desc from d1_t join d2_t on age = dage")
//6.触发任务
r.show()
//7.关闭资源
sparkSession.stop()
}
}
运行结果如下:
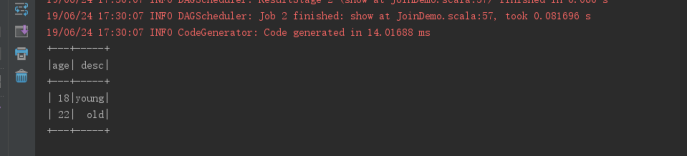
五:Join操作(DSL风格)
代码如下:
package day05
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月23日22:46:16
* 使用DSL风格
*/
object JoinDemo1 {
def main(args: Array[String]): Unit = {
//1.创建sparkSession
val sparkSession: SparkSession = SparkSession.builder().appName("JoinDemo")
.master("local[2]").getOrCreate()
import sparkSession.implicits._
//2.直接创建dataSet
val datas1: Dataset[String] = sparkSession
.createDataset(List("1 dawn 18","2 yaya 22","3 yangmi 16"))
//3.整理数据
val dataDS1: Dataset[(Int, String, Int)] = datas1.map(x => {
val fields: Array[String] = x.split(" ")
val id = fields(0).toInt
val name = fields(1).toString
val age = fields(2).toInt
//元祖输出
(id, name, age)
})
val dataDF1: DataFrame = dataDS1.toDF("id","name","age")
//2.创建第二份数据
val datas2: Dataset[String] = sparkSession
.createDataset(List("18 young","22 old"))
val dataDS2: Dataset[(Int, String)] = datas2.map(x => {
val fields: Array[String] = x.split(" ")
val age = fields(0).toInt
val desc = fields(1).toString
//元祖输出
(age, desc)
})
//3.转化为dataFrame
val dataDF2: DataFrame = dataDS2.toDF("dage","desc")
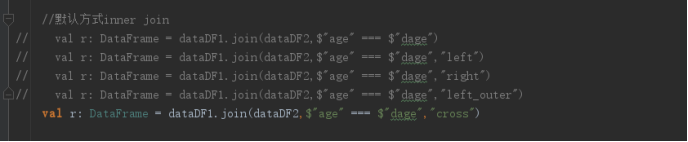
//默认方式inner join
// val r: DataFrame = dataDF1.join(dataDF2,$"age" === $"dage")
// val r: DataFrame = dataDF1.join(dataDF2,$"age" === $"dage","left")
// val r: DataFrame = dataDF1.join(dataDF2,$"age" === $"dage","right")
// val r: DataFrame = dataDF1.join(dataDF2,$"age" === $"dage","left_outer")
val r: DataFrame = dataDF1.join(dataDF2,$"age" === $"dage","cross")
r.show()
sparkSession.stop()
}
}
运行结果: