一:写出数据源
mysql中的数据作为数据源
先看看MySQL中的表

代码如下:
package day06
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月24日10:13:19
* mysql作为数据源
*
* schema信息
* root
* |-- uid: integer (nullable = false)
* |-- xueyuan: string (nullable = true)
* |-- number_one: string (nullable = true)
*/
object JdbcSource {
def main(args: Array[String]): Unit = {
//1.sparkSQL 创建sparkSession
val sparkSession:SparkSession=SparkSession.builder().appName("JdbcSource").master("local[2]").getOrCreate()
//2.加载数据源
val urlData:DataFrame=sparkSession.read.format("jdbc").options(Map(
"url" -> "jdbc:mysql://localhost:3306/url_count",
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "url_data",
"user" -> "root",
"password" -> "199902"
)).load()
//测试
// urlData.printSchema()
// urlData.show()
//3.过滤数据
val fData:Dataset[Row]=urlData.filter(x => {
//uid>2 为何拿到uid?
x.getAs[Int](0) > 2
})
fData.show()
//关闭资源
sparkSession.stop()
}
}
运行结果:

写出各种文件格式,.txt .json .csv ....
代码如下:
package day06
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月24日10:28:36
* 写出各种文件格式,.txt .json .csv ....
*/
object JdbcSource1 {
def main(args: Array[String]): Unit = {
//1.sparkSQL 创建sparkSession
val sparkSession:SparkSession=SparkSession.builder().appName("JdbcSource").master("local[2]").getOrCreate()
//2.加载数据源
val urlData:DataFrame=sparkSession.read.format("jdbc").options(Map(
"url" -> "jdbc:mysql://localhost:3306/url_count",
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "url_data",
"user" -> "root",
"password" -> "199902"
)).load()
//加载隐式类
import sparkSession.implicits._
//3.uid>2
val r: Dataset[Row] = urlData.filter($"uid" >1)
val rs: DataFrame = r.select($"xueyuan",$"number_one")
// val rs1: DataFrame = r.select($"xueyuan")
//写入以文本格式,只能存储一列数据,不然要报错
// rs1.write.text("f:/temp2/SparkSQLSaveText")
//写入以json格式
// rs.write.json("f:/temp2/SparkSQLSaveJson")
//写入以csv
// rs.write.csv("f:/temp2/SparkSQLSaveCSV")
//写入parquet
rs.write.parquet("f:/temp2/SparkSQLSavePar")
// rs1.show()
rs.show()
//关闭资源
sparkSession.stop()
}
}
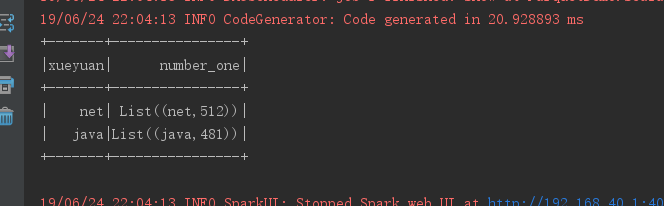
输出为文本格式如下:
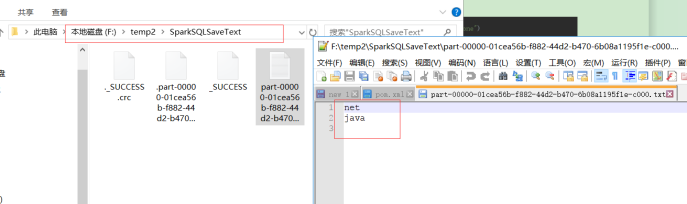
输出为Json格式如下:
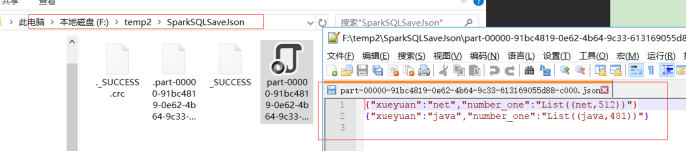
输出为CSV格式如下:
输出为parquet文件:
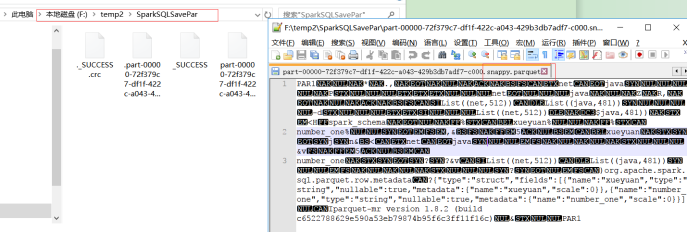
Parquet是一个列格式而且用于多个数据处理系统中。Spark SQL提供支持对于Parquet文件的读写,也就是自动保存原始数据的schema。当写Parquet文件时,所有的列被自动转化为nullable,因为兼容性的缘故。
========================================================
二:读入数据源:
1.CSV文件数据源:
代码如下:
package day06
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月24日11:18:19
*/
object CsvSource {
def main(args: Array[String]): Unit = {
//1.创建sparkSession
val sparkSession: SparkSession = SparkSession.builder().appName("CsvSource").master("local[2]").getOrCreate()
//2.读取csv数据源
val cread: DataFrame = sparkSession.read.csv("f:/temp2/SparkSQLSaveCSV")
//3.处理数据,读取到的数据源没有结构,这里给该数据源一个结构,直接使用toDF()
val cdf: DataFrame = cread.toDF("xueyuan","number_one")
import sparkSession.implicits._
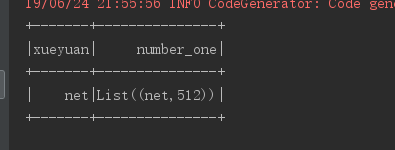
val rs: Dataset[Row] = cdf.filter($"xueyuan" === "net")
rs.show()
sparkSession.stop()
}
}
运行结果如下:
2. Json数据源
代码如下:
package day06
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月24日10:50:09
* 读取json数据源
*/
object JsonSource {
def main(args: Array[String]): Unit = {
//1.创建sparkSession
val sparkSession: SparkSession = SparkSession.builder().appName("JsonSource").master("local[2]").getOrCreate()
//2.读取json数据源
val jread: DataFrame = sparkSession.read.json("f:/temp2/SparkSQLSaveJson")
import sparkSession.implicits._
//3.处理数据
val fread: Dataset[Row] = jread.filter($"xueyuan" === "net")
//4.触发action
fread.show()
//5.关闭资源
sparkSession.stop()
}
}
运行结果如下:
3:读取parquet数据
代码如下:
package day06
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* @author Dawn
* @version 1.0, 2019年6月24日21:59:16
* 读取parquet数据源
* 做了压缩 提高程序运行效率
* MR:压缩
* Hive:压缩
*
* 程序优化
*/
object ParquetDemo {
def main(args: Array[String]): Unit = {
//1.创建sparkSession
val sparkSession:SparkSession=SparkSession.builder().appName("ParquetDemo").master("local[2]").getOrCreate()
//2.读取parquet格式数据
import sparkSession.implicits._
val data: DataFrame = sparkSession.read.parquet("f:/temp2/SparkSQLSavePar")
//3.带有schema信息
// data.printSchema()
// data.show()
//4.计算(需求:过滤出学院是java的)
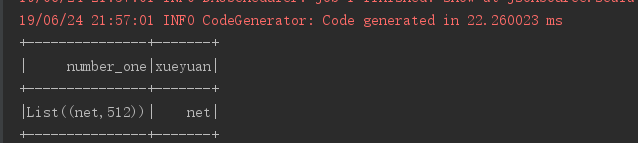
val rs: Dataset[Row] = data.filter($"xueyuan" === "java")
rs.show()
//5.关闭资源
sparkSession.stop()
}
}
运行结果如下: