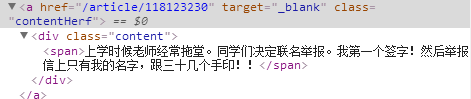
# -*- coding:utf-8 -*- import urllib import urllib2 from bs4 import BeautifulSoup import re import os page = 1 while page<10 : url = 'http://www.qiushibaike.com/hot/page/' + str(page) user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } try: request = urllib2.Request(url,headers = headers) response = urllib2.urlopen(request) qiubai_html = response.read() #print qiubai_html soup = BeautifulSoup(qiubai_html,"html.parser") #print soup.find("a",class_="contentHerf") #print soup.find("a",class_="contenHerf").span.text file = open('imgsrc.txt','a') qiubailist = soup.find_all("a",class_="contentHerf") print 'this is page ',page for x in qiubailist: print x.span.text file.write(x.span.text.encode('utf-8')+' ') print ' ' imgSrclist = soup.find_all("div",class_="thumb") for x in imgSrclist: file.write(x.img['src'].encode('utf-8')+' ') file.close() print soup.find("div",class_="thumb").img['src'] page = page + 1 except urllib2.URLError, e: if hasattr(e,"code"): print e.code if hasattr(e,"reason"): print e.reason