为什么要有三范式
数据库是用来干啥的?毫无疑问主要的工作就是存储数据,本质上就是将数据一点点写入到硬盘上放起来。
但是我们知道,资源不是无限的。硬盘空间大小是有限的,所以你能够存储的数据量是有限的。机器IO能力是有限的,所以程序从数据库读写数据的能力就是有限的。我们没办法让资源无穷无尽,所以我们需要让每一份资源都被充分利用。
因此,在不断地实践中,有人就总结出了 "数据库三范式" 在数据库设计的角度去最大化资源的利用率。遵循三范式的标准,可以比较合理地设计出良好的数据库结构。
三范式分别是什么
我们知道了为什么要遵循三范式,那么三范式又是什么呢?我们逐一来看
1)1NF,表字段的原子性,不可再分
2)2NF,表中的字段必须与主键相关,一张表只负责一件事
3)3NF,表间的关系只存在主键依赖
1NF
第一范式强调的是最细粒度的标准,也就是表字段粒度。它强调字段必须是不可再分的。例如一张地区表:

这张表的address字段是由 省 + 市 + 区 组合而成的,如果我们要修改 省、市、区任何一个,就必须将整个address进行修改。如果一个字段越复杂,那么对这个字段的操作成本就会越高。遵循第一范式,就是消除复合字段,使得字段具备原子性

如上所示,我们将address拆分成了province、city、area三个不可再分字段。当需要修改省、市、区的时候,只需要修改一个字段即可。
从第一范式中我们可以知道,对于数据库最小粒度的操作就是字段,遵循第一范式最基本的目的就是把复合字段拆分成原子字段,降低最小粒度的操作成本。
2NF
当然,只遵循1NF还是不够的。字段存在于一张表中,也就是说字段之间是存在关系的。如果只遵循1NF还是会造成不少问题,比如说

我们在刚刚的地区表中增加了一个user_name字段。从1NF来看,这张新表依然符合标准,因为每个字段依然保留有原子性。
但在2NF的标准里,我们需要从字段的粒度上升到一张单一表的粒度去看。
也就是说,这张表是设计来干啥的?这是一张地区表,id标识着唯一的一个地址,省市区分别指向每个层级,组合起来就是一个地区,这就是这张表存在的意义。而user_name这个字段虽然复合1NF,但是并不应该存在于地区表当中,它可能属于用户信息表。
因此,遵循2NF就是让一张表具备单一的职责,表中的每个字段都必须与主键ID相关。
在1NF中我们是以字段的粒度来考虑操作成本的,那么2NF我们考虑一张表的粒度的操作成本。如果只遵循1NF不遵循2NF的话,一张表可能有多个职责,如

这张表包含了地区和用户信息两个职责,如果修改用户信息我们就不得不考虑到低区数据,同样的修改地区,就不得不考虑到用户信息。比如我想删除了这个用户,那么就会连带地删除了该地区。
所以,当我们的数据库操作粒度上升到一张表的时候,我们需要让一张表内的每个字段都与主键ID密切关系,一张表只负责一件事。我们可以把它拆分成两张表

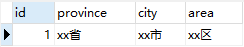
这样一张表的数据操作就不会相互影响。
从2NF中我们可以知道,将不同职责的字段拆分到不同的表中。
3NF
1NF 到 2NF,也就是从字段的粒度上升到了一张表的粒度。那么3NF,就开始考虑表之间的关系了。
2NF中,我们确定了一张表一个职责,以主键ID标识唯一数据。3NF则是把这些表通过主键ID关联起来。同样的,我们考虑一下如果不遵循3NF会有什么问题?

这里有三张表,用户信息表、区域表、以及关联表。关联表特地增加了一个user_name字段,违反3NF,也就是表之间的依赖关系除了主键之外还有非主键字段。
如果我们操作用户信息表,修改了user_name字段,而关联表的user_name字段却没改,这个人的user_name就会出现不一致的情况,在程序表现上也许一会儿是这个名字,一会儿是那个名字,显然这是很诡异的。
如果我同时修改用户信息表和关联表的user_name字段呢?的确可以防止程序上user_name不一致的问题。但是你不得不增加操作成本,如果一个系统里都是这样不遵循3NF的表,那么表的关系将变得非常混乱,最终不可维护造成严重的问题。
从3NF中我们可以知道,减少表之间的字段依赖关系,只通过主键ID来关联可以较为容易地构建出多张结构良好的数据模型。
总结
本文从1NF到3NF,从字段的粒度、表的粒度、表之间的粒度表达三范式分别存在的意义。这里简单总结:
1nf:消除单一字段的复杂度,降低字段的操作成本
2nf:消除单表的复杂度,使得一张表仅有一个职责,不同职责的数据操作互不影响
3nf:消除多表关联的复杂度,使得多表之间仅通过主键依赖,良好组织多表关系