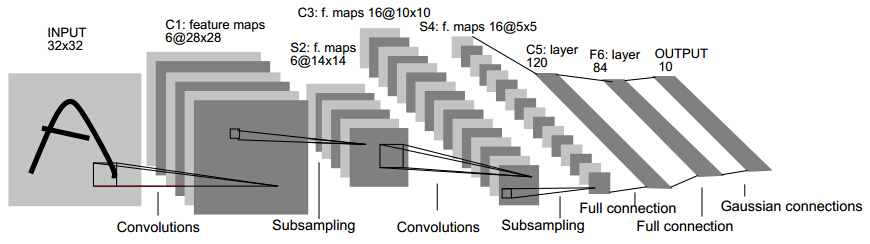
一、Alexnet(2012)
1.网络结构:
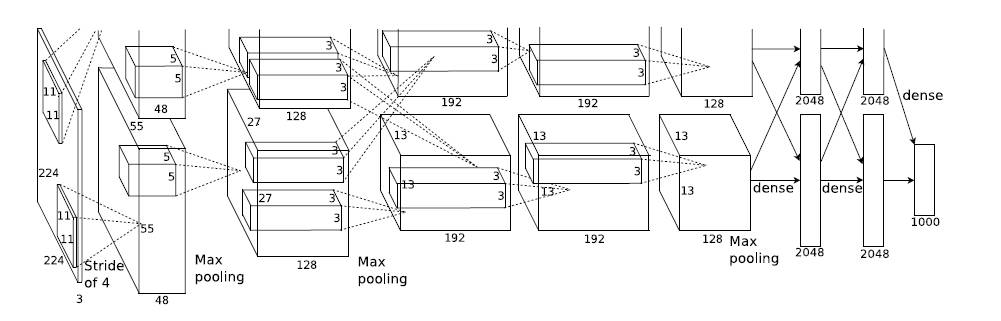
2.意义:
证明了CNN在复杂模型下的有效性,然后GPU实现使得训练在可接受的时间范围内得到结果。
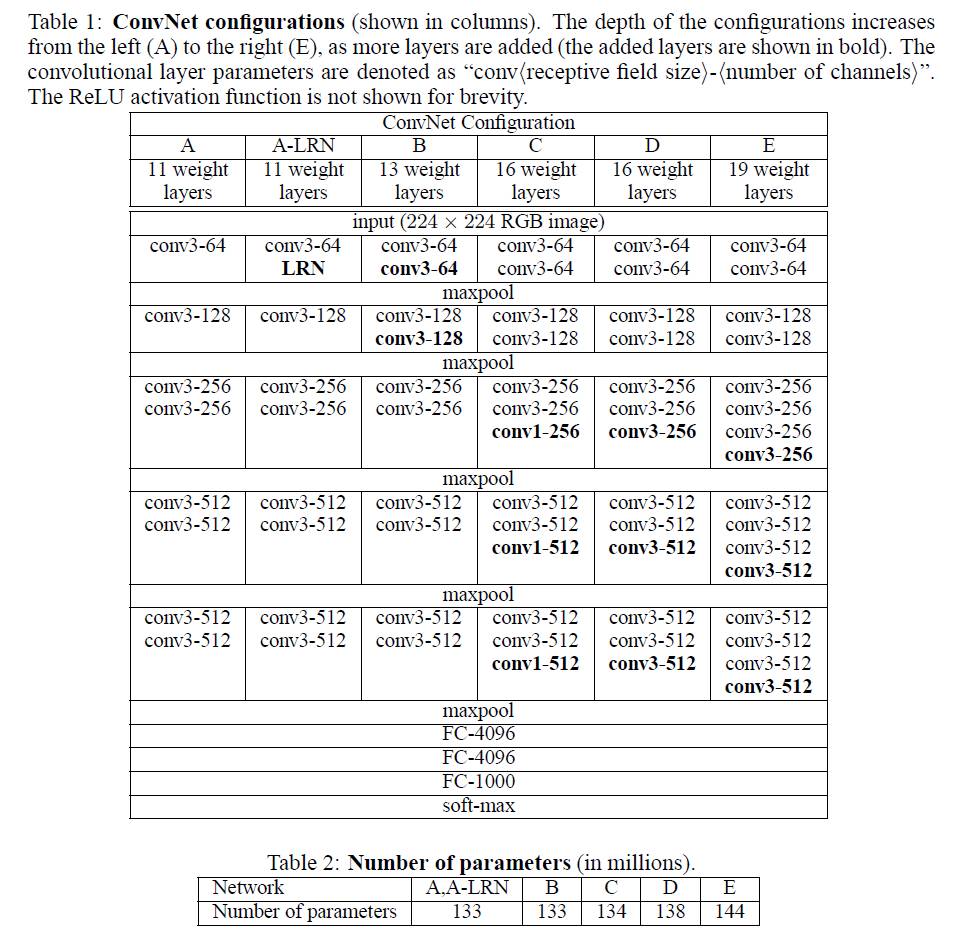
二、VGG(由Alexnet发展而来,2014)
1.结构:
三、Inception(2014)
1.思想:(能够加宽网络获取不同特征的同时不增加计算量)
2.演变:
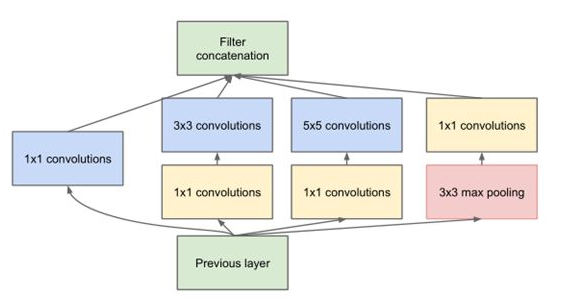
(1)Inception(GoogleNet)
思想:在同一层用不同大小的卷积核获得不同尺度的信息,用1*1的卷积进行降维,并把他们按通道堆叠起来。
结构:
(2)Inception V2:
在1的基础上,做了以下改进:
使用BN层(可以使每层数据分布一致,使网络专注学习特征,而不是学习数据变化的差异);
使用两个3*3的卷积核代替一个5*5的卷积(在保持相同感受野的情况下,减少了参数,还增加了网络的深度);
用1*n和n*1这种非对称的卷积代替原本对称的卷积(减少了参数,增加了深度);
(3)Inception V3:
改进的初衷:池化再Inception降低了网络表达能力,Inception再池化则增加了网络参数,所以采用卷积核池化同时的方式。
在2的基础上做了如下改进:
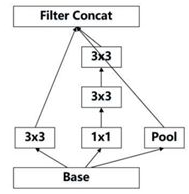
(4)Inception V4:
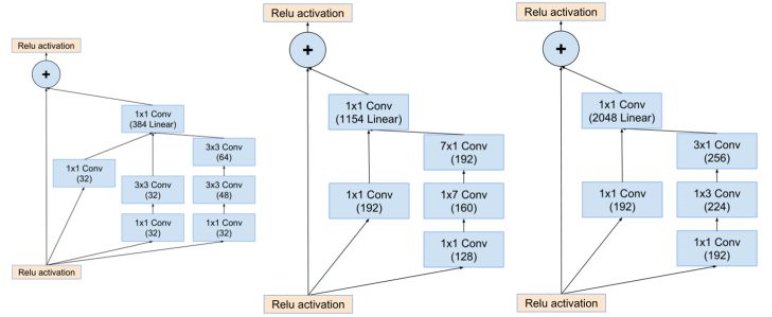
改进:卷积核池化各种搭配整合
(5)Inception-Resnet:
3.参考:
https://www.sohu.com/a/166062301_465914
https://www.cnblogs.com/yifdu25/p/8542740.html
四、Resnet(2015)
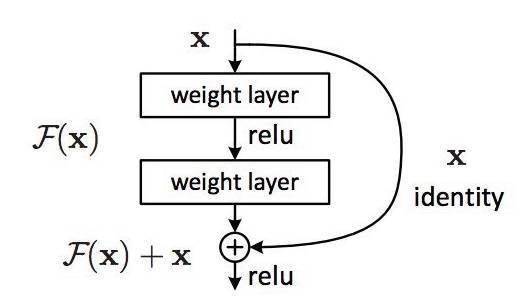
1.思想:(能够加深网络)
直接学习映射是比较难的,那么不再学习X-H(X)到直接映射,而是学习两者之间的差异,为了计算H(x),只要用原始项加上残差项即可。
如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低。
2.网络结构:
基础残差块:
3.参考:
https://www.sohu.com/a/166062301_465914
https://blog.csdn.net/lanran2/article/details/79057994
https://blog.csdn.net/legend_hua/article/details/79876168
五、ZF(2013):
1.对Alenet进行少许改进。
2.参考:http://ziyubiti.github.io/2016/11/27/cnnnet/
六、Lenet(1998):
1.网络结构: