一 前言
Word2Vec是同上一篇提及的PageRank一样,都是Google的工程师和机器学习专家所提出的的;在学习这些算法、模型的时候,最好优先去看Google提出者的原汁Paper和Project,那样带来的启发将更大。因为创造者对自己所创之物的了解程度优于这世上的绝大部分者,这句话,针对的是爱看博文的读者,like me。
另外,补充几句。
1.防止又被抄袭,故关键笔记以图贴之。
2.标题前带阿拉伯数字标号的内容,便是使用Gensim的Word2Vec模型过程中的完整流程序号,通常也较为常用且重要。
二 鸣谢
感谢如下文章/论文的详细描述,它们亦是本文的主要测试依据,尤其需要感谢最后四篇博文的精彩解说。
- Word2Vec Introduction - Google - [推荐]
- Gensim - Word2Vec - Github
- Gensim - Github
- 基于 Gensim 的 Word2Vec 实践
- 翻译Gensim的word2vec说明
- Gensim之Word2Vec使用手册 - [推荐]
- word2vec词向量中文语料处理(python gensim word2vec总结)
三 Word2Vec 概要
重要API/类
- gensim.models.KeyedVectors
- gensim.models.word2vec
- gensim.models.word2vec.Word2Vec(sentences,min_count,size,worker)
- gensim.models.Word2Vec(sentences,min_count,size,worker)
Word2Vec类:构建Word2Vec词向量模型

四 Word2Vec 详解
- 注:标题前带阿拉伯数字标号的内容,便是使用Gensim的Word2Vec模型过程中的完整流程序号,通常也较为常用且重要。
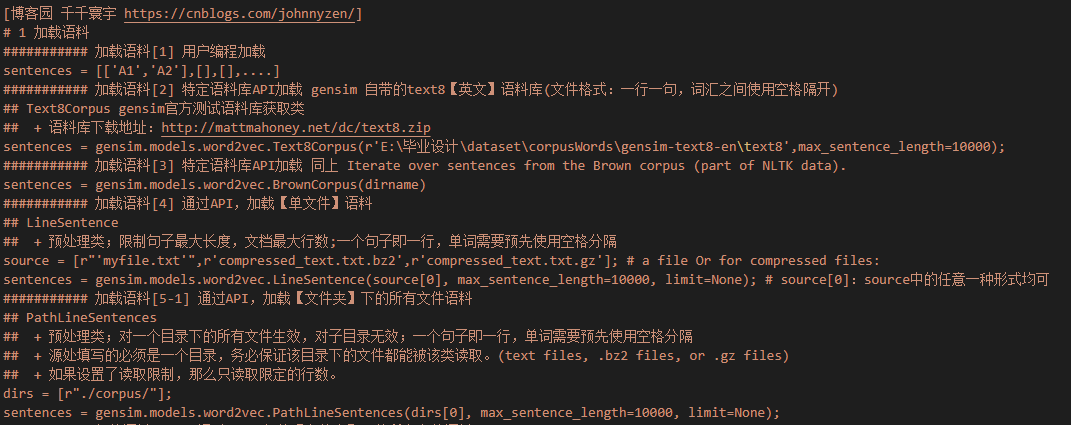
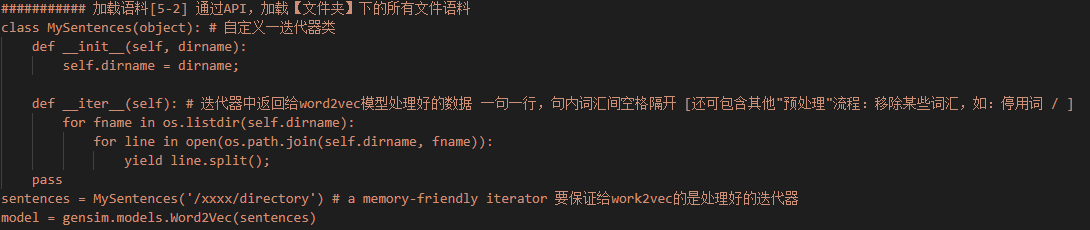
1 加载语料库
2 (初次)训练

手动构建词汇表

3 追加训练(更新模型)

4 存储模型

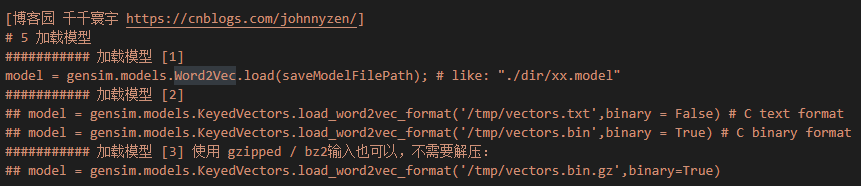
5 加载模型
6 获取词向量

加载词向量

7 模型应用

8 模型评估

五 补充
- 欢迎探讨,欢迎Follow~