一、JDK安装
JDK官网下载:https://www.oracle.com
1.创建软件存放目录
[root@hadoop100 ~]# mkdir /data/software/
[root@hadoop100 ~]# cd /data/software/
2.上传JDK安装包
[root@hadoop100 /data/software]# rz
[root@hadoop100 /data/software]# ll
total 206884
-rw-r--r--. 1 root root 185540433 2021-07-12 09:42 jdk-8u131-linux-x64.tar.gz
3.解压安装包
[root@hadoop100 /data/software]# tar xf jdk-8u131-linux-x64.tar.gz -C /opt
[root@hadoop100 /data/software]# cd /opt/
[root@hadooop100 ~]# ll
total 0
drwxr-xr-x. 8 10 143 255 2021-03-15 16:35 jdk1.8.0_131
4.做软连接
[root@hadooop100 ~]# ln -s jdk1.8.0_131 jdk
[root@hadooop100 ~]# ll
total 0
lrwxrwxrwx. 1 root root 12 2021-07-12 09:43 jdk -> jdk1.8.0_131
drwxr-xr-x. 8 10 143 255 2021-03-15 16:35 jdk1.8.0_131
5.配置环境变量
[root@hadooop100 ~]# vim /etc/profile.d/java.sh
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
6.刷新环境变量
[root@hadooop100 ~]# source /etc/profile.d/java.sh
7.验证JDK
[root@hadoop100 /opt]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
二、SSH配置免密登录
#1.若没有该目录,可以创建
[root@hadoop100 ~/.ssh]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
68.79.16.69 hadoop100
[root@hadoop100 ~]# cd ~/.ssh/
#2.会有提示,一路按回车就可以
[root@hadoop100 ~/.ssh]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:ka+QA6wxsf+MdkstlnbIT2sVwqGV7q1lU9RNy2KKjDY root@hadoop100
The key's randomart image is:
+---[RSA 2048]----+
| . . . o.|
| + +. . o o|
| + o =o. . o o |
| = ...*oo + . |
| . . +ES=.+ |
| =.*o.* |
| o % == . |
| . = *o. |
| ..o |
+----[SHA256]-----+
#3.添加免密
[root@hadoop100 ~/.ssh]# cat ./id_rsa.pub >> ./authorized_keys
#4.测试免密登录
[root@hadoop100 ~/.ssh]# ssh root@hadoop100
The authenticity of host 'hadoop100 (fe80::20c:29ff:fef5:98f9%eth0)' can't be established.
ECDSA key fingerprint is SHA256:g6buQ4QMSFl+5MMAh8dTCmLtkIfdT8sgRFYc6uCzV3c.
ECDSA key fingerprint is MD5:5f:d7:ad:07:e8:fe:d2:49:ec:79:2f:d4:91:59:c5:03.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop100,fe80::20c:29ff:fef5:98f9%eth0' (ECDSA) to the list of known hosts.
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
Last login: Mon Aug 30 11:24:23 2021 from ::1
[root@hadoop100 ~]#
三、Hadoop安装
Hadoop官网下载地址:https://hadoop.apache.org/releases.html
1.下载安装包
[root@hadooop100 ~]# cd /data/software/
[root@hadooop100 /data/software]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
[root@hadooop100 /data/software]# ll
总用量 1398724
-rw-r--r-- 1 root root 605187279 6月 15 17:55 hadoop-3.3.1.tar.gz
2.解压安装包
[root@hadooop100 /data/software]# tar xf hadoop-3.3.1.tar.gz -C /opt/
[root@hadooop100 /data/software]# cd /opt/
[root@hadooop100 /opt]# ll
总用量 0
drwxr-xr-x 10 centos centos 215 6月 15 13:52 hadoop-3.3.1
3.做软连接
[root@hadooop100 /opt]# ln -s hadoop-3.3.1 hadoop
[root@hadooop100 /opt]# ll
总用量 0
lrwxrwxrwx 1 root root 12 8月 13 15:01 hadoop -> hadoop-3.3.1
drwxr-xr-x 10 centos centos 215 6月 15 13:52 hadoop-3.3.1
4.配置环境变量
[root@hadooop100 /opt]# vim /etc/profile.d/hadoop.sh
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
5.刷新环境变量
[root@hadoop100 /opt]# source /etc/profile.d/hadoop.sh
6.验证hadoop
[root@hadoop100 /opt]# hadoop version
Hadoop 3.3.1
Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2
Compiled by ubuntu on 2021-06-15T05:13Z
Compiled with protoc 3.7.1
From source with checksum 88a4ddb2299aca054416d6b7f81ca55
This command was run using /opt/hadoop-3.3.1/share/hadoop/common/hadoop-common-3.3.1.jar
四、Hadoop目录结构
1.查看Hadoop目录结构
[root@hadoop100 /opt]# cd /opt/hadoop
[root@hadoop100 /opt/hadoop]# ll
总用量 112
drwxr-xr-x. 2 nexus nexus 4096 2021-06-15 13:52 bin
drwxr-xr-x. 3 nexus nexus 4096 2021-06-15 13:15 etc
drwxr-xr-x. 2 nexus nexus 4096 2021-06-15 13:52 include
drwxr-xr-x. 3 nexus nexus 4096 2021-06-15 13:52 lib
drwxr-xr-x. 4 nexus nexus 4096 2021-06-15 13:52 libexec
-rw-rw-r--. 1 nexus nexus 23450 2021-06-15 13:02 LICENSE-binary
drwxr-xr-x. 2 nexus nexus 4096 2021-06-15 13:52 licenses-binary
-rw-rw-r--. 1 nexus nexus 15217 2021-06-15 13:02 LICENSE.txt
-rw-rw-r--. 1 nexus nexus 29473 2021-06-15 13:02 NOTICE-binary
-rw-rw-r--. 1 nexus nexus 1541 2021-05-22 00:11 NOTICE.txt
-rw-rw-r--. 1 nexus nexus 175 2021-05-22 00:11 README.txt
drwxr-xr-x. 3 nexus nexus 4096 2021-06-15 13:15 sbin
drwxr-xr-x. 4 nexus nexus 4096 2021-06-15 14:18 share
2.重要目录含义
1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
4)sbin目录:存放启动或停止Hadoop相关服务的脚本
5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
五、Hadoop配置
1.备份Hadoop配置
配置Hadoop,共需要配置5个文件(另外可选地配置workers文件),均位于Hadoop安装目录下的"etc/hadoop/"子目录下。首先进入到该目录下:
[root@hadooop100 /opt]# cd /opt/hadoop/etc/hadoop/
[root@hadooop100 /opt/hadoop/etc/hadoop]# cp hadoop-env.sh hadoop-env.sh.bak
[root@hadooop100 /opt/hadoop/etc/hadoop]# cp core-site.xml core-site.xml.bak
[root@hadooop100 /opt/hadoop/etc/hadoop]# cp hdfs-site.xml hdfs-site.xml.bak
[root@hadooop100 /opt/hadoop/etc/hadoop]# cp mapred-site.xml mapred-site.xml.bak
[root@hadooop100 /opt/hadoop/etc/hadoop]# cp yarn-site.xml yarn-site.xml.bak
[root@hadoop100 /opt/hadoop/etc/hadoop]# cp workers workers.bak
2.修改Hadoop配置
[root@hadooop100 /opt/hadoop/etc/hadoop]# vim hadoop-env.sh
export JAVA_HOME=/opt/jdk
export HDFS_DATANODE_USER=root
[root@hadooop100 /opt/hadoop/etc/hadoop]# vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:8020/</value>
<description>HDFS的URI,文件系统://namenode标识:端口号--></description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
<description>配置HDFS网页登录使用的静态用户为root</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description>配置root用户允许通过代理访问的主机节点</description>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description>配置root用户允许代理的用户所属组</description>
</property>
</configuration>
[root@hadooop100 /opt/hadoop/etc/hadoop]# vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop100:9870</value>
<description>nn web端访问地址</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop100:9868</value>
<description> 2nn web端访问地址</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/dfs/name</value>
<description>存放hadoop的名称节点namenode里的metadata</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dfs/data</value>
<description>存放HDFS文件系统数据文件的目录</description>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
<description>HDFS数据节点文件数量上限</description>
</property>
</configuration>
[root@hadooop100 /opt/hadoop/etc/hadoop]# vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定MapReduce程序运行在Yarn上</description>
</property>
</configuration>
[root@hadooop100 /opt/hadoop/etc/hadoop]# vim yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>指定MR走shuffle</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop100</value>
<description>指定ResourceManager的地址</description>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
<description>环境变量的继承</description>
</property>
</configuration>
[root@hadoop100 /opt/hadoop/etc/hadoop]# vim workers
hadoop100
[root@hadooop100 ~]# cd /opt/hadoop/sbin/
# 1.对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# 1.对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
六、创建配置文件目录
[root@hadooop100 ~]# mkdir -p /data/hadoop/tmp
[root@hadooop100 ~]# mkdir -p /data/hadoop/hdfs
[root@hadooop100 ~]# mkdir -p /data/hadoop/dfs/date
[root@hadooop100 ~]# mkdir -p /data/hadoop/dfs/name
七、启动Hadoop
1.格式化HDFS文件系统
格式化是对 HDFS这个分布式文件系统中的 DataNode 进行分块,统计所有分块后的初始元数据的存储在namenode中。(如果服务器再次启动,也需要进行这步,否则启动可能会失败)
[root@hadoop100 ~]# hdfs namenode -format
2.Hadoop上执行MR程序
#1.启动HDFS
[root@hadoop100 ~]# start-dfs.sh
Starting namenodes on [hadoop100]
Last login: Mon Aug 30 11:24:37 CST 2021 from fe80::20c:29ff:fef5:98f9%eth0 on pts/1
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
hadoop100: Warning: Permanently added the ECDSA host key for IP address '10.0.0.100' to the list of known hosts.
Starting datanodes
Last login: Mon Aug 30 11:53:39 CST 2021 on pts/0
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
Starting secondary namenodes [hadoop100]
Last login: Mon Aug 30 11:53:42 CST 2021 on pts/0
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
#2.使用jps查看是否启动成功
[root@hadoop100 ~]# jps
26594 Jps
26115 NameNode
26243 DataNode
26445 SecondaryNameNode
3.启动yarn
#1.启动yarn
[root@hadoop100 ~]# start-yarn.sh
Starting resourcemanager
Last login: Mon Aug 30 11:53:57 CST 2021 on pts/0
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
Starting nodemanagers
Last login: Mon Aug 30 11:54:47 CST 2021 on pts/0
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
#2.使用jps查看是否启动成功
[root@hadoop100 ~]# jps
26849 NodeManager
26115 NameNode
26243 DataNode
26932 Jps
26728 ResourceManager
26445 SecondaryNameNode
八、测试Web登录
#1.在本地windows上的C:WindowsSystem32driversetc下有个hosts文件,修改hosts文件,增加以下内容:
68.79.16.69 hadoop100
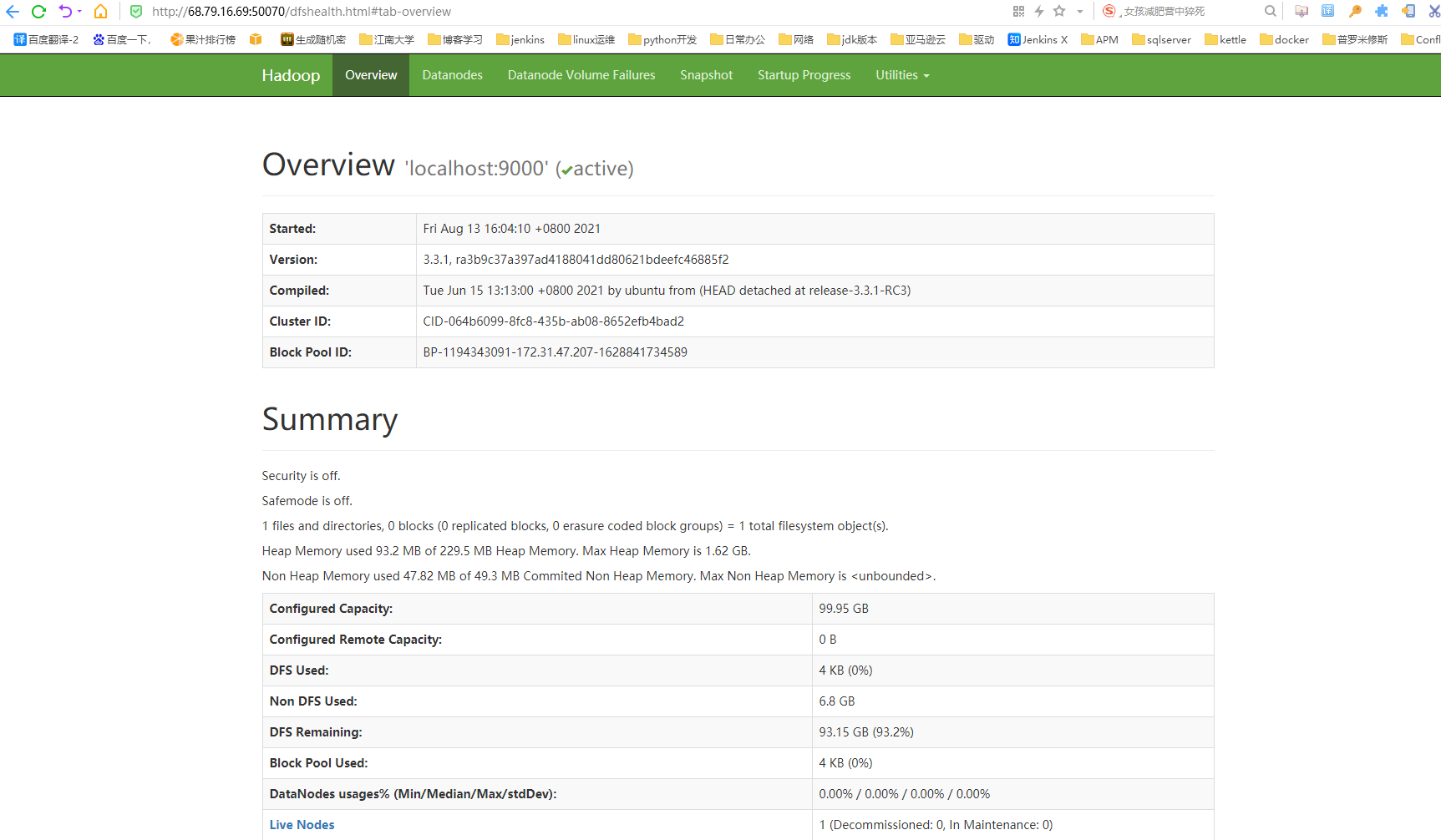
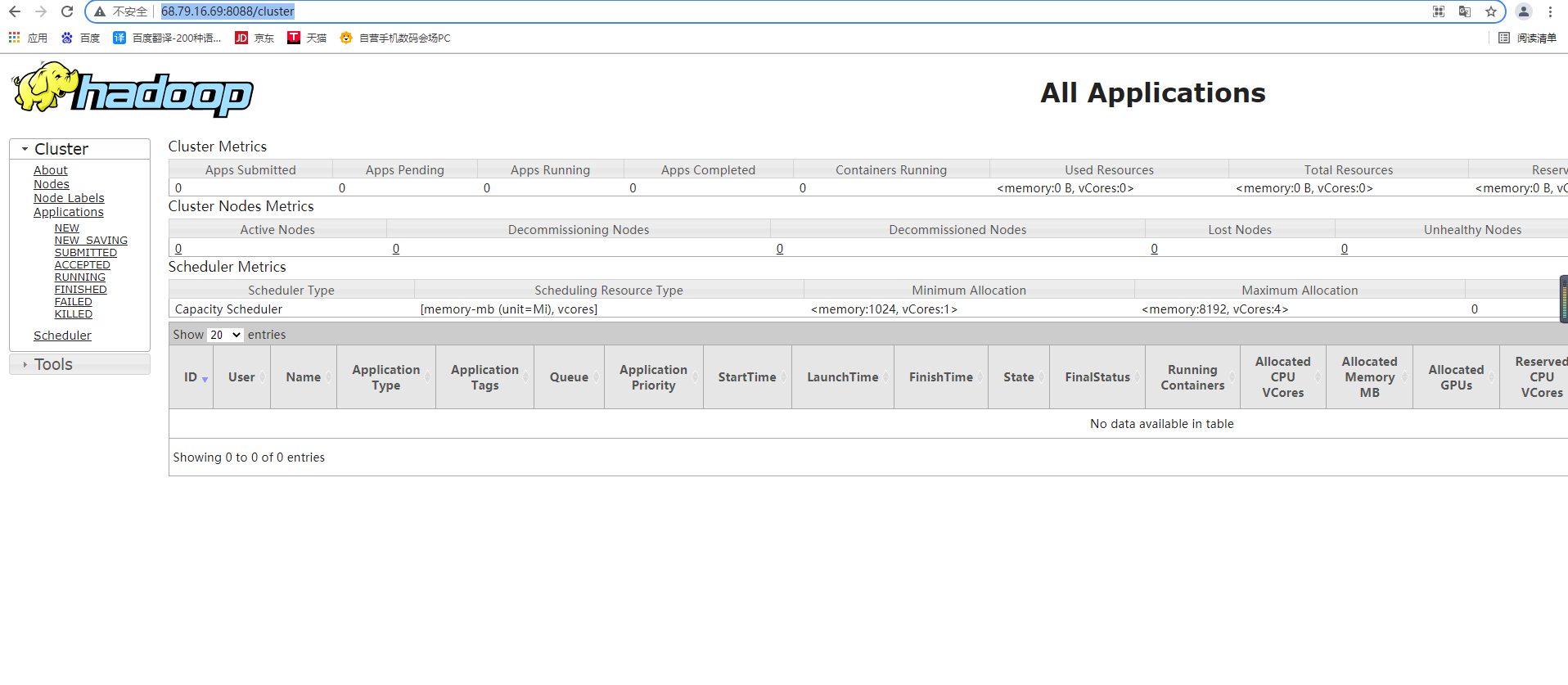
#2.查看HDFS和YARN的web界面
http://主机IP:9870 查看hdfs是否OK
http://主机IP:8088 查看yarn是否OK
本机URL:
http://68.79.16.69:9870/dfshealth.html#tab-overview
http://68.79.16.69:8088/cluster
九、Hadoop基本测试
1.新建小文件
[root@hadoop100 ~]# vim /data/software/1.txt
c 是世界上最好的语言!
java 是世界上最好的语言!
python 是世界上最好的语言!
go 是世界上最好的语言!
2.上传文件到Hadoop
#1.新建上传目录
[root@hadoop100 ~]# hadoop fs -mkdir /input
#2.上传小文件
[root@hadoop100 ~]# hadoop fs -put /data/software/1.txt /input
#3.上传大文件
[root@hadoop100 ~]# hadoop fs -put /data/software/jdk-8u131-linux-x64.tar.gz /input
3.校验文件一致性
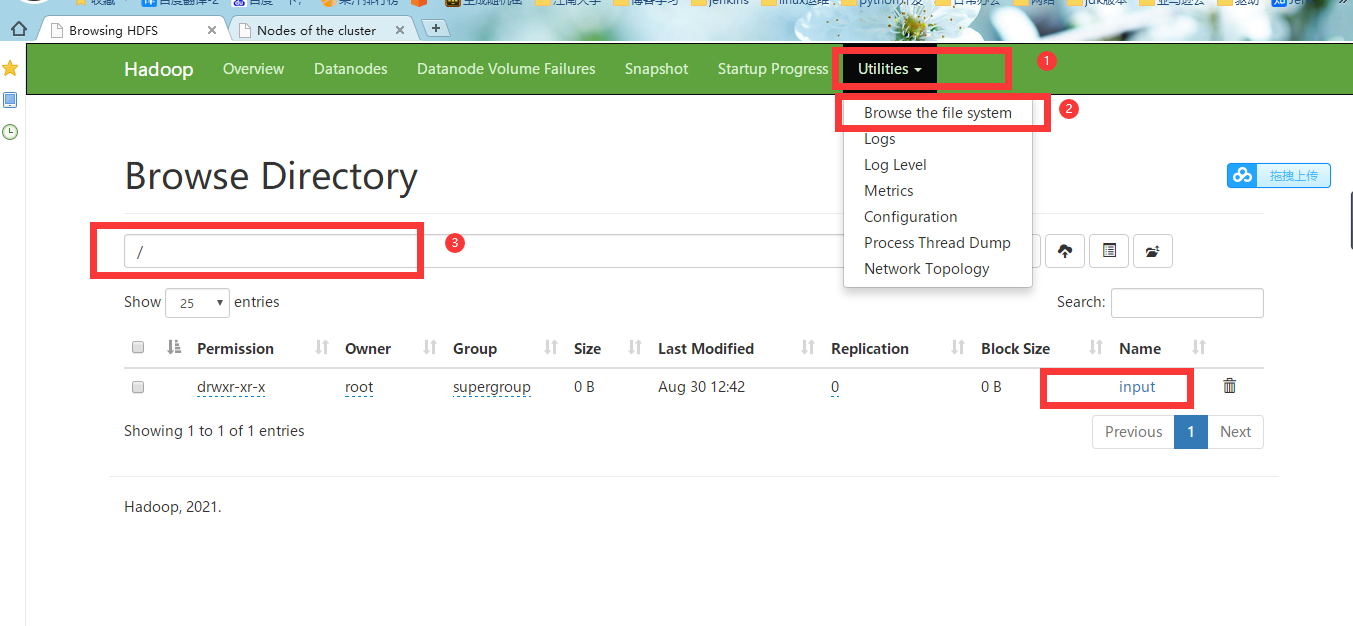
#1.登录HDFS的Web界面,
http://68.79.16.69:9870/dfshealth.html#tab-overview
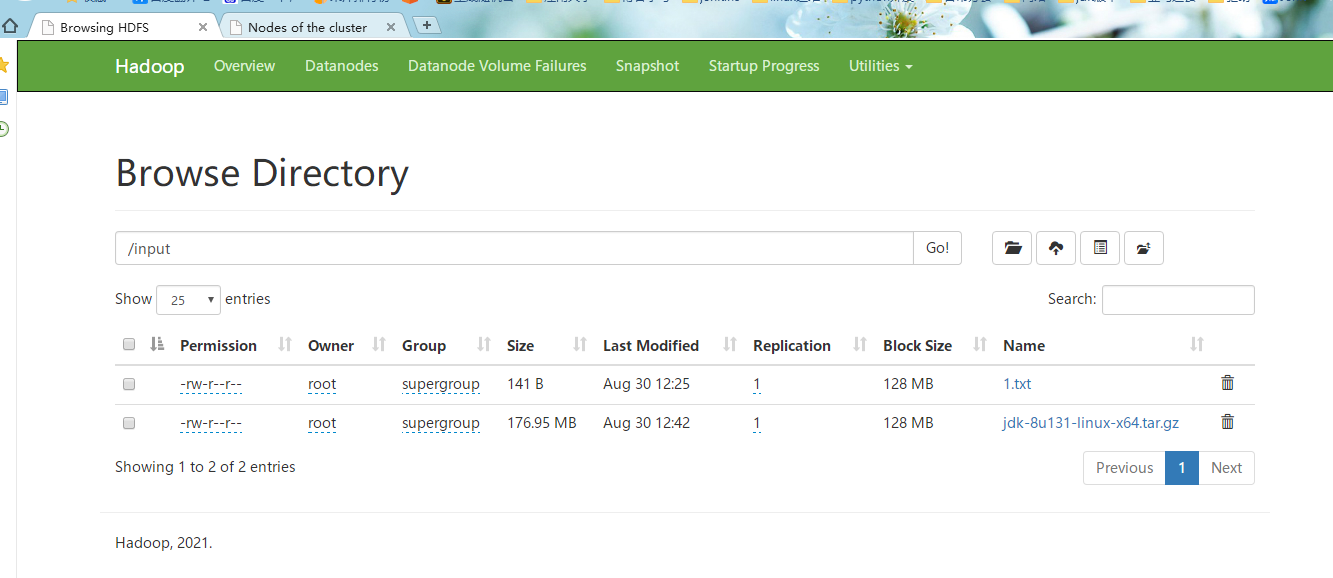
点击Utilities --> Browse the file system --> 选择 Browse Directory为/ 这里可以看到我们之前新建的上传目录
#2.点击input,可以看到我们上传的两个文件1.txt和jdk的安装包
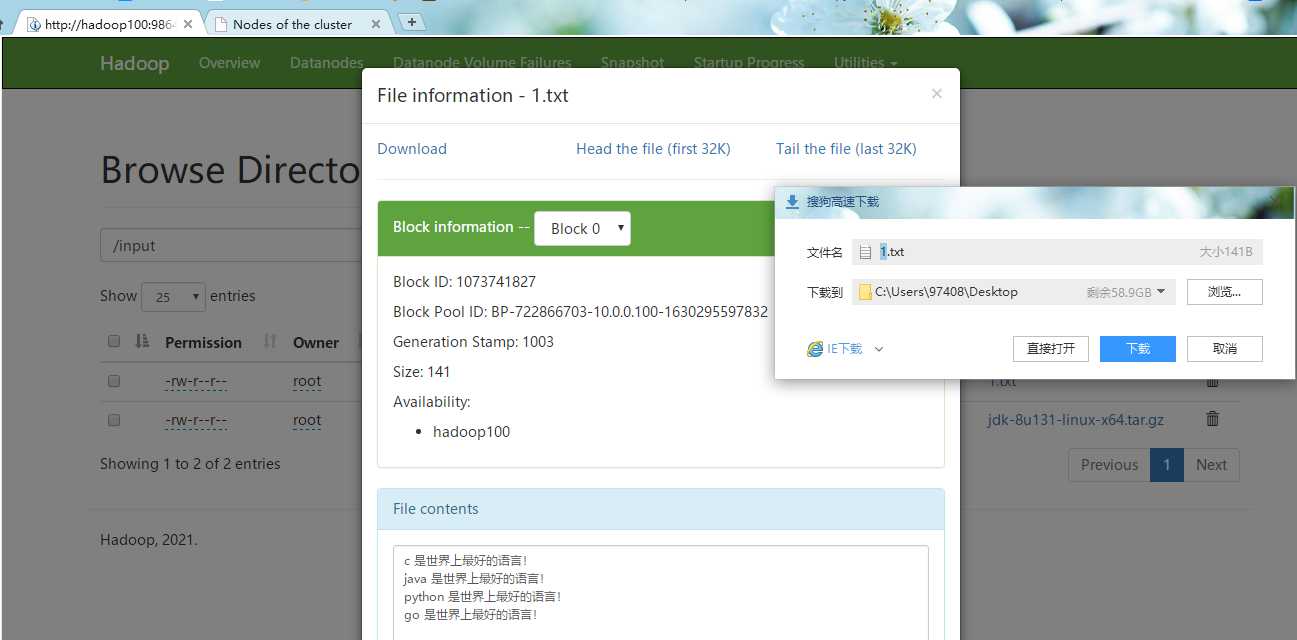
#3.点击上传的文件,查看文件信息,点击Download可以正常下载,点击Tail the file可以看到文件内容
十、配置历史服务器
1.配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。完整步骤如下:
[root@hadoop100 /opt/hadoop/etc/hadoop]# vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定MapReduce程序运行在Yarn上</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop100:10020</value>
<description>历史服务器端地址</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop100:19888</value>
<description>历史服务器web端地址</description>
</property>
</configuration>
2.启动历史服务器
#1.在hadoop100启动历史服务器
[root@hadoop100 /opt/hadoop/etc/hadoop]# mapred --daemon start historyserver
#2.查看历史服务器是否启动
[root@hadoop100 /opt/hadoop/etc/hadoop]# jps
26849 NodeManager
26115 NameNode
26243 DataNode
26728 ResourceManager
29017 JobHistoryServer
26445 SecondaryNameNode
29039 Jps
#3.查看JobHistory
http://hadoop100:19888/jobhistory
3. 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer,完整配置如下:
[root@hadoop100 /opt/hadoop/etc/hadoop]# vim yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>指定MR走shuffle</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop100</value>
<description>指定ResourceManager的地址</description>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME
,HADOOP_MAPRED_HOME</value>
<description>环境变量的继承</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚集功能</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop100:19888/jobhistory/logs</value>
<description>设置日志聚集服务器地址</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
<description>设置日志保留时间为7天</description>
</property>
</configuration>
4.重启NodeManager 、ResourceManager和HistoryServer
#1.关闭NodeManager 、ResourceManager和HistoryServer
[root@hadoop100 /opt/hadoop/etc/hadoop]# stop-yarn.sh
Stopping nodemanagers
Last login: Mon Aug 30 11:54:49 CST 2021 on pts/0
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
Stopping resourcemanager
Last login: Mon Aug 30 15:09:21 CST 2021 on pts/0
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
[root@hadoop100 /opt/hadoop/etc/hadoop]# mapred --daemon stop historyserver
#2.启动NodeManager 、ResourceManager和HistoryServer
[root@hadoop100 /opt/hadoop/etc/hadoop]# start-yarn.sh
Starting resourcemanager
Last login: Mon Aug 30 15:09:25 CST 2021 on pts/0
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
Starting nodemanagers
Last login: Mon Aug 30 15:09:59 CST 2021 on pts/0
Last failed login: Mon Aug 30 17:24:51 CST 2021 on tty1
There was 1 failed login attempt since the last successful login.
[root@hadoop100 /opt/hadoop/etc/hadoop]# mapred --daemon start historyserver
5.执行WordCount程序
#1.执行WordCount程序
[root@hadoop100 /opt/hadoop/etc/hadoop]# cd /opt/hadoop
[root@hadoop100 /opt/hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
2021-08-30 15:22:57,111 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop100/10.0.0.100:8032
2021-08-30 15:22:58,773 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1630308143240_0001
2021-08-30 15:22:59,587 INFO input.FileInputFormat: Total input files to process : 2
2021-08-30 15:23:00,569 INFO mapreduce.JobSubmitter: number of splits:2
2021-08-30 15:23:01,548 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1630308143240_0001
2021-08-30 15:23:01,548 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-08-30 15:23:02,222 INFO conf.Configuration: resource-types.xml not found
2021-08-30 15:23:02,223 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-08-30 15:23:03,506 INFO impl.YarnClientImpl: Submitted application application_1630308143240_0001
2021-08-30 15:23:03,743 INFO mapreduce.Job: The url to track the job: http://hadoop100:8088/proxy/application_1630308143240_0001/
2021-08-30 15:23:03,743 INFO mapreduce.Job: Running job: job_1630308143240_0001
2021-08-30 15:23:29,788 INFO mapreduce.Job: Job job_1630308143240_0001 running in uber mode : false
2021-08-30 15:23:29,790 INFO mapreduce.Job: map 0% reduce 0%
2021-08-30 15:23:55,714 INFO mapreduce.Job: map 50% reduce 0%
2021-08-30 15:24:04,985 INFO mapreduce.Job: map 52% reduce 0%
2021-08-30 15:24:11,140 INFO mapreduce.Job: map 54% reduce 0%
2021-08-30 15:24:17,249 INFO mapreduce.Job: map 56% reduce 0%
2021-08-30 15:24:28,507 INFO mapreduce.Job: map 56% reduce 17%
2021-08-30 15:24:35,597 INFO mapreduce.Job: map 57% reduce 17%
2021-08-30 15:24:41,779 INFO mapreduce.Job: map 59% reduce 17%
2021-08-30 15:24:53,962 INFO mapreduce.Job: map 60% reduce 17%
2021-08-30 15:25:00,080 INFO mapreduce.Job: map 63% reduce 17%
2021-08-30 15:25:06,230 INFO mapreduce.Job: map 66% reduce 17%
2021-08-30 15:25:12,421 INFO mapreduce.Job: map 67% reduce 17%
2021-08-30 15:25:18,564 INFO mapreduce.Job: map 70% reduce 17%
2021-08-30 15:25:24,668 INFO mapreduce.Job: map 71% reduce 17%
2021-08-30 15:25:30,757 INFO mapreduce.Job: map 72% reduce 17%
2021-08-30 15:25:36,898 INFO mapreduce.Job: map 74% reduce 17%
2021-08-30 15:25:49,063 INFO mapreduce.Job: map 75% reduce 17%
2021-08-30 15:25:55,215 INFO mapreduce.Job: map 77% reduce 17%
2021-08-30 15:26:06,378 INFO mapreduce.Job: map 79% reduce 17%
2021-08-30 15:26:13,472 INFO mapreduce.Job: map 80% reduce 17%
2021-08-30 15:26:19,560 INFO mapreduce.Job: map 81% reduce 17%
2021-08-30 15:26:25,686 INFO mapreduce.Job: map 83% reduce 17%
2021-08-30 15:26:37,848 INFO mapreduce.Job: map 85% reduce 17%
2021-08-30 15:26:43,944 INFO mapreduce.Job: map 87% reduce 17%
2021-08-30 15:26:50,050 INFO mapreduce.Job: map 91% reduce 17%
2021-08-30 15:26:56,122 INFO mapreduce.Job: map 95% reduce 17%
2021-08-30 15:27:02,390 INFO mapreduce.Job: map 99% reduce 17%
2021-08-30 15:27:04,436 INFO mapreduce.Job: map 100% reduce 17%
2021-08-30 15:27:13,258 INFO mapreduce.Job: map 100% reduce 73%
2021-08-30 15:27:19,624 INFO mapreduce.Job: map 100% reduce 87%
2021-08-30 15:27:24,733 INFO mapreduce.Job: map 100% reduce 100%
2021-08-30 15:27:27,763 INFO mapreduce.Job: Job job_1630308143240_0001 completed successfully
2021-08-30 15:27:28,727 INFO mapreduce.Job: Counters: 55
File System Counters
FILE: Number of bytes read=1007491124
FILE: Number of bytes written=1507738868
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=185540791
HDFS: Number of bytes written=478073828
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Killed map tasks=1
Launched map tasks=3
Launched reduce tasks=1
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=410756
Total time spent by all reduces in occupied slots (ms)=207107
Total time spent by all map tasks (ms)=410756
Total time spent by all reduce tasks (ms)=207107
Total vcore-milliseconds taken by all map tasks=410756
Total vcore-milliseconds taken by all reduce tasks=207107
Total megabyte-milliseconds taken by all map tasks=420614144
Total megabyte-milliseconds taken by all reduce tasks=212077568
Map-Reduce Framework
Map input records=3302326
Map output records=8866577
Map output bytes=563183844
Map output materialized bytes=499429681
Input split bytes=217
Combine input records=13805281
Combine output records=9584411
Reduce input groups=4645704
Reduce shuffle bytes=499429681
Reduce input records=4645707
Reduce output records=4645704
Spilled Records=14230118
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=2649
CPU time spent (ms)=95210
Physical memory (bytes) snapshot=767778816
Virtual memory (bytes) snapshot=7587844096
Total committed heap usage (bytes)=608534528
Peak Map Physical memory (bytes)=392065024
Peak Map Virtual memory (bytes)=2529935360
Peak Reduce Physical memory (bytes)=164405248
Peak Reduce Virtual memory (bytes)=2533318656
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=185540574
File Output Format Counters
Bytes Written=478073828
#2.登录历史服务器地址
http://hadoop100:19888/jobhistory,查看到历史任务列表
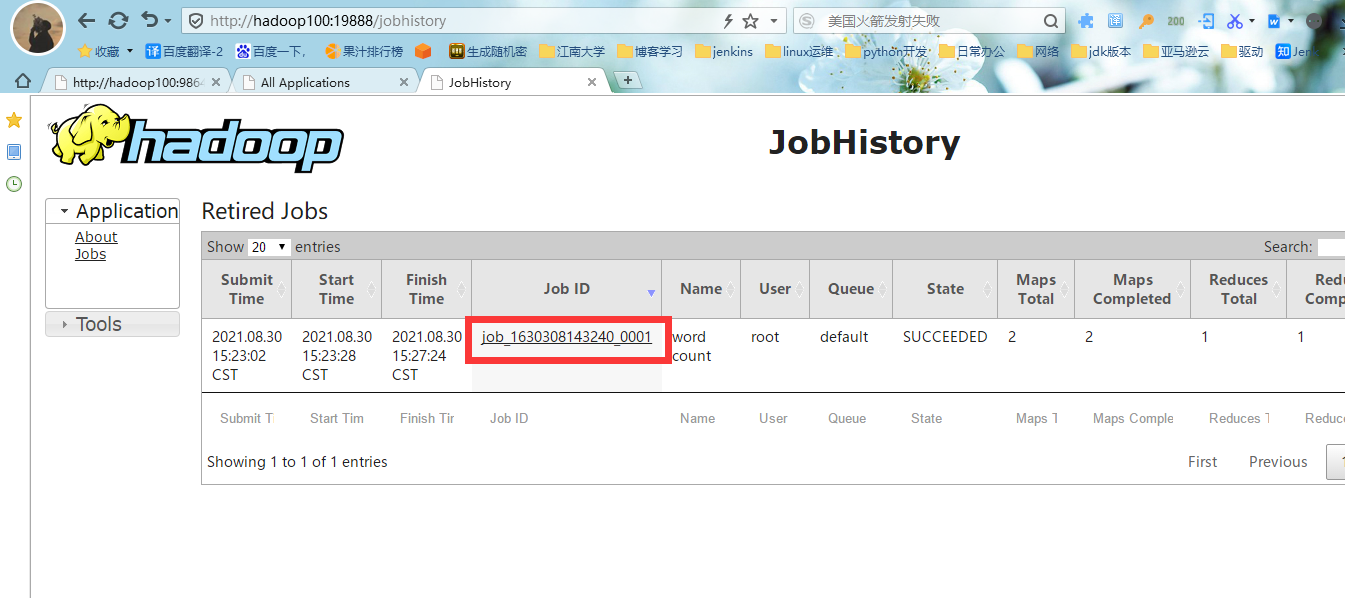
#3.查看任务运行日志
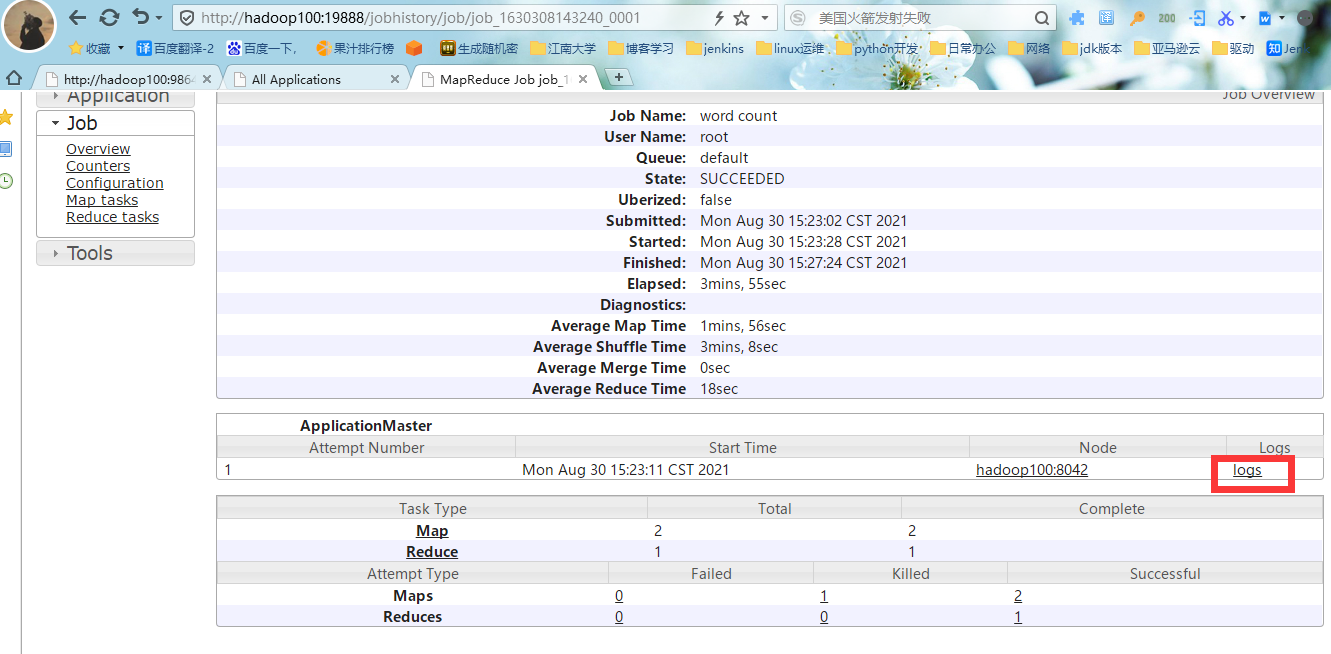
#4.运行日志详情,至此Hadoop本地部署完成。