前言:
很多应用会用到磁盘,磁盘是一种比较好的持久化工具,例如:MQ,MySql,Log等都会用到磁盘,所以磁盘性能的优化显得比较重要,这部分的知识的学习也是必要的;磁盘用的好的时候,其实速度也是很快的,下面开始介绍一种磁盘常用技术,零拷贝
概念:
DMA:直存储器访问,其实很多和内存交互并不需要CPU的,可以通过硬件的支持直接从外设和内存交互,就是DMA技术;
用户态:程序控制权在用户代码上,注意,切换到用户态是具有一定的代价的;
内核态:程序控制权在操作系统代码上,注意,切换到内核态也是具有一定的代价的;
页缓存:(page cache),文件映射到内存的一个单位,一页一般是4096kb,mmap和普通的read都是要用页缓存;
问题:
假设我们需要读取磁盘文件到网络,我们可能会写以下代码:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
这段代码,看着简单,实际上代价是很大的,其中就包括了4次内存的拷贝,如下图所示:
- 首先是read,触发了系统调用,程序从用户态进入内核态,发起DMA调用,从硬盘复制到内核缓冲区;
- 然后内核缓冲区完成后,内核触发一个CPU copy,从内核缓存复制到用户buffer,这是第二次拷贝,这个时候read函数完成,程序从内核态转换到用户态;
- 用户态开始调用write,系统发生CPU copy,把用户buffer复制到socket buffer,代码切换到内核态;
- 内核态开始继续用DMA,开始进行socket buffer到协议引擎;

可以看见,这种方案还是比较有多余的,但这样设计也是因为硬件和软件能力和架构问题,那么能不能直接一点从内核直接发送数据呢?当然可以,但肯定需要系统的特殊方式支持,下面就介绍2种方式,第一种:
MMAP:
该技术通过调用mmap代替调用read,如下面的例子所示:
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);
看起来代码感觉和read一样,但其实里面做的事情是不同的,主要的是read是把缓存读取了出来,而mmap不然,他是通过映射文件到一个共享内存中,这块内存,由内核态和用户态共享,过程大概是下图所示这样的:
- 首先,调用第一个方法,程序从用户态转换到内核态,采用DMA技术把文件copy到内核buffer中;
- 然后返回用户态,用户态拿到了一个共享的mmap文件引用,接着调用write;
- 系统继续切换内核态,write方法,从mmap中CPU copy到了socket buffer中;
- 最后内核态的程序继续用DMA,发送数据;

可以看出,其实mmap是减少了一半的copy量,只是因为mmap技术,可以使得用户态和内核态的隔离变得没那么死板了。至于为何要进行用户态和内核态的隔离,这就是设计和安全方面的考虑了吧;所以,涉及安全问题,证明这样做是有代价的,我们来讨论下,mmap的代价。
陷阱:用了mmap,代表你这个文件是被用户和内核共享的,那么就有一个线程安全问题,如果你在进行write的时候,mmap文件被另一个用户进程删掉了那么会怎么样呢?你会因为进行一个错误的存储访问而被信号 SIGBUS 中断;默认情况下是会中断进程的,解决方案有两种:
- 为该信号注册一个做简单返回处理的handler,但这样会使得write方法返回已经写的字节数,所以这方案是不可取的;
- 第二种是从内核中获取 file leasing (文件租约),该方案通过从系统Leasing一个文件描述符,当文件被第三方删除的时候,你会提前收到一个实时的信号 RT_SIGNAL_LEASE ,这样你的程序也会被中断,但不至于会被SIGBUS一样被杀死;
特点:
mmap其实是异步刷新共享的页缓存的;刷新时机可能如下:
- 调用 msync 函数主动进行数据同步(主动);
- 调用 munmap 函数对文件进行解除映射关系时(主动);
- 进程退出时(被动);
- 系统关机时(被动);
SEND FILE
Linux2.1内核之后,出现了一种新的方法,sendfile,该方法的牛皮之处不仅仅在于减少copy,而且还减少了用户态和内核态的切换,因为他真的只有一个方法调用,后面完全是内核的工作;
sendfile(socket, file, len);
过程大概如下图这:
- 首先调用方法,用户态进入内核态执行sendfile;
- 内核态直接DMA,复制到内核buffer,然后直接从内核buffer CPU copy到socket buffer;
- 返回用户态(因为这部分是异步flush),最后DMA copy到协议引擎,一气呵成;

看到这里,我们会有疑问,如果copy的时候,其他用户进程又来删掉了呢?其实这里也差不多,唯一不同的就是不会被 SIGBUS信号中断杀死,毕竟这是内核的事情,所以也是需要leasing RT_SIGNAL_LEASE才能正常工作的哦;
SEND FILE
前面的介绍,怎么说都有一次CUP copy,那么能不能上面的唯一一次cpu copy也去掉呢?其实也是可以的,但需要socket方面的支持了;这就是2.4版本 kernel中了;其实就是改进版本的send file所以,用法也没变。
sendfile(socket, file, len)
它的工作过程大概是:
- 首先调用方法,用户态进入内核态执行sendfile;
- 内核态直接DMA,复制到内核buffer,但这次不再cpu copy到 socket buffer中,而是把一些文件的描述符,长度等信息append到socket buffer中;
- 返回用户态,后面内核中,socket方法的内核调用DMA直接从在kernel buffer中 收集文件内容到协议引擎中;
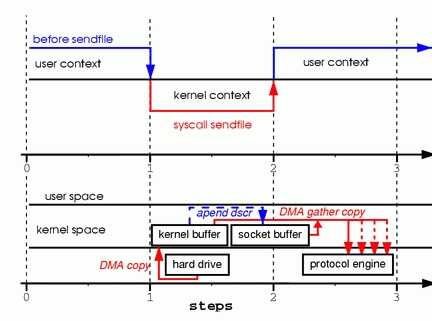
特点:整个过程是阻塞式的;
总结:
毕竟以上方法也是有一次copy的,有人说这也不算是 zero copy,其实零拷贝是对于内核而言的,内核中没有进行多余的copy,这也就够了,减少了cpu copy是节省了很多时间的;但是不是mmap就比sendfile差呢?其实不然,这两者是各有优点的,对比如下:
- 使用 mmap + write 方式 优点:即使频繁调用,使用小块文件传输,效率也很高 缺点:不能很好的利用 DMA 方式,会比 sendfile 多消耗 CPU,内存安全性控制复杂,需要避免 JVM Crash 问题。
- 使用 sendfile 方式 优点:可以利用 DMA 方式,消耗 CPU 较少,大块文件传输效率高,无内存安全新问题。 缺点:小块文件效率低于 mmap 方式,只能是 BIO 方式传输,不能使用 NIO。
- mmap 需要 4 次上下文切换,3 次数据拷贝;
- sendFile 需要 3 次上下文切换,最少 2 次数据拷贝;
当然了,我本人也没有研究那么深的水平,这篇文章参考的国外一篇博文,尊重作者我把链接放下,读者可以帮我纠正一下我翻译不对的地方,一起学习,谢谢;