数据集和性能指标
目标检测常用的数据集包括PASCAL VOC , ImageNet , MS COCO等数据集,这些数据集用于研究者测试算法性能或者用于竞赛。目标检测的性能指标要考虑检测物体的位置以及预测类别的准确性
| PASCAL VOC |
The PASCAL Visual Object Classification,其仅包含20个类别,因此被看成目标检测问题的一个基准数据集 |
| ImageNet |
此训练数据集太大,所需计算量很大,因此很少使用。同时,由于类别数也比较多,目标检测的难度也相当大 |
| MS COCO |
Microsoft公司建立的Common Objects in context ,被分为两类,一类是test-dev数据集用于研究者,一类是test-challenge数据集用于竞赛者 |
性能指标
目标检测问题同时是一个回归和分类问题。首先,为了评估定位精度
| loU |
Intersection over Union ,介于0到1之间,其表示预测框和真实框之间的重叠程度。loU越高,预测框的位置越准确。 |
| ground-truth box |
真实框 |
| True Positive,TP |
真阳性 |
| False Positive,FP |
假阳性 |
| AP |
Average Precision 是一个重要的指标,这是信息检索中的一个概念,基于precision-recall曲线计算出来 |
| precision |
精确度[pri'sigen] |
| mAP |
Mean Average Precision 综合指标,mAP指标可以避免某些类别比较极端化而弱化其他类别的性能这个问题 |
| FPS |
Frame PEer Second,评估速度,即每秒内可以处理的图片数量。当然要对比FPS,需要在同一硬件上进行。另外也可以使用处理一张图片所需时间来评估检测速度,时间越短,速度越快 |
R-CNN
| Word |
Translation |
| R-CNN |
基于region proposal方法的目标检测算法 |
其先进行区域搜索,然后再对候选区域进行分类。在R-CNN中,选用Selective search方法来生成候选区域,这是一种启发式搜索算法。它先通过简单的区域划分算法将图片划分成很多小区域,然后通过层级分组方法按照一定相似度合并它们,最后剩下的就是候选区域,它们可能包含一个物体。
SPP-net
| SPP-net |
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition |
| SPP |
Spatial Pyranid Pooling Layer,SPP |
| softmax层 |
全连接层 |
SPP-net 提出的起因是解决图像分类中要求输入图片固定大小的问题,但是SPP-net所提出的空间金字塔池化层(SPP)可以和R-CNN结合在一起并提升其性能采用深度学习模型解决图像分类问题时,往往需要图像的大小固定(224*224),这并不是CNN层的硬性要求,主要原因在于CNN层提取的特征图最后要送入全连接层(如softmax层),对于变大小图片,CNN层得到的特征图大小也是变化的,但是全连接层需要固定大小的输入,所以必须要将图片通过resize,crop或wrap 等方式固定大小(训练和测试时都需要)。但是实际上真是的图片的大小是各种各样的,一旦固定大小可能会造成图像损失,从而影响识别精度。为了解决这个问题,SSP-net在CNN层与全连接层之间插入了空间金字塔池化层来解决这个矛盾。
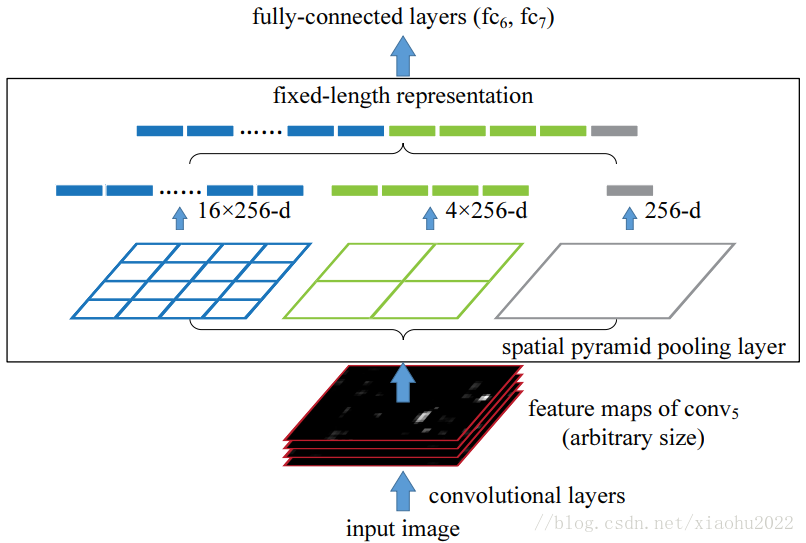
SPP-net中的空间金字塔池化层
Fast R-CNN
| word |
translation |
| Fast R-CNN |
Fast Region-based Convolutional Network |
| Rols pooling |
Region of Interests pooling |
| interation |
[inte'reition]交互影响 |
| TensorFlow |
Google |
Pol pooling层相比于SPP层看起来主要是只是用一个金字塔级别。然后Rol pooling层得到的特征图送入几个全连接层中,并产生新的特征向量,这些特征向量分别用于一个softmax分类器(预测类别)和一个线性回归器上(用于调整边界框位置)来进行检测。在实现上是使用两个不同的全连接层,第一个全连接层有N+1个输出(N是类别总数,1是背景),表示各个类别的概率值;第二个全连接层有4N个输出,表示坐标回归值,这个与R-CNN是一样的,每个类别都预测4个位置坐标值。
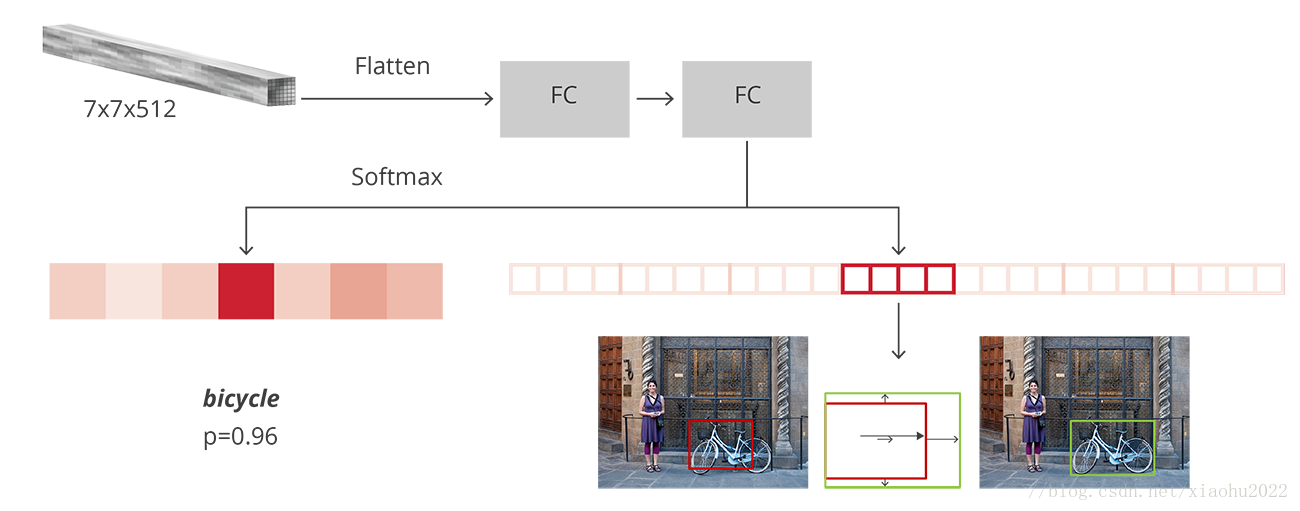
Fast R-CNN的分类与回归预测