三:压缩与解压
1:Hadoop数据压缩
MR操作过程中进行大量数据传输。
压缩技术能够有效的减少底层存储(HDFS)读写字节数。
压缩提高了网络带宽和磁盘空间的效率。
数据压缩能够邮箱的节省资源!
压缩是mr程序的优化策略!
通过压缩编码对mapper或者reducer数据传输进行数据的压缩,以减少磁盘IO。
2:压缩的基本原则
1)运算密集型任务少用压缩
2)IO密集型的任务,多用压缩
3:MR支持的压缩编码
压缩格式 | hadoop是否自带? |文件拓展名 | 是否可以切分
DEFAULT | 是 | .deflate | 否
Gzip | 是 | .gz | 否
bzip2 | 是 | .bz2 | 是
LZO | 否 | .lzo | 是
Snappy | 否 | .snappy | 否
4:编码/解码器
DEFAULT|org.apache.hadoop.io.compress.DefaultCodeC
Gzip |org.apache.hadoop.io.compress.GzipCodeC
bzip2 |org.apache.hadoop.io.compress.BZip2CodeC
LZO |com.hadoop.compression.lzo.LzoCodeC
Snappy |org.apache.hadoop.io.compress.SnappyCodeC
5:压缩性能
压缩算法 | 原始文件大小 | 压缩文件大小| 压缩速度| 解压速度
gzip | 8.3GB |1.8GB|17,5MB/s|58MB/s
bzip2| 8.3GB |1.1GB|2.4MB/s |9.5MB/s
LZO | 8.3gb |2.9GB|49.3MB/s|74.6MB/s
6:使用方式
map端输出压缩
//开启map端的输出压缩
conf.setBoolean("mapreduce.map.output.compress", true);
//设置压缩方式
//conf.setClass("mapreduce.map.output.compress.codec", DefaultCodec.c
lass, CompressionCodec.class);
conf.setClass("mapreduce.map.output.compress.codec",
BZip2Codec.class, CompressionCodec.class);

reduce端输出压缩
//开启reduce端的输出压缩
FileOutputFormat.setCompressOutput(job, true);
//设置压缩方式
//FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class);
//FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
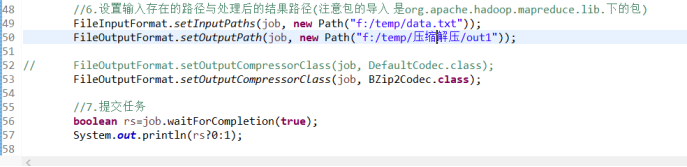
运行结果: