10:Spark
Spark:基于内存的实时数据分析框架
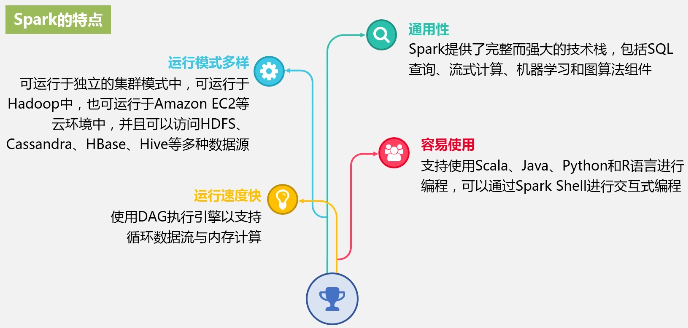
Spark的特点:
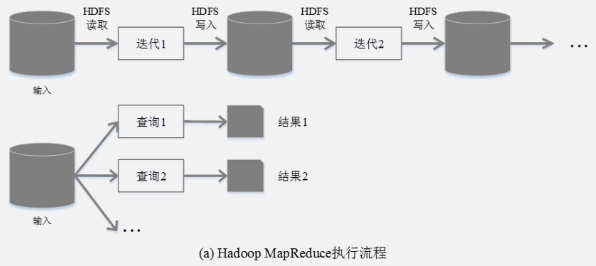
Spark和Hadoop的对比:
Hadoop的缺点:
1.表达能力有限
2.磁盘IO开销大
3.延迟高,任务之间的衔接涉及IO开销
4.在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任务
Spark的优点:
1.编程模型更灵活
2.提供内存运算,迭代运算效率更高
3.基于DAG的任务调度执行机制
(Hadoop的Tez框架也实现了DAG任务调度,但Hadoop本身并没有实现)


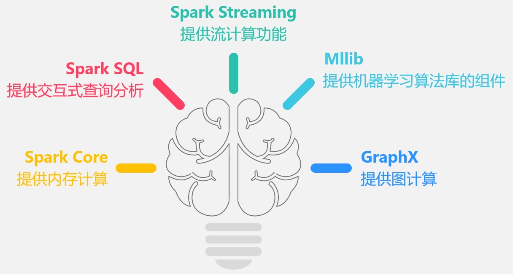
Spark的生态系统:(可以同时支持批处理、交互式查询和流数据处理)

Spark生态系统组件的应用场景:
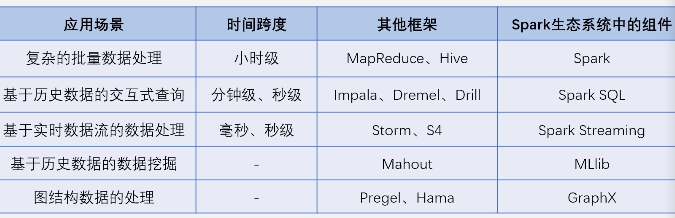
10.3.1基本概念和架构设计
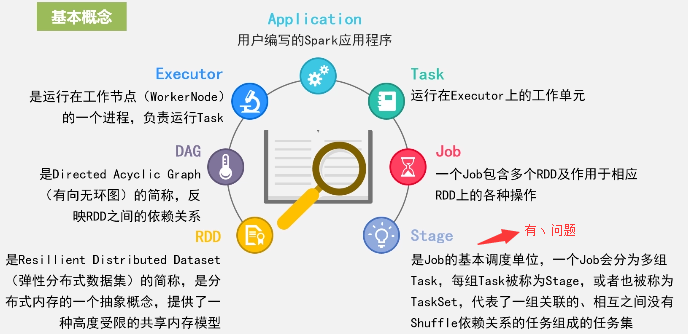
(注意:多组task不是一个task)
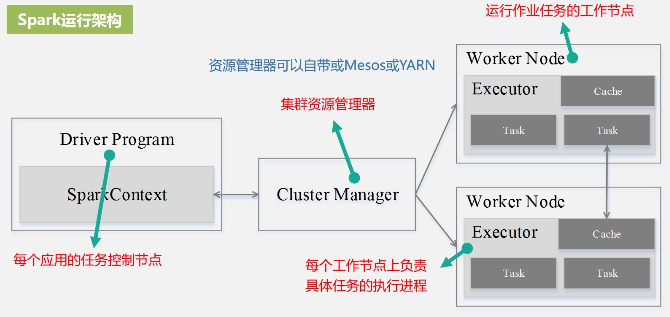
Spark采用Executor所具有的优点:
1.利用多线程来执行具体的任务,减少任务的启动开销
2.Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销
Spark中的概念:
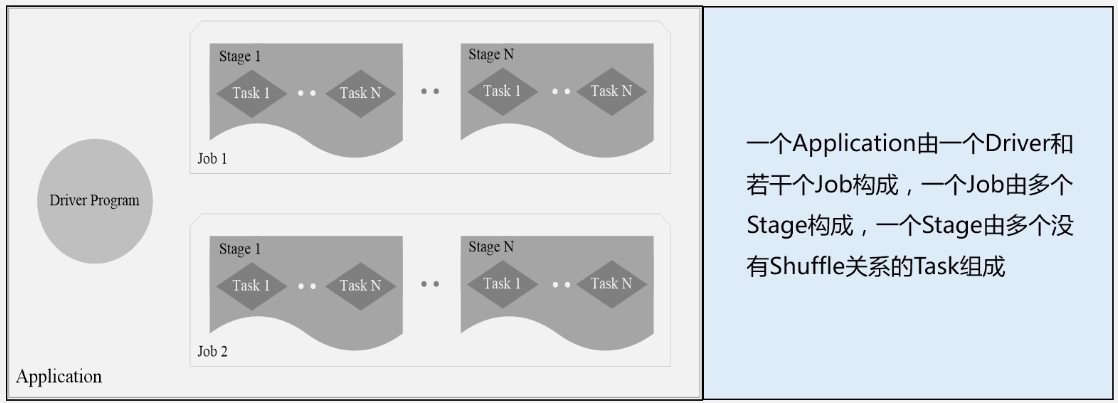
相互关系:

Spark的运行流程图:
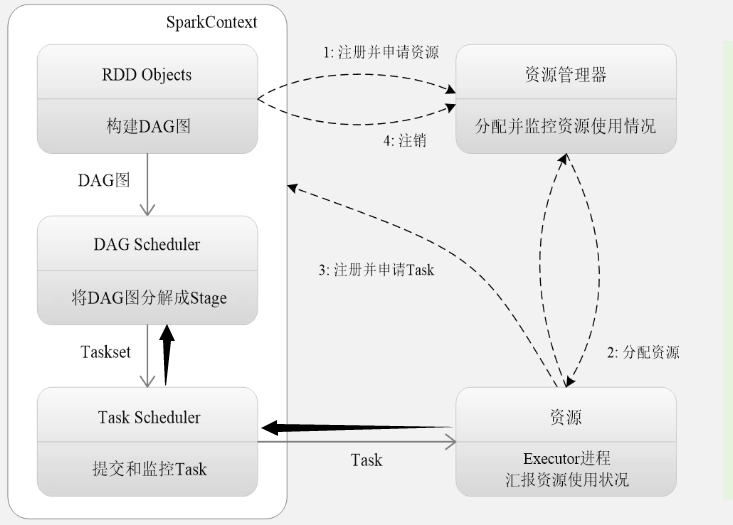
Spark运行架构的特点:

10.3.3:Spark中的RDD
RDD:一种抽象的数据结构。不同的RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储

RDD的特点:
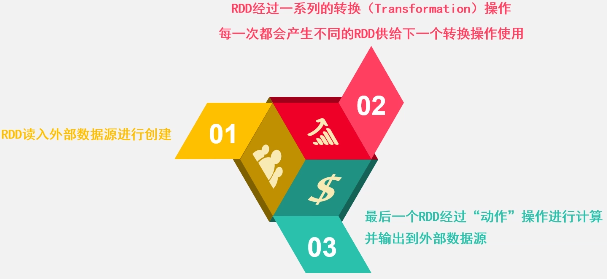
RDD的典型执行过程:



RDD实现Spark高效计算的原因:
1.RDD具有高效的容错性
现有容错机制:数据复制/记录日志
RDD具有天生的容错性
2.中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递避免了不必要的读写磁盘开销
3.存放的数据可以是JAVA对象,避免了不必要的对象序列化和反序列化
10.3.5:RDD的依赖关系和运行过程
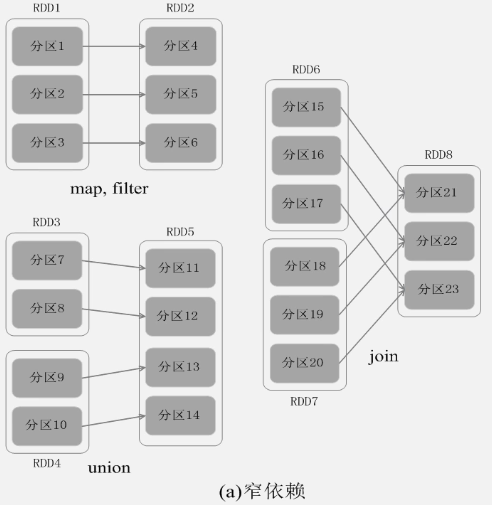
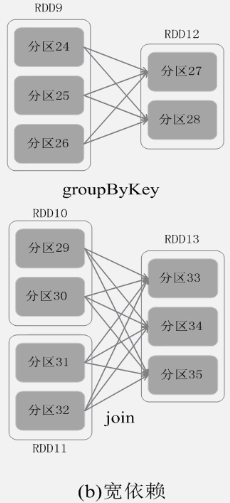
依赖关系:宽依赖、窄依赖
窄依赖:

宽依赖:

stage的划分:(RDD之间的依赖关系形成一个DAG,由sparkcontext负责生成)

例子:
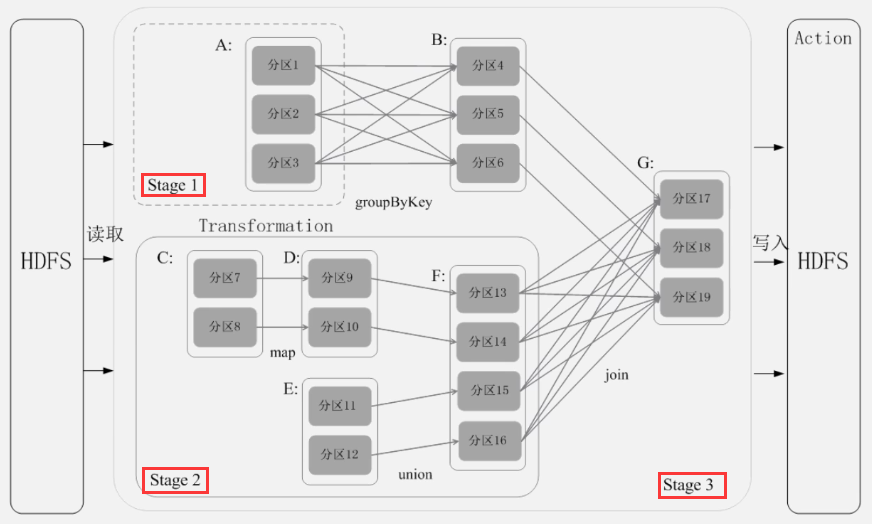
stage包含的类型:shuffleMapStage、ResultStage



Spark的部署:
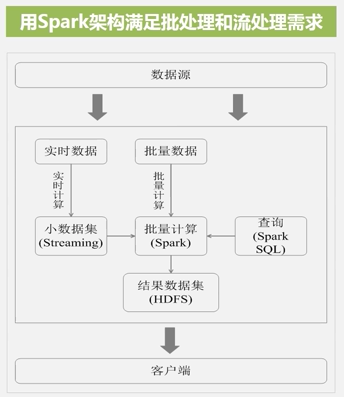

采用Hadoop+Spark的方式:

不同的计算框架同意运行在YARN中:
1.计算资源可以按需伸缩
2.不用负载应用混搭,集群利用率高
3.共享底层存储,避免数据跨集群迁移
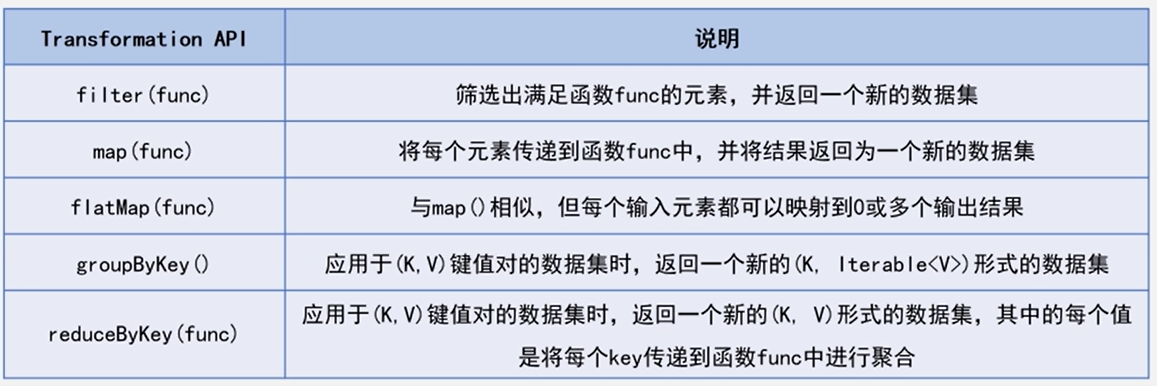
Spark RDD的基本操作: