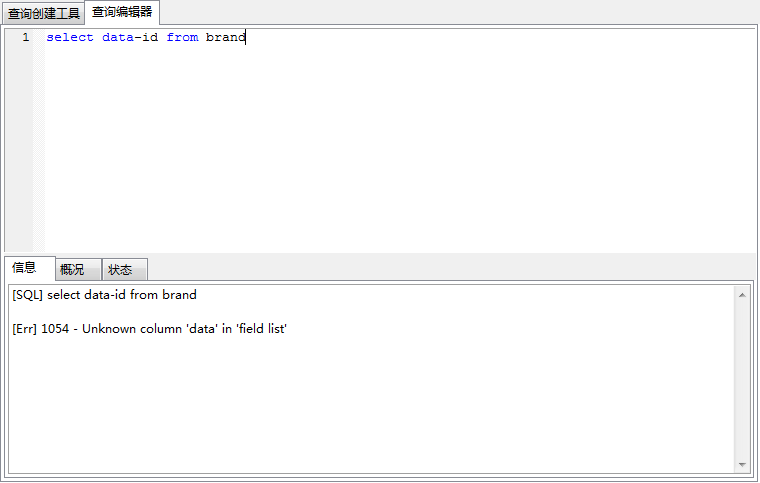
1. 列名有特殊字符
列明如果有特殊字符,如# 或者 - 等,需要用反引号`(数字键1左边的符号)将列明括起来,否则会报错
2. varchar和nvarchar的区别
1. varchar(n):长度为n个字节的可变长度且非Unicode的字符数据。n必须是一个介于1和8,000之间的数值。存储大小为输入数据的字节的实际长度
2. nvarchar(n):包含n个字符的可变长度Unicode字符数据。n的值必须介于1与4,000之间。字节的存储大小是所输入字符个数的两倍。所输入的数据字符长度可以为零。nvarchar适用中文和其他字符,其中N表示Unicode编码,可以解决多语言之间的转换问题。使用nvarchar存储英文字符会增大一倍的存储空间.但是在存储代价已经很低廉的情况下,优先考虑兼容性会带来更多好处的。
加上 N 代表存入数据库时以 Unicode 格式存储。
saleUserName的字段类型为varchar(50)
update TableName set saleUserName='小覃祝你⑭快乐' where ID=87
select * from TableName where ID=87
why?SaleUserName字段里的文字怎么变成这样了。⑭这个符号怎么变成了?
那么,稍微改一下,在参数值前面加上N。现在可以看到调皮的⑭出来了。
update TableName set saleUserName=N'小覃祝你⑭快乐' where ID=87

3. 利用insert into ... select ... union all 提升数据插入效率
insert into WORKERS select 'A',25,'统计',3000,1 union all select 'B',30,'设计规划',9000,2 union all select 'C',20,'代码员',2000,3的执行结果相当于执行了
insert into WORKERS values ('A',25,'统计',3000,1); insert into WORKERS values('B',30,'设计规划',9000,2); insert into WORKERS values('C',20,'代码员',2000,3);但是使用insert into ... select ... union all 的数据插入效率要比下面分条插入的方式高的多。
insert into ... select ... union all这个语句分为两部分,select ... union all 和insert
其实 select ... union all... 又由三个select 语句组成,通过union all 将select的结果联合起来,然后一次性插入到数据库中。
单独运行:select 'A',25,'统计',3000,1 union all select 'B',30,'设计规划',9000,2 union all select 'C',20,'代码员',2000,3会产生3行。
最后,通过insert语句,将3行一次性插入到WORKERS表中。这样比下面分三次插入到表中的效率要高很多。
4. 内连接、外连接 与 左连接、右连接
驱动表与被驱动表:
在两表连接查询中,驱动表只需要访问一次,被驱动表可能被访问多次。
内连接与外连接:
- 对于
内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接。- 对于
外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。在MySQL中,根据选取驱动表的不同,外连接仍然可以细分为2种:
- 左外连接 选取左侧的表为驱动表
- 右外连接 选取右侧的表为驱动表
过滤条件where 和 on:
WHERE子句中的过滤条件
WHERE子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连接,凡是不符合WHERE子句中的过滤条件的记录都不会被加入最后的结果集。
ON子句中的过滤条件对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配
ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充。需要注意的是,这个
ON子句是专门为外连接驱动表中的记录在被驱动表找不到匹配记录时应不应该把该记录加入结果集这个场景下提出的,所以如果把ON子句放到内连接中,MySQL会把它和WHERE子句一样对待,也就是说:内连接中的WHERE子句和ON子句是等价的。一般情况下,我们都把只涉及单表的过滤条件放到
WHERE子句中,把涉及两表的过滤条件都放到ON子句中,我们也一般把放到ON子句中的过滤条件也称之为连接条件左连接与右连接:
左连接和右连接是左外连接和右外连接简称, 只有外连接才分左右,且外连接一定会分左右。
可以据此来分辨内连接和外连接:
如果join语句前面有left或者right, 则一定是外连接,此时on的语义与where的语义不同;
如果join语句前面没有left或者right, 则一定是内连接,此时on的语义与where相同。
标识内连接和外连接的关键字inner|cross 和 outer都是可以省略的。
来源: https://juejin.im/book/5bffcbc9f265da614b11b731/section/5c061b0cf265da612577e0f4
5. count(1)、count(*)、count(列名)的区别
含义:
1、count(*) :统计所有的行数,包括为null的行(COUNT(*)不单会进行全表扫描,也会对表的每个字段进行扫描。而COUNT('x')或者COUNT(COLUMN)或者COUNT(0)等则只进行一个字段的全表扫描)。2、count(1):计算一共有多少符合条件的行(其实就可以想成表中有这么一个字段,这个字段就是固定值1,count(1),就是计算一共有多少个1..同理,count(2),也可以,得到的值完全一样,count('x'),count('y')都是可以的。count(*),执行时会把星号翻译成字段的具体名字,效果也是一样的,不过多了一个翻译的动作,比固定值的方式效率稍微低一些。)
3、count(列名):查询列名那一列的,字段为null不统计。
执行效果:
1、count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL。2、count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL。
3、count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空。
执行效率:
列名为主键,count(列名)会比count(1)快
列名不为主键,count(1)会比count(列名)快
如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count(*)最优
来源 https://blog.csdn.net/lcgoing/article/details/82787885