OLTP
scale-up和scale-out
scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out
scale-out,就是分布式数据库,刚开始肯定是Shared Nothing,但是分布式也引入了更高的架构复杂度和维护成本
所以现在的趋势,是架构分层,层之间是逻辑的scale-up,层内部是物理的scale-out
最终sharing-everything,其实在架构上又回到了scale-up
所以随着硬件的进步和技术的演进,架构上没有绝对的好坏
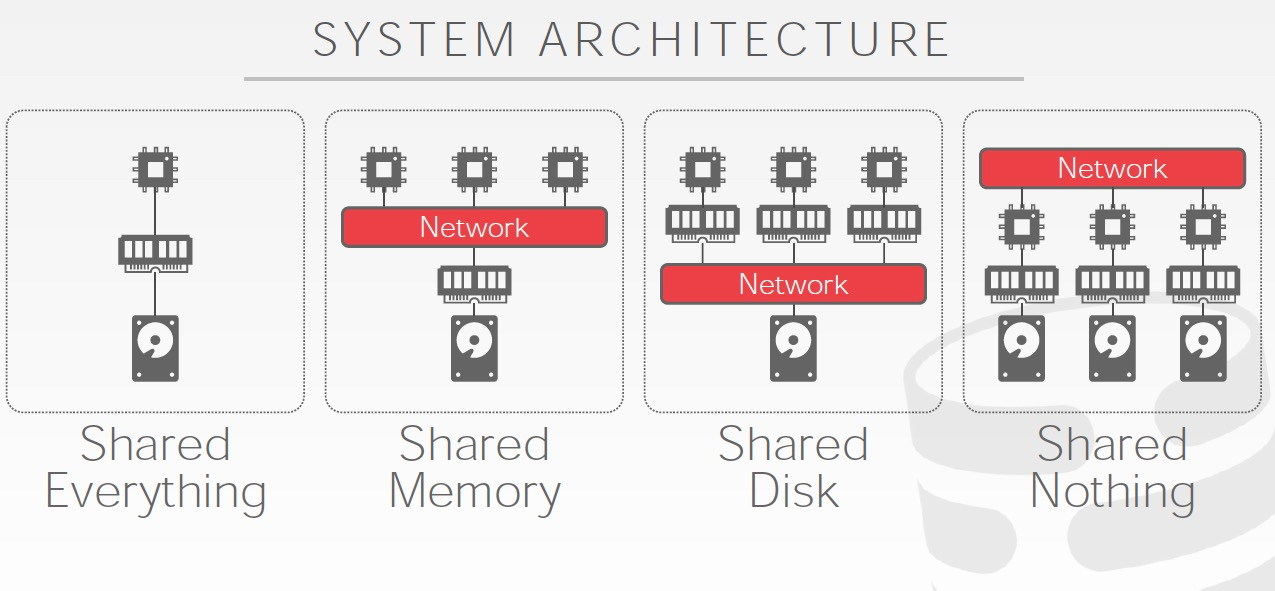
Shared Nothing是最常见的,也是最开始的分布式方案

共享磁盘,代表是Amazon的Aurora
执行层和存储层分离,那么当前在数据库层就不需要管副本同步的问题,主挂了,备拉起看到的数据还是一样的,在数据库层只有一份磁盘数据

共享内存,共享磁盘虽然解决大部分数据同步的问题,但是执行层仍然是有状态的,因为内存中的状态,并没有落盘,所以failover后仍然需要状态恢复
如果共享内存,那么执行层就可以完全无状态,那样维护成本会大幅降低
但是很明显,共享内存很难实现,稳定性和性能的要求会很高,现在没有数据库实现共享内存

早期的分布式数据库,

分布式数据库设计需要考虑一些架构上的问题,
同构还是异构,Mongo是典型的异构架构

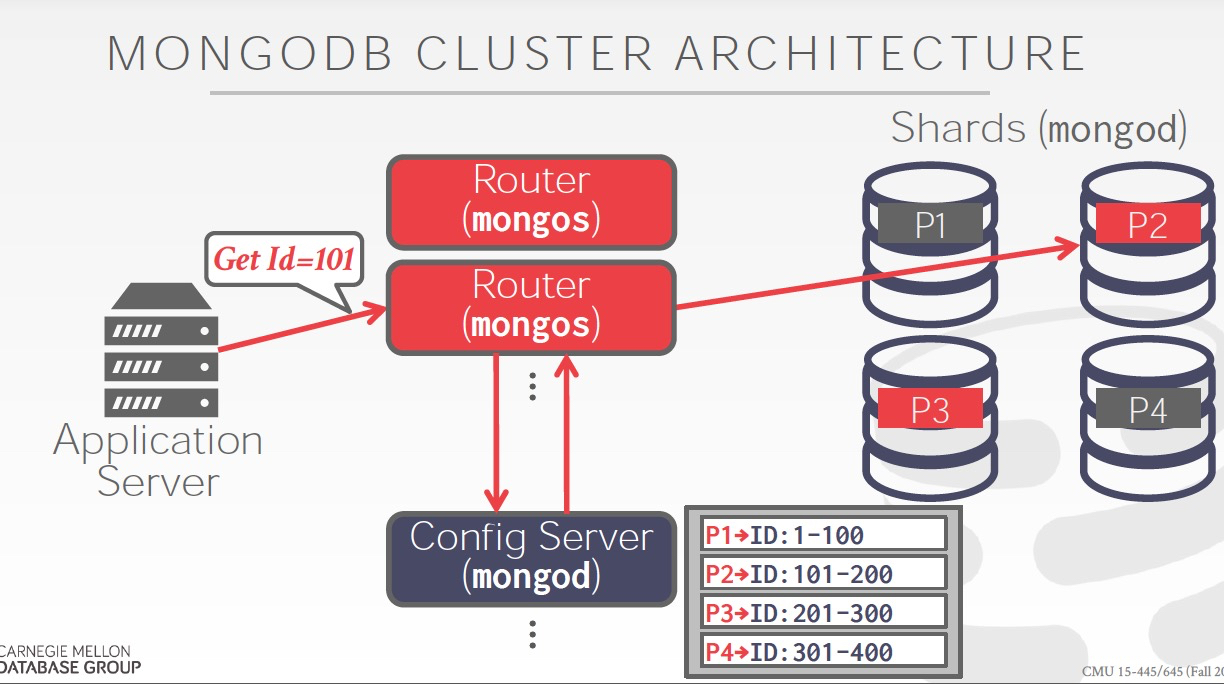
数据Partition,既然是分布式数据库,数据肯定是要分开放的,怎么分?

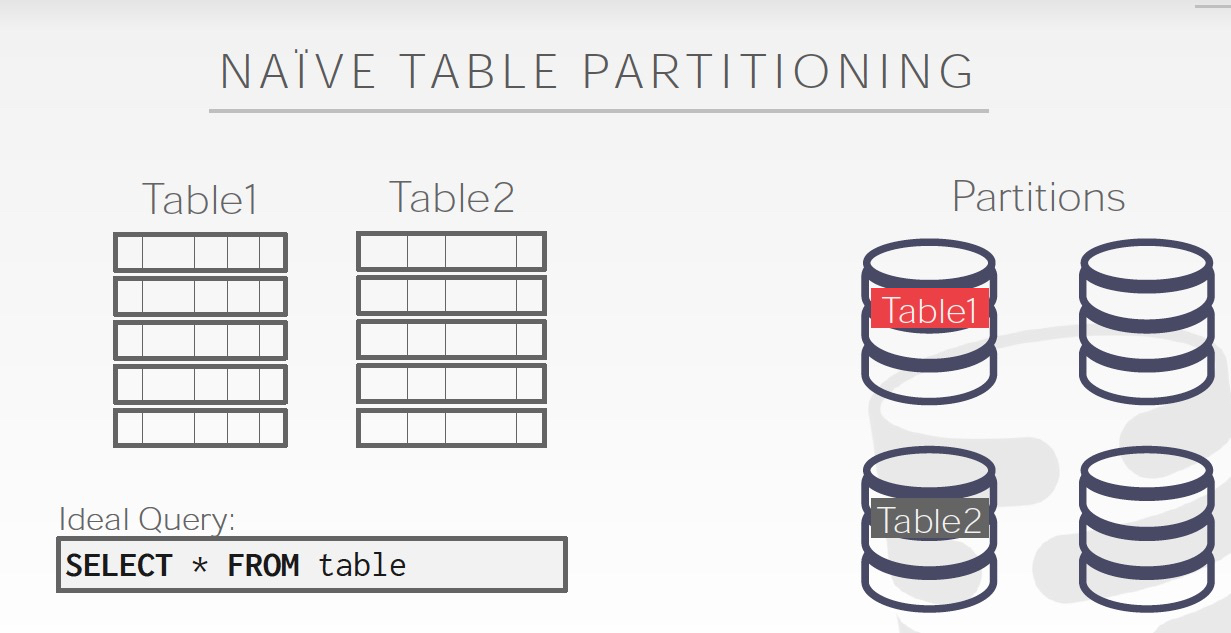
可以按照Table分,明显这样扩展性不太好,如果Table太大会有问题
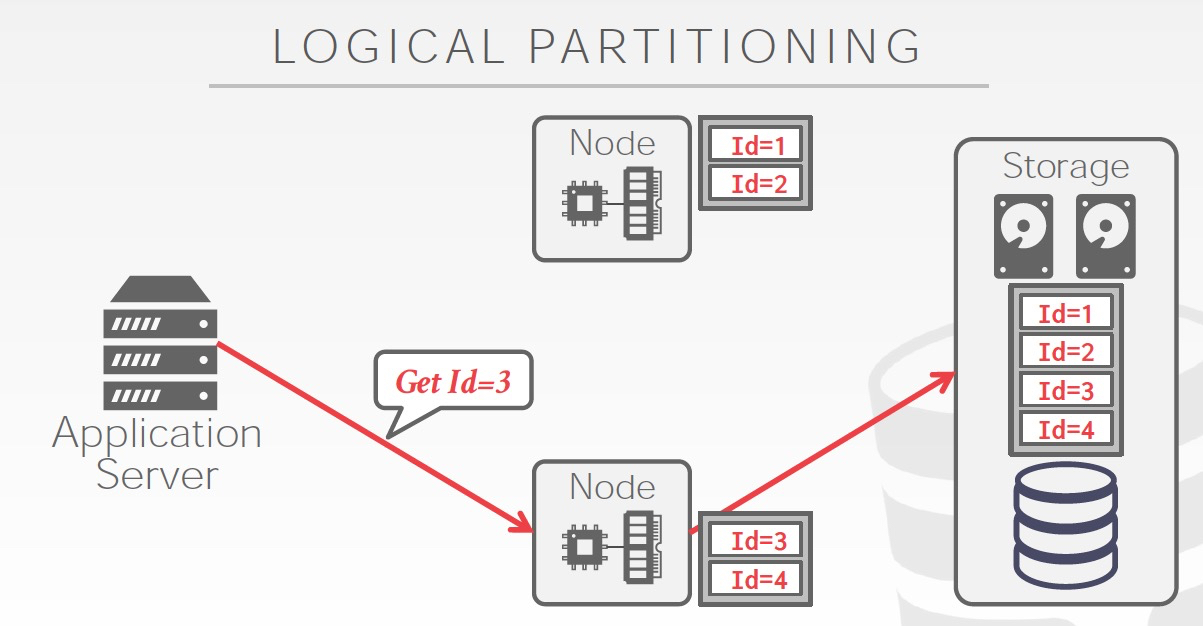
比较自然的方式,是水平划分,如右图
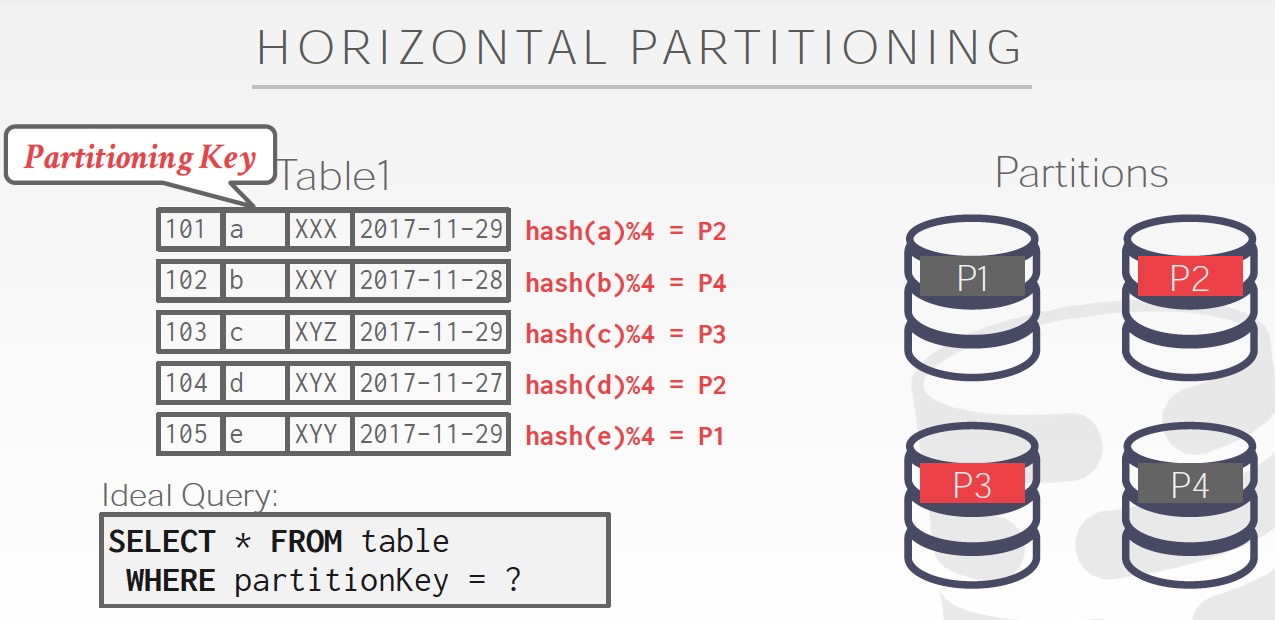
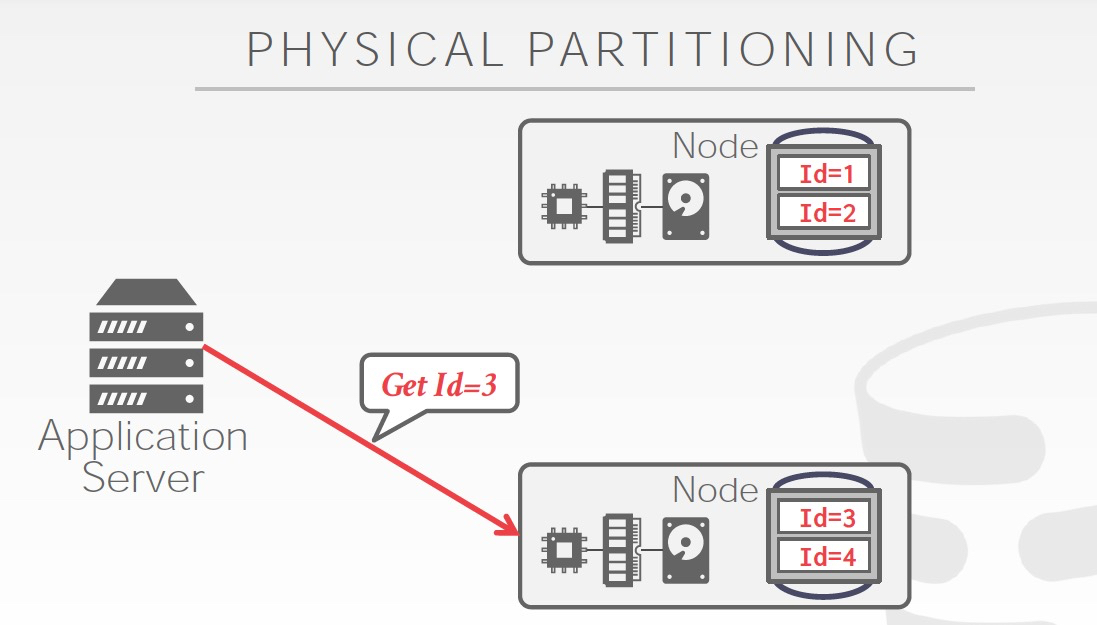
Partition还分为,逻辑的和物理的,如果是逻辑的,只是扩展数据库处理能力
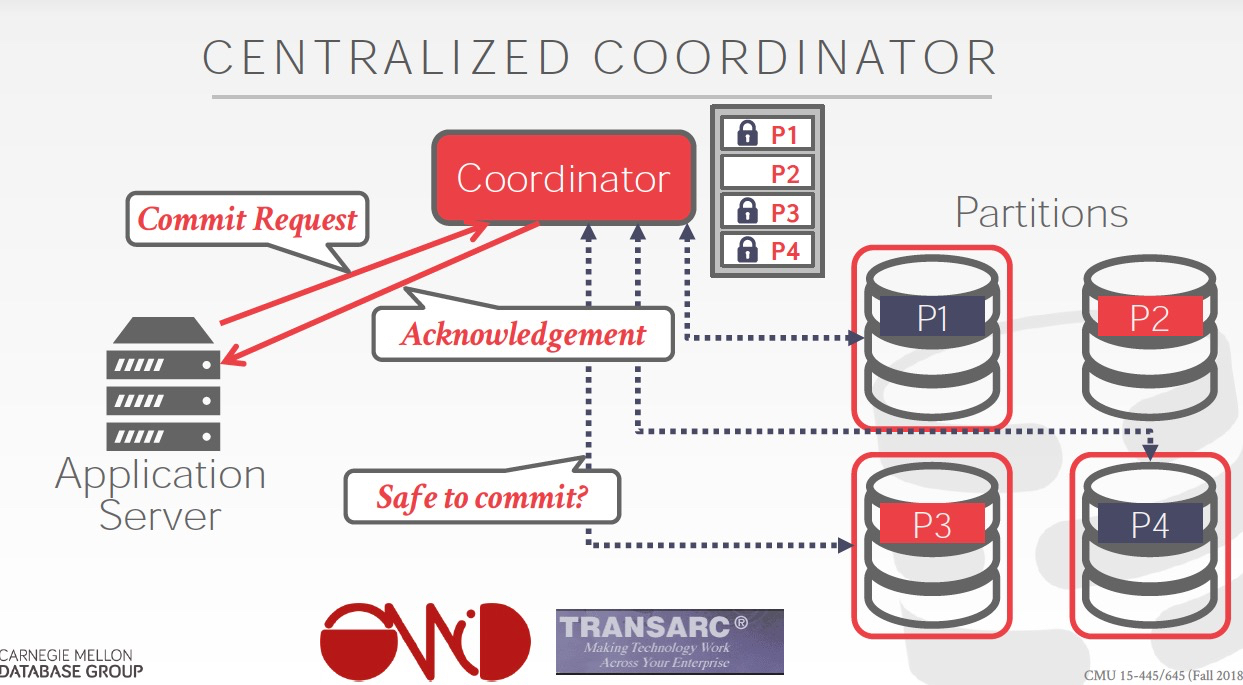
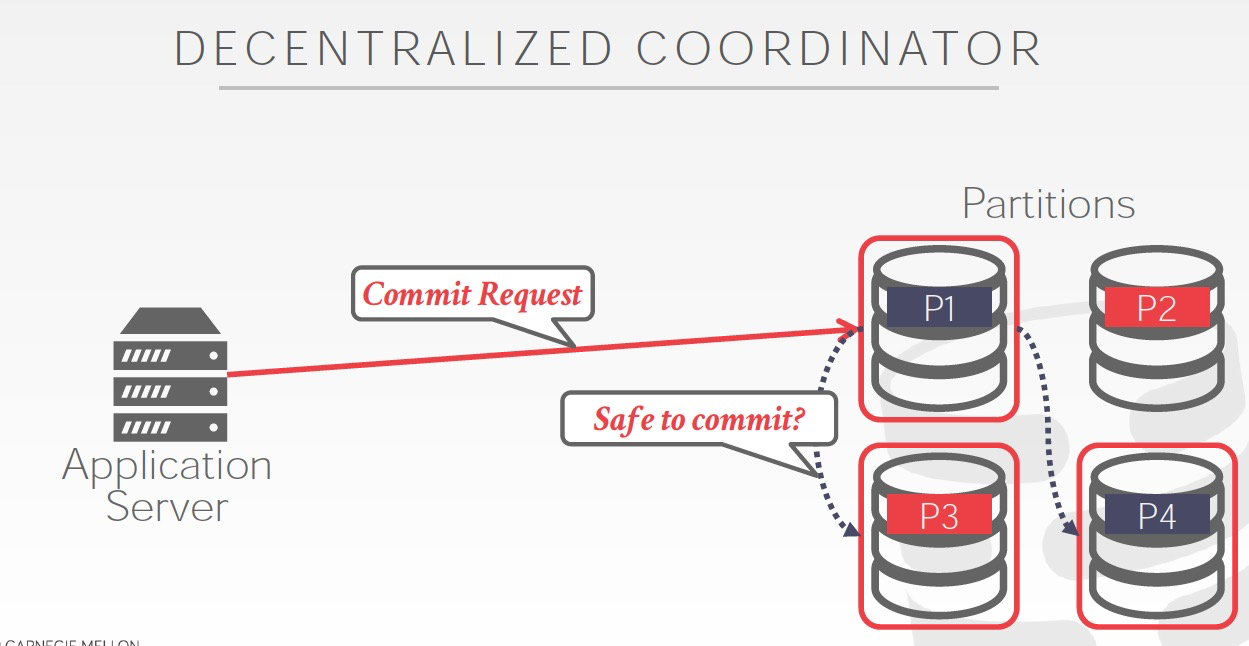
中心化,还是去中心化

中心化实现简单,但是单点问题,扩展和failover,典型代表,Bigtable
非中心化,实现复杂,一致性很难保证,更优雅
分布式一致性,是分布式数据库中最困难的问题
可以看到简单的分布式2PL很容易造成死锁


分布式一致性的常用方法如下,

2PL分为两个阶段,准备和提交;2PL的最大问题就是活性,任意一个节点挂都会导致失败
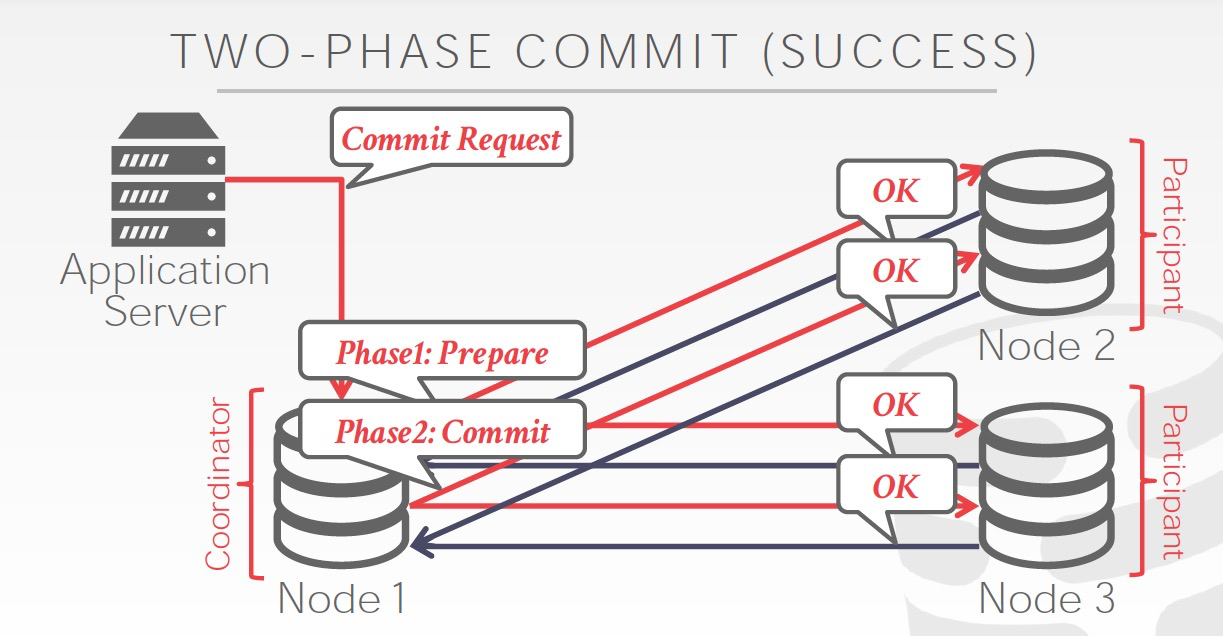
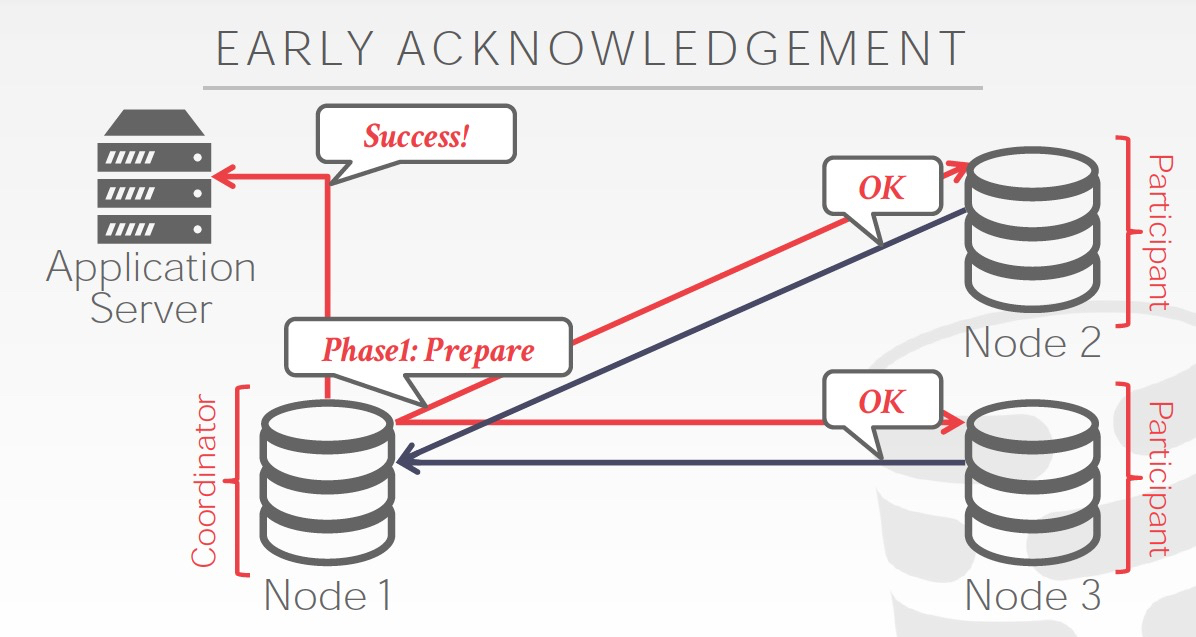
Early acknowledgement,Prepare都成功后,直接给client返回成功,不用等commit阶段结束

Paxos,简单的理解为,majority版本的2PL


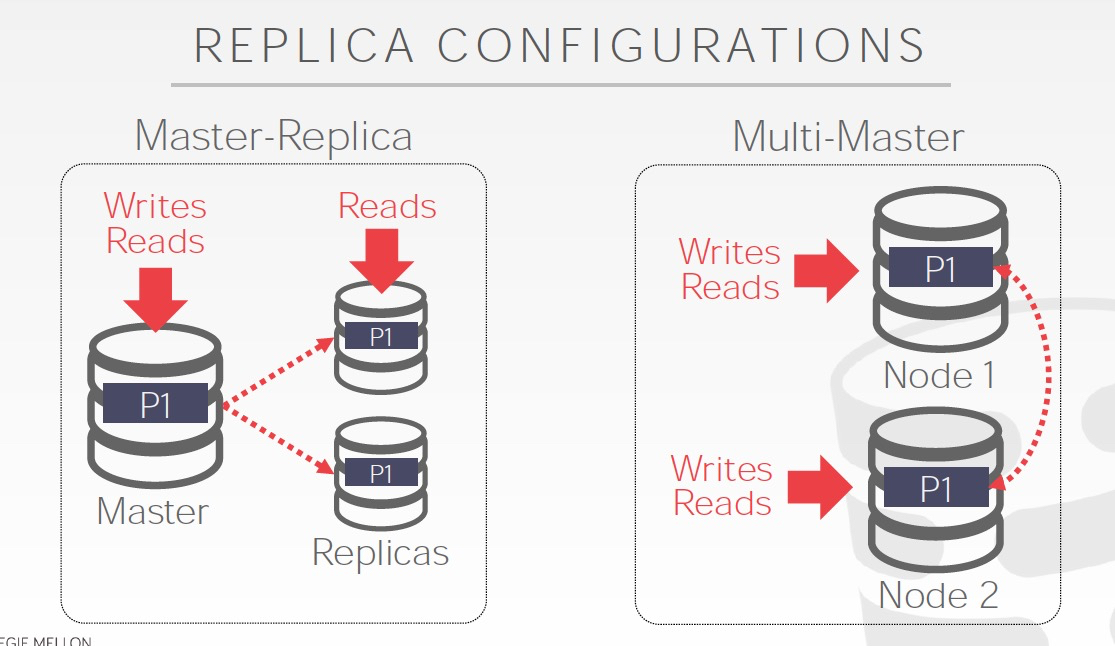
副本机制用于解决单点问题,所以多存几份
副本最大的问题就是同步问题

主备或多主,两种情况

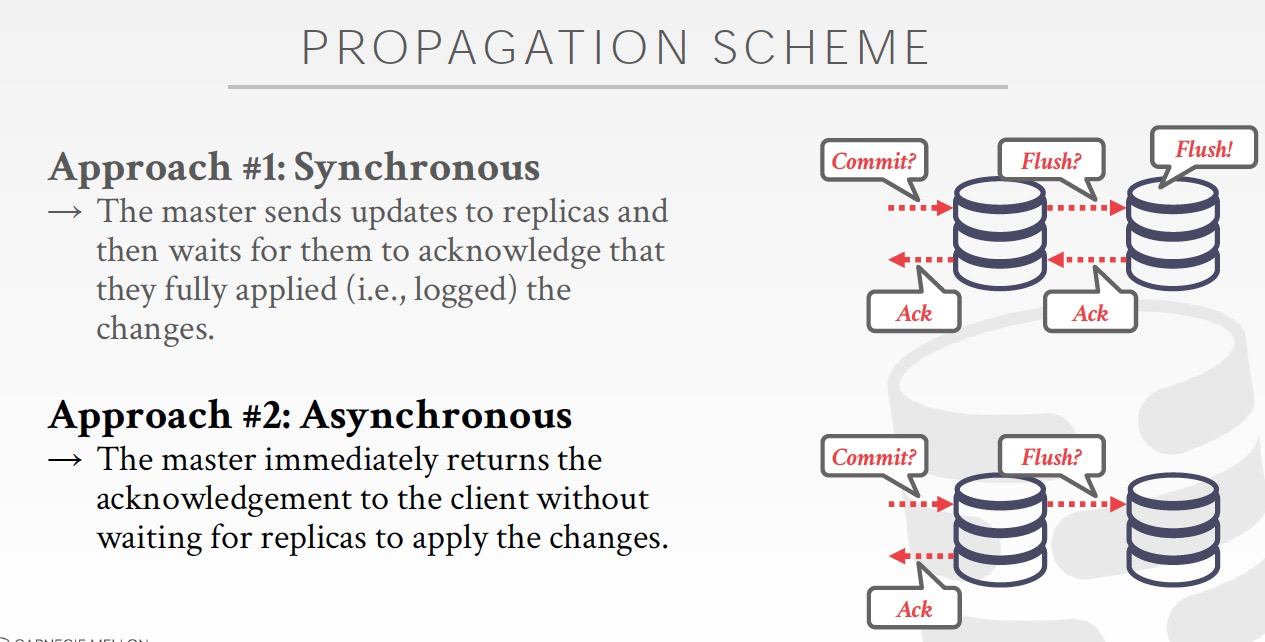
副本间同步策略,
同步,主备都是落盘
异步,主落盘
半异步,主落盘,备收到数据,未落盘



持续同步,或是commit的时候同步
基本都采用持续同步

Active,主进程主动同时写多个副本
Passive,主进程只写主副本,其他需要同步进程进行被动同步

CAP理论 ,3选二
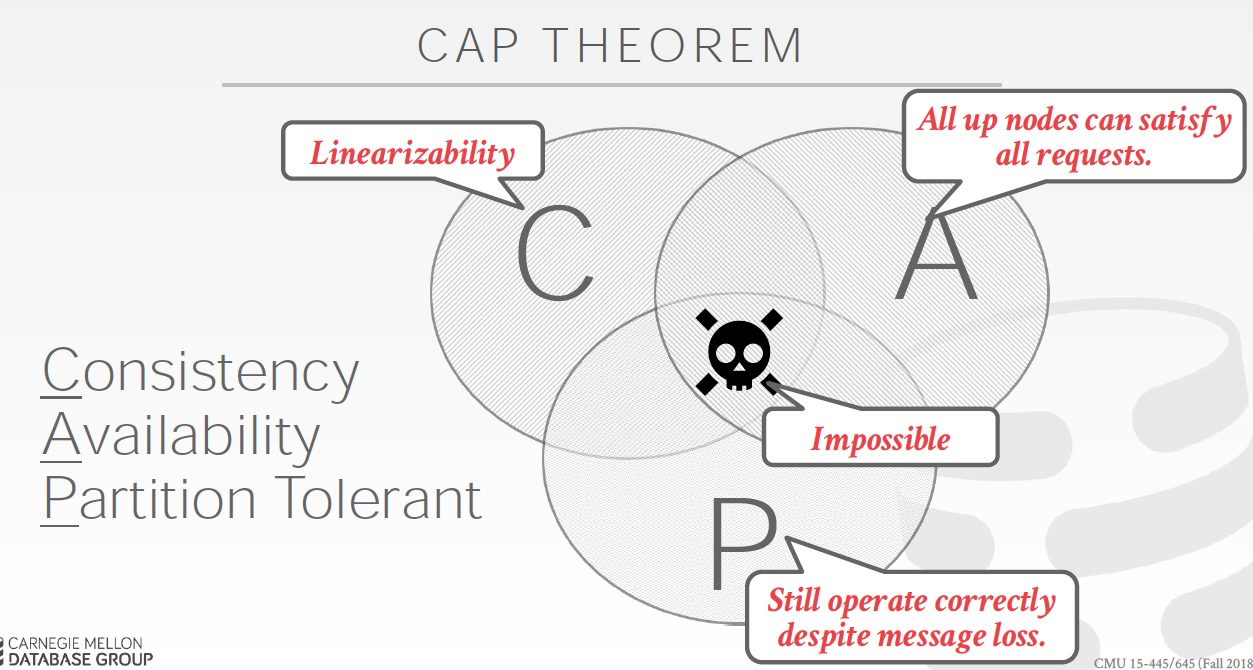
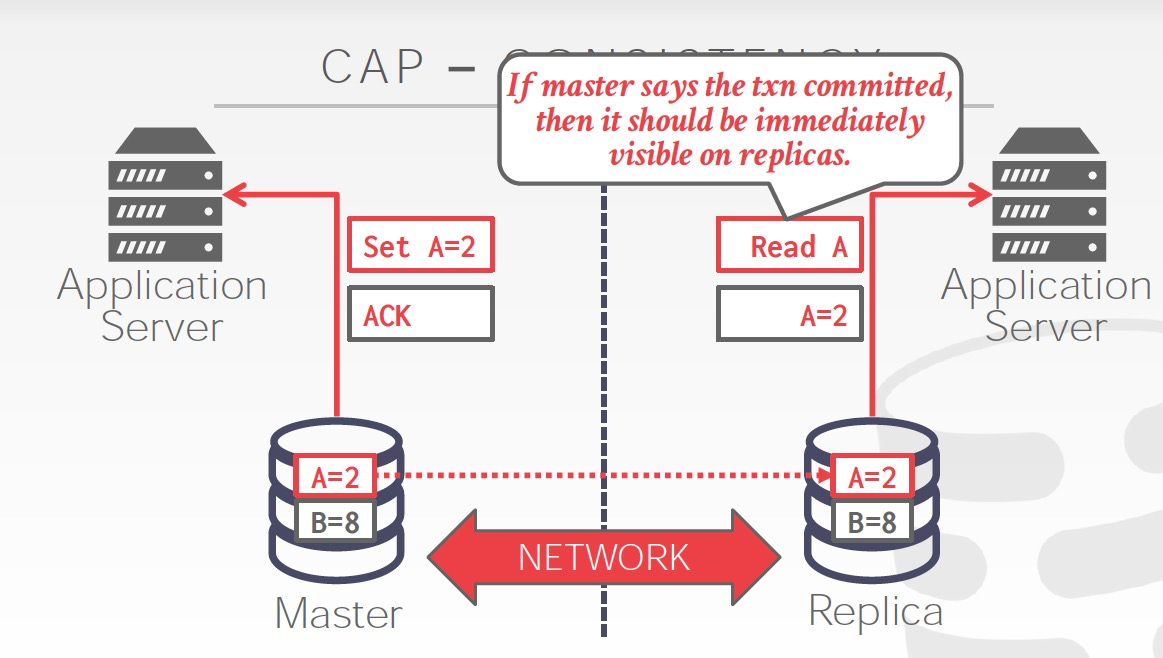
一致性,一旦commit,从每个副本上读到的数据是一样的
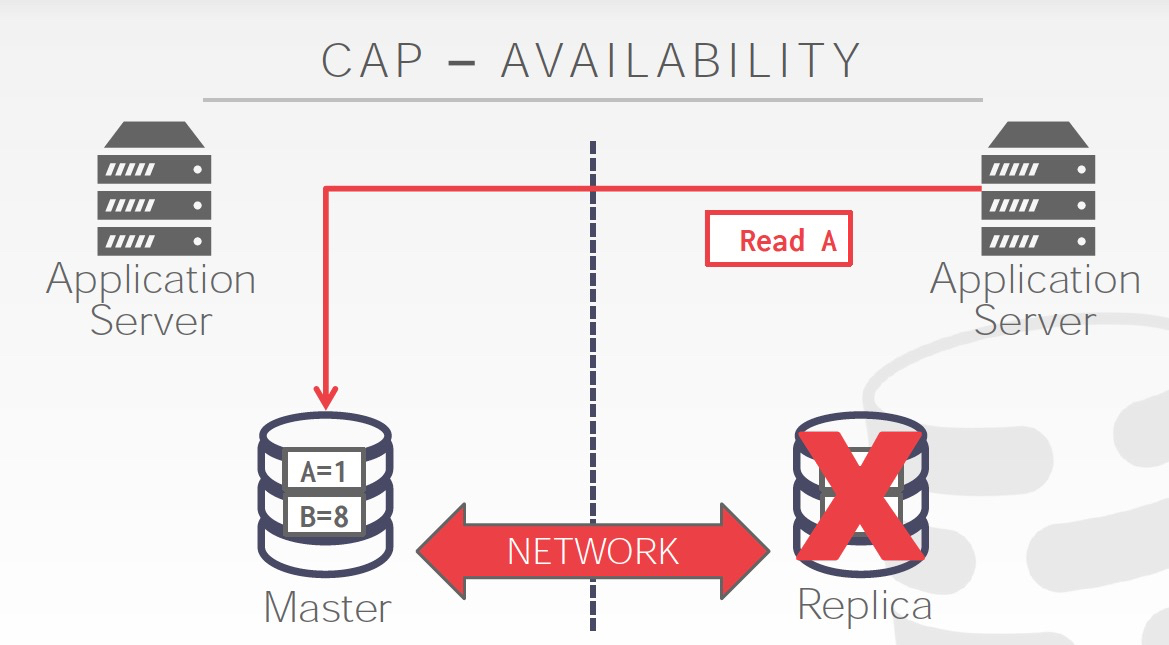
可用性,挂掉一个副本仍然可读写
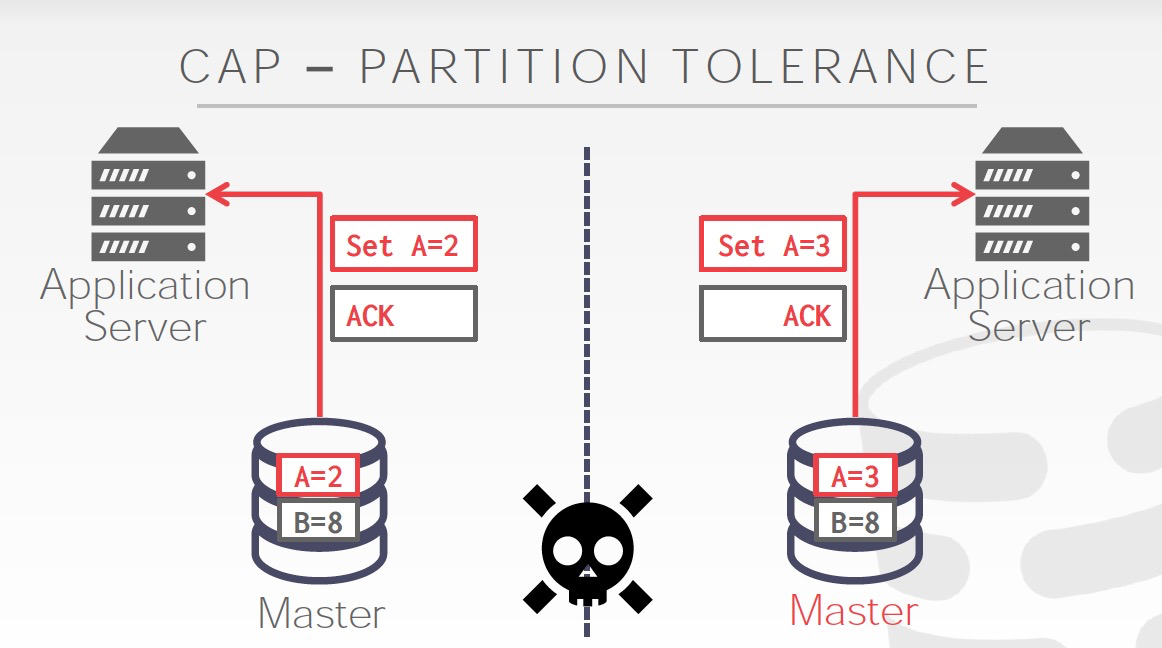
分区容错,分区间失联(可能是挂了,也有可能是由于网络导致脑裂),那么这种情况下需要选择,
选可用性,如下图,你可以脑裂的情况下,继续写,但是数据就不一致了
选一致性,根据不同的策略,判断是否可写,比如传统2PC只能等,Paxos要求多数可写
OLAP
传统OLAP是个数仓概念,
通过ETL把TP中的数据同步到数仓

数据的存储结构,主要分为两种,
星型和雪花型
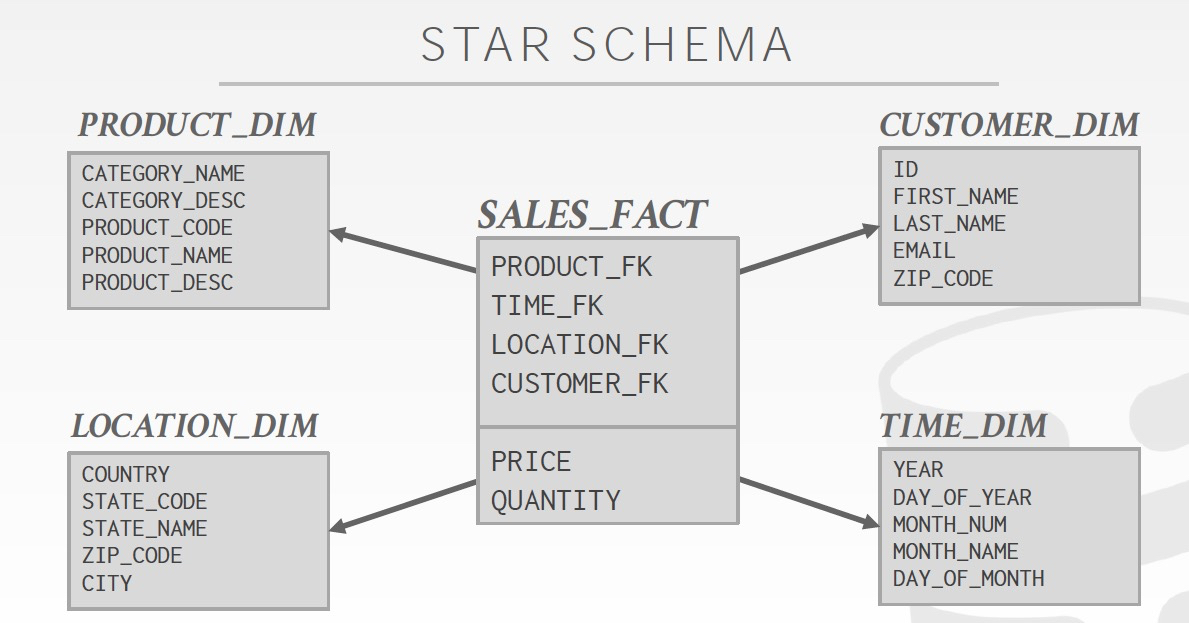
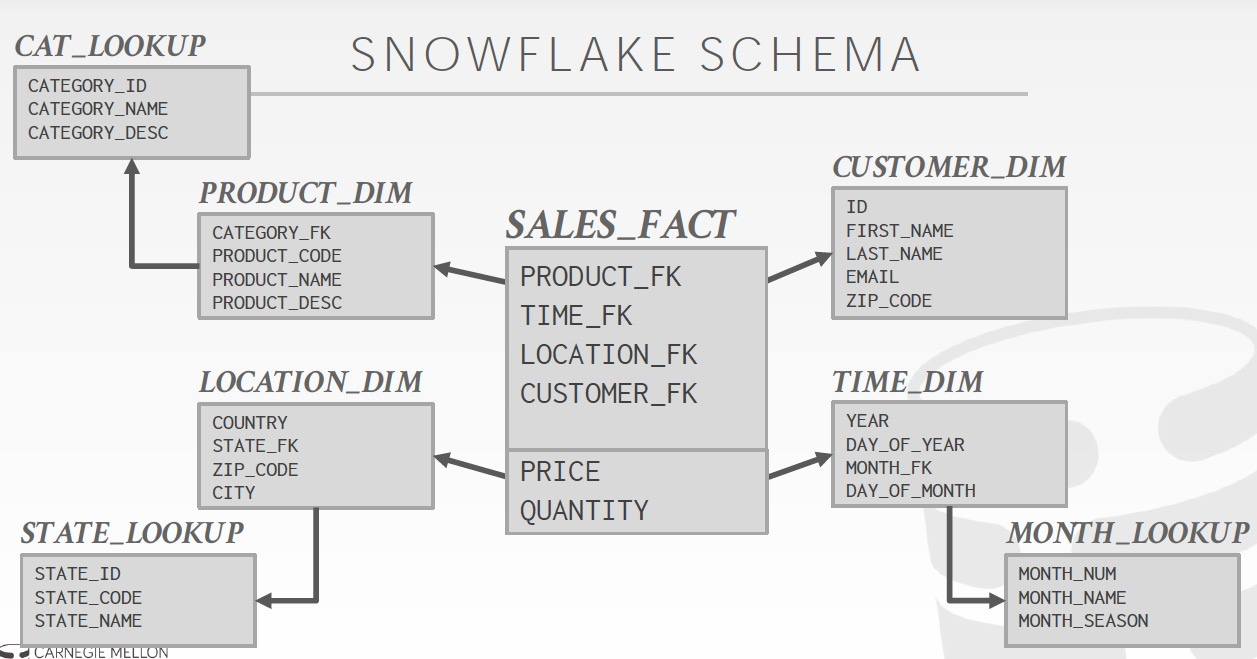
Star,只有一层维表,而雪花会有多层维表
维表少,说明非范式化,那么查询比较简单,一层join;但是存储空间比较大,而且修改比较麻烦,但是对于AP这不是大问题

Agenda

Execution Models
分成,push,pull
现在其实能push都是尽量push的,哪怕不能整条push,也会部分谓词,Join push down
这样再pull上必须的数据进行后续计算
降低计算节点的压力,也降低数据的网络传输量


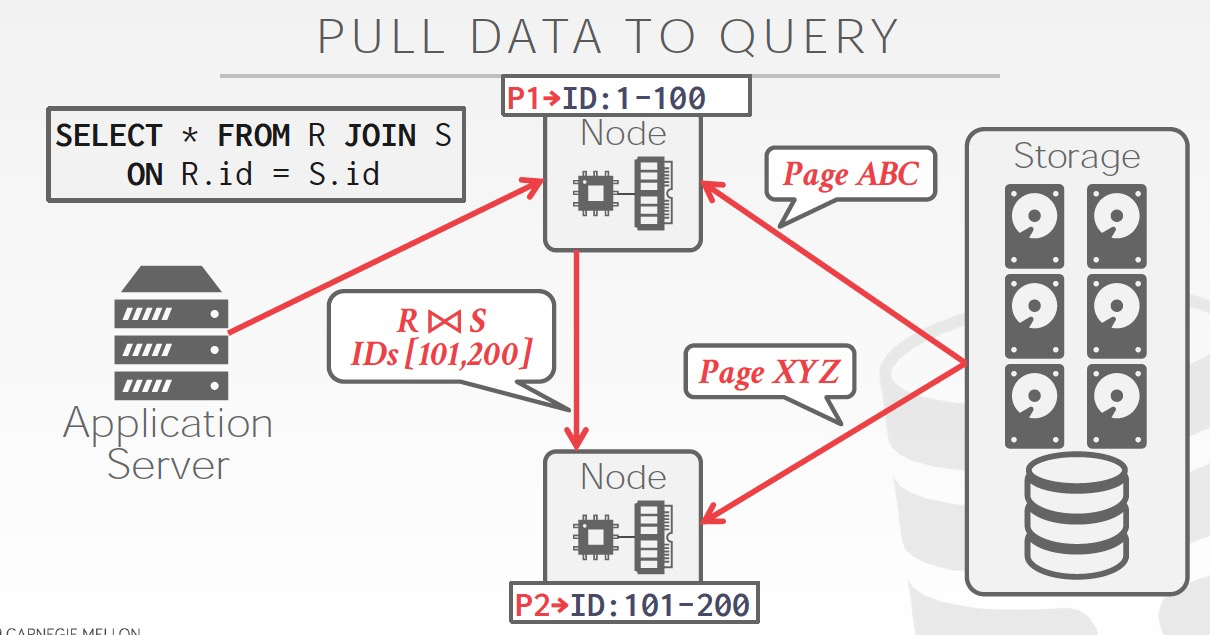
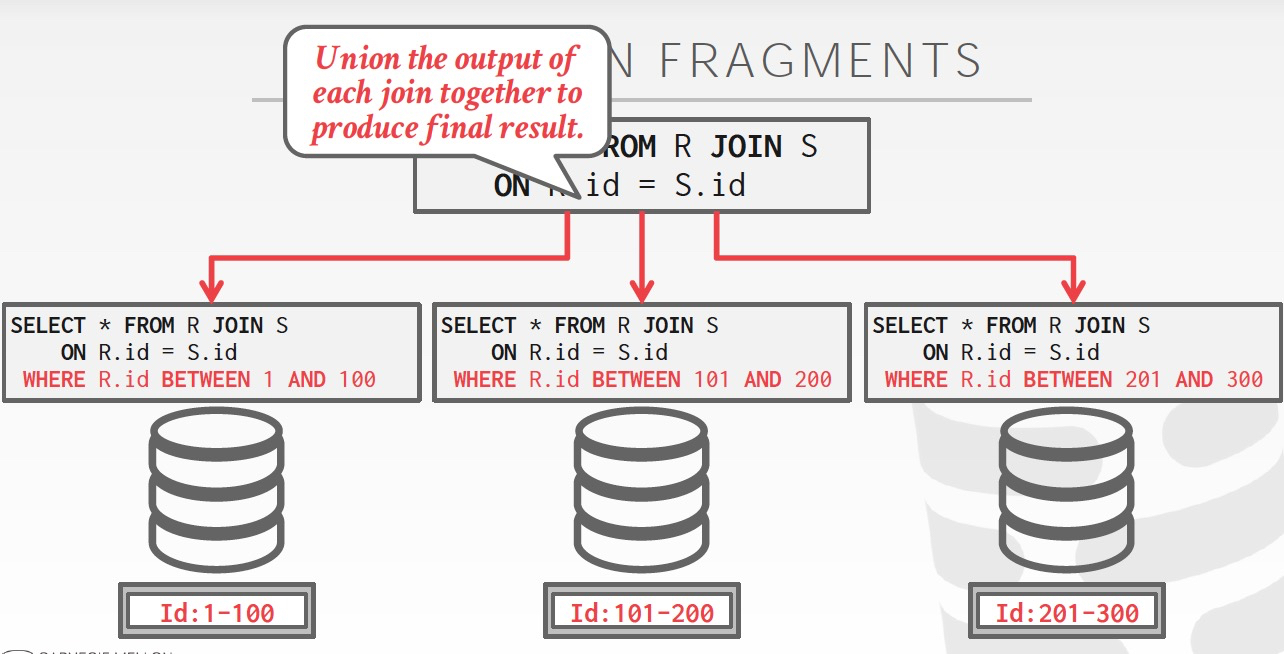
对于分布式AP,查询计划也需要打散,两种方式
一种是算子方式,大部分系统都是这么设计的
另一种是Sql的方式,一般中间件会采用这样的方式


以Sql为形式打散的例子,
分布式Join算法

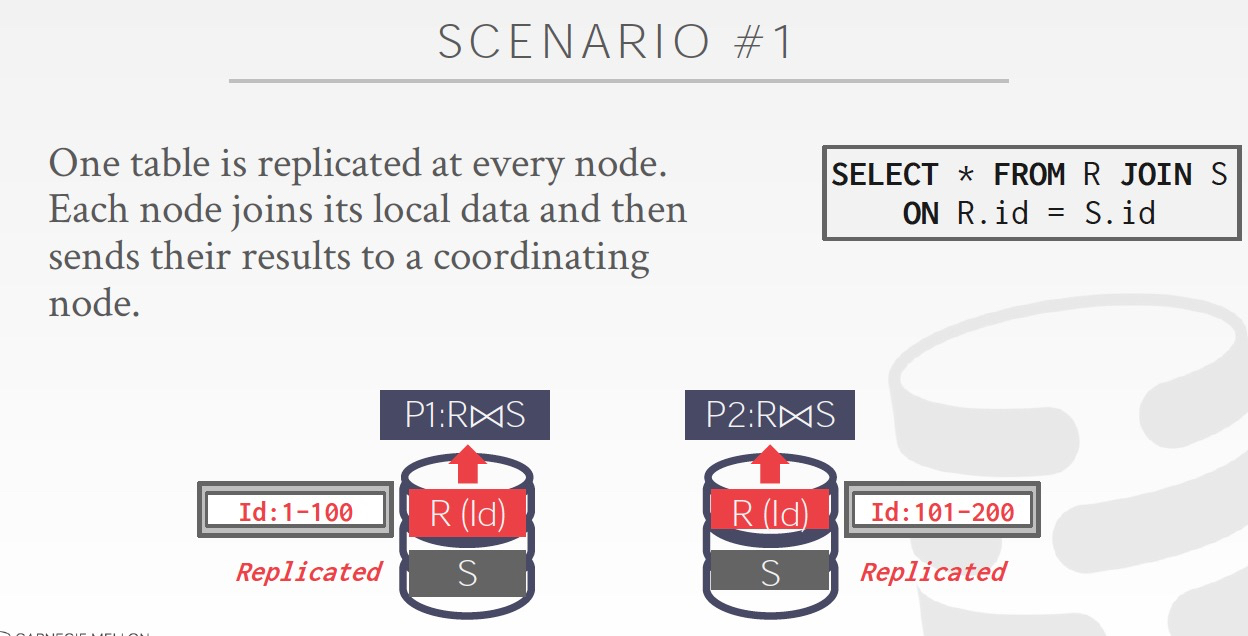
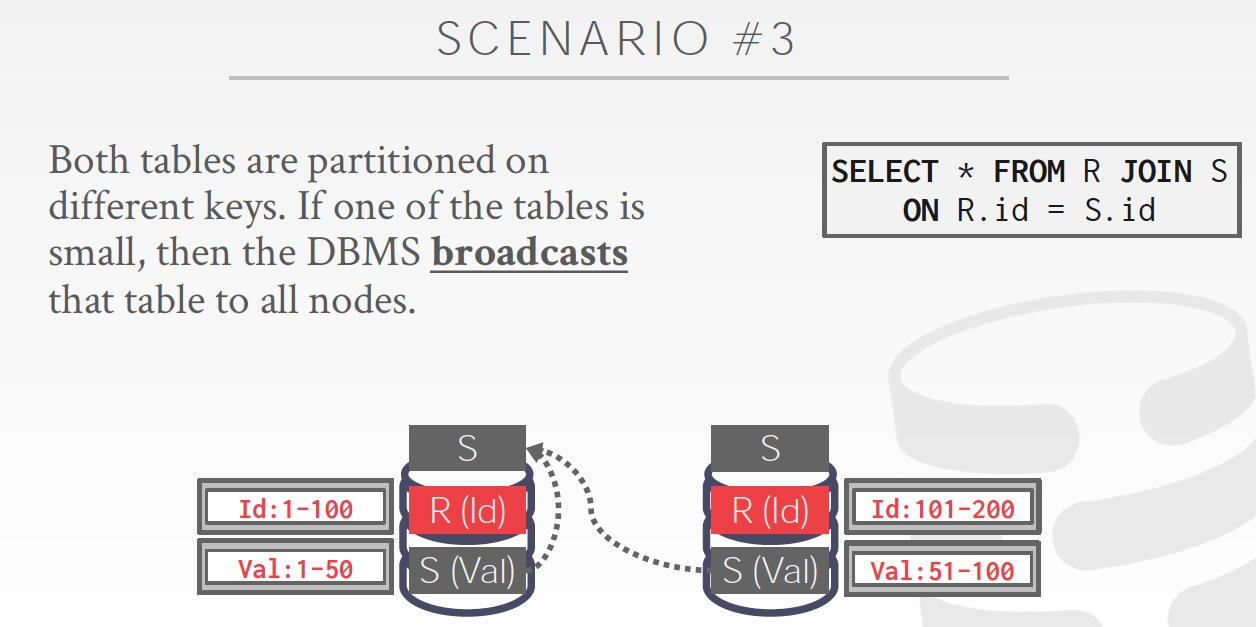
1. 小表广播
2. join key等于分区key
3. 把原先没有广播的小表,进行广播
4. 全shuffle


云数据库


数据库是否可以用通用格式存储,这样便于数据共享

