
论文源址:https://arxiv.org/abs/1512.02325
tensorflow代码:https://github.com/balancap/SSD-Tensorflow
摘要
SSD也为单阶段的网络,在feature map的每个feature map像素上生成一系列不同尺寸与大小的默认框,预测时,网络输出的分数代表每个默认框中目标物的类别,同时,调整框的大小与目标物的外形更加匹配。针对不同尺寸大小的物体,网络结合不同的网络层(具有不同的分辨率)的预测值。相对于提取目标proposals,SSD消除了区域框的生成,像素或者特征重采样的过程,并将所有计算融合到一个网络中。SSD在具有较高准确率的基础上,保证了较快的检测速度。
介绍
目前,目标检测的算法为以下几类的变体:假设一些边界框,对每个框中进行特征与像素进行计算提取,后接一个高效的分类器。上述都是由于SS方法的提出,同时,Faster R-CNN基于深层特征提取proposals,虽然准确率较好,但相对于嵌入式系统来说需要占用大量的计算资源,在实现实时检测上存在一定的挑战性。Faster R-CNN处理图片只有7帧每秒。而SSD网络可以实现在VOC2007测试集取得59FPS的速度,和mAP74.%的结果。速度的提升主要是因为消除了proposals的生成,和一系列像素和特征的重采样步骤。
本文的改进如下:(1)使用一个小的卷积核预测目标物体的类别,与边界框的位置偏移。(2)使用分离的卷积核进行不同尺寸大小的检测并将这些卷积核应用到不同的feature ma中进而实现多尺寸的预测。
通过上述改进,可以使网络对于较低分辨率的输入仍可以进行较高准确率的检测。
本文贡献:
I.提出了比YOLO还快的多类别单流检测网络,准确率也较高(相比YOLO v1高(63.4%->74.3%)与faster rcnn相差不大)。
II.SSD的核心思想是,通过在feature maps上使用小的卷积核对固定数量的边界框预测类别和框的偏移。
III.通过在不同尺寸大小的feature map上进行不同的检测,提高准确率。
IV.实现了端到端的训练,提高了速度和准确率,在较低分辨率的输入图片上的表现效果也较好。
V.在PASCAL VOC,COCO,和ILSVRC数据集上效果很好。
The Single Shot Detector(SSD)
SSD基于前向卷积网络,产生一些固定尺寸大小的边界框和代表框中目标物类别的分数,最后通过使用NMS处理得到最终检测结果。
用于检测的多尺寸feature maps:在截断的base net后添加一层卷积层。这些网络层在大小上逐渐变小,同时可以实现多尺寸的检测预测。用于进行预测的卷积层各个不同。
检测的卷积预测器:网络结构如下,对于一个带下为mxnxp的特征层,一个潜在检测器的卷积核大小为3x3xp用于产生每个类别的score,或者是默认框坐标的偏移量。mxn每个位置都应用上面的卷积核,同时,产生一个输出值。预测框的输出值是相对每个feature map位置中默认边界框的偏移量。
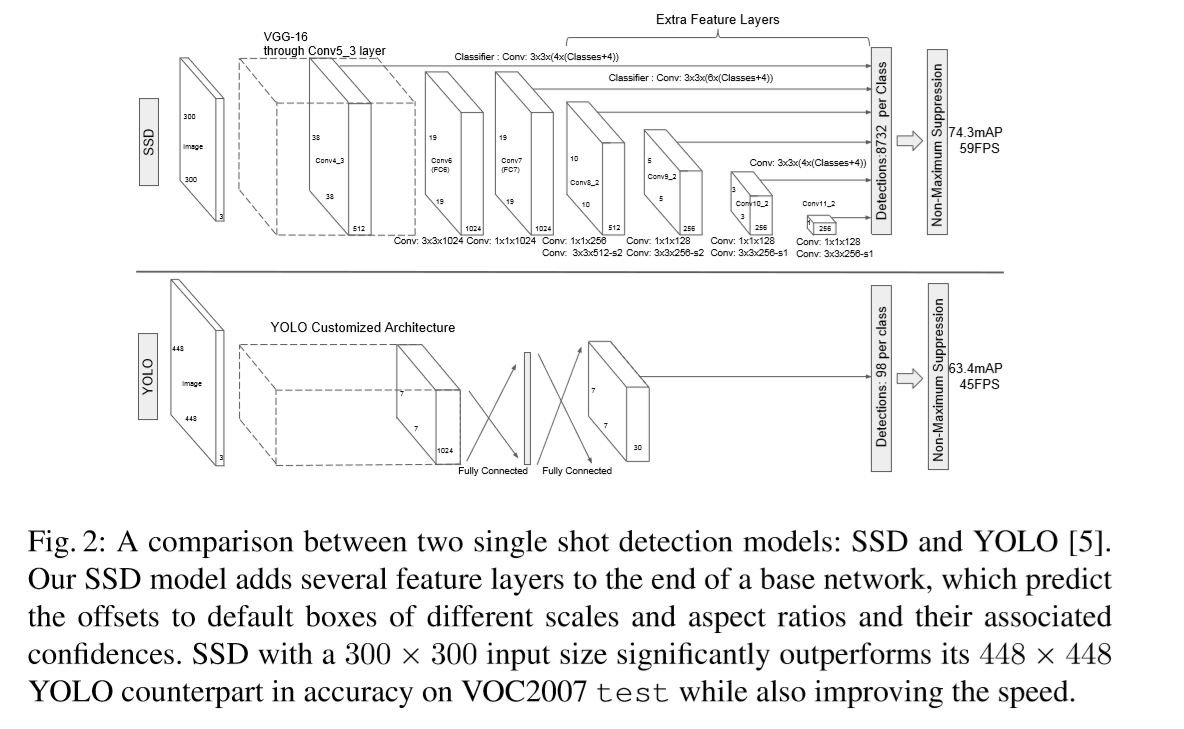
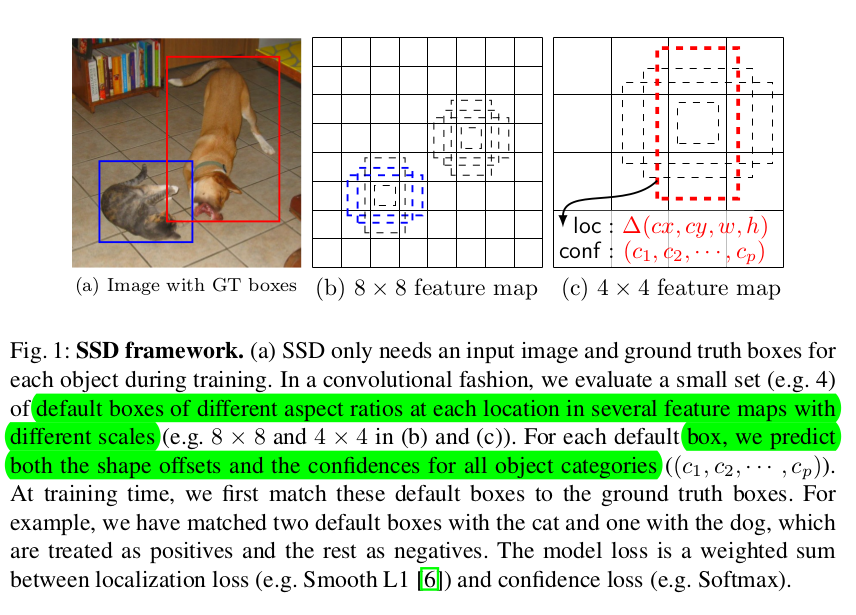
默认框及其尺寸:对于每个feature map单元设置了一系列默认的边界框。边界框以卷积的方式平铺在feature map上,因此,每个单元里每个box的位置是相对固定的。在每个feature map单元上,对每个单元中默认框外形的相对偏差,与此同时预测每个框中类别分数值。对于每个位置输出k个框,计算c个类别的分数值,及相对原始默认框大小的4个偏差值,对于feature map中的每个像素点需要(c+4)*k个卷积核,对于mxn大小的feature map需要,(c+4)*k*m*n个卷积核。默认框的生成参考Faster R-CNN的锚。本文将该思想应用到不同的feature map上从而得到不同的分辨率。
训练
SSD与经典的基于region proposal的检测方法的关键不同点在于如何将ground truth映射到default box上。映射关系确定后,损失函数和反向传播可以进行端到端的训练。训练包括默认default box的选择和检测的尺寸,像hard negative mining 和数据增强策略。
匹配策略: 训练时,需要确认与ground truth 相关的默认框并对网络进行训练。对于每个ground truth box,根据不同的位置,缩放比例,尺寸等来选择默认box。通过将ground truth 与默认box进行IOU计算进行匹配,选择最大的为正样本,其次,将与任意ground truth IOU计算大于0.5的default boxes进行匹配作为正样本。这里简化了学习问题,允许网络预测出多个不同IOU的default boxes的分数,而不是从中挑一个重叠度最大的一个。
目标的训练:
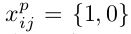 代表第i个default box与第j个类别为p的ground truth box是否匹配。损失函数如下,
代表第i个default box与第j个类别为p的ground truth box是否匹配。损失函数如下,

default box尺寸和比例的选择:SSD受分割网络的启发,结合低层与高层feature maps用于检测。如下图所示,
同一网络中不同的网络层具有不同的感受野,SSD框架由于有default box的存在不需要将每层的感受野要与所在的网络层进行对应。假设预测需要使用m个feature maps。针对每个feature map default box尺寸的定义如下:
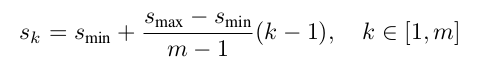

Hard negative mining:在进行匹配确定正负样本的步骤中,大多数的default boxes是负样本,这会导致训练时正负样本之间的不平衡。为此对负样本进行挑选,
(1)对于每个default box根据confidence 的损失由大到小的进行排序(2)挑选最高的几个调整正负样本的比例为3:1。
数据增强:(1)使用全部原始图片(2)使用IOU和目标物体为0.1, 0.3,0.5, 0.7, 0.9的patch (这些 patch 在原图的大小的 [0.1,1] 之间, 相应的宽高比在[1/2,2]之间)(3)随机进行裁剪 保留ground truth与采样的patch重叠的部分,采样完成后,将patch resize至固定尺寸,并以0.5的概率进行水平反转。
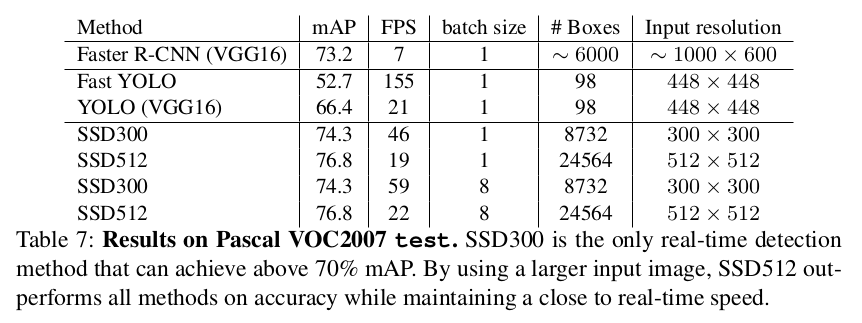
实验
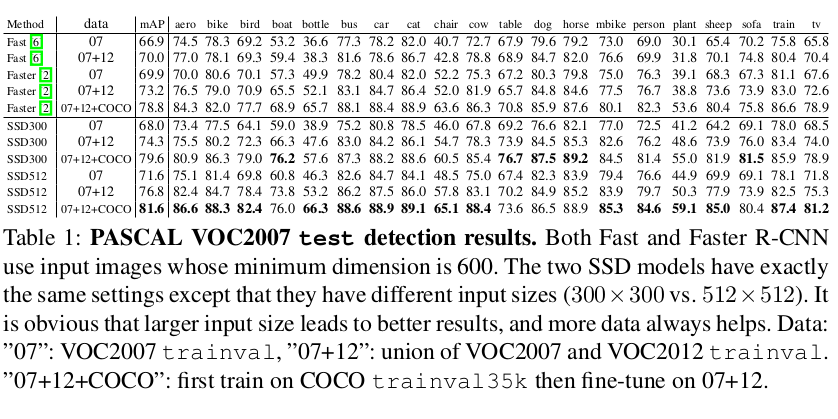


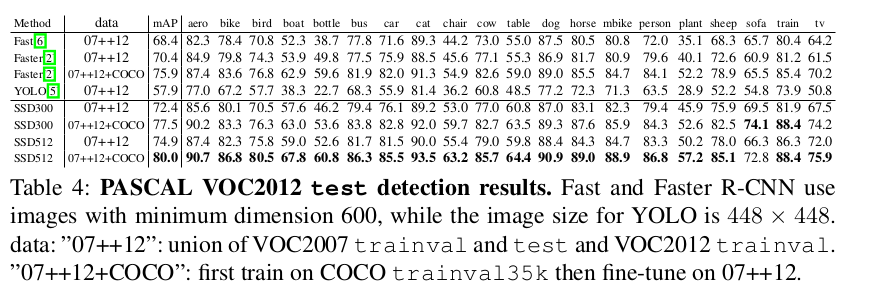
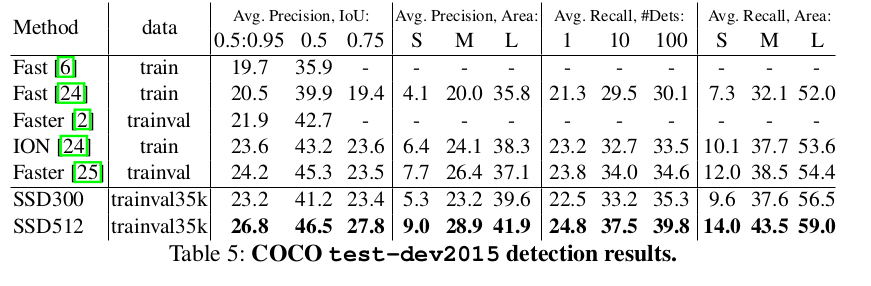
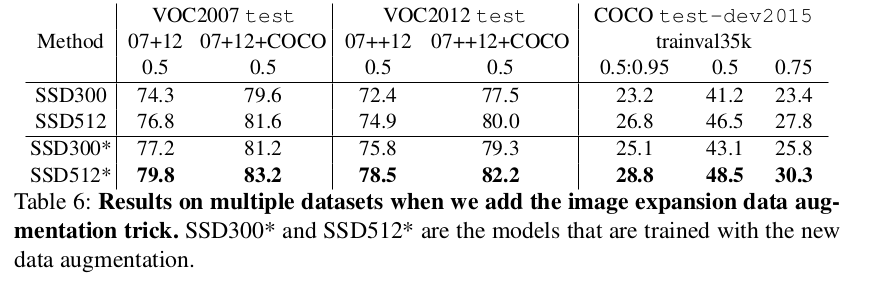
Reference
1. Uijlings, J.R., van de Sande, K.E., Gevers, T., Smeulders, A.W.: Selective search for object
recognition. IJCV (2013)
2. Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards real-time object detection
with region proposal networks. In: NIPS. (2015)
3. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR.
(2016)
4. Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., LeCun, Y.: Overfeat: Integrated
recognition, localization and detection using convolutional networks. In: ICLR. (2014)