1.多体并行存储器
多体并行交叉存储器是由多个独立的、容量相同的存储模块构成的多体模块存储器。它解决的主要问题是提高主存储器的数据传输速率。
多体并行存储器分为高位交叉编址和低位交叉编址两种。
2.高位交叉编址
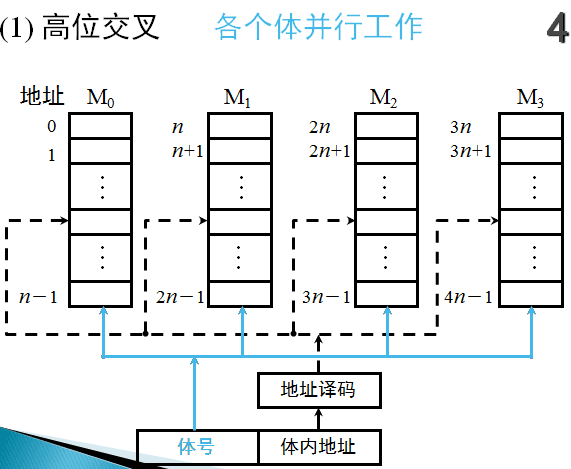
图是适合于并行工作的高位交叉编址的多体存储器结构示意图,图中程序因按体内地址顺序存放(一个体存满后,再存入下一个体),故又有顺序存储之称。
高位地址可表示体号,低位地址为体内地址。按这种编址方式,只要合理调动,使不同的请求源同时访问不同的体,便可实现并行工作。
例如,当一个体正与CPU交换信息时,另一个体可同时与外部设备进行直接存储器访问,实现两个体并行工作。
3.低位交叉编址:
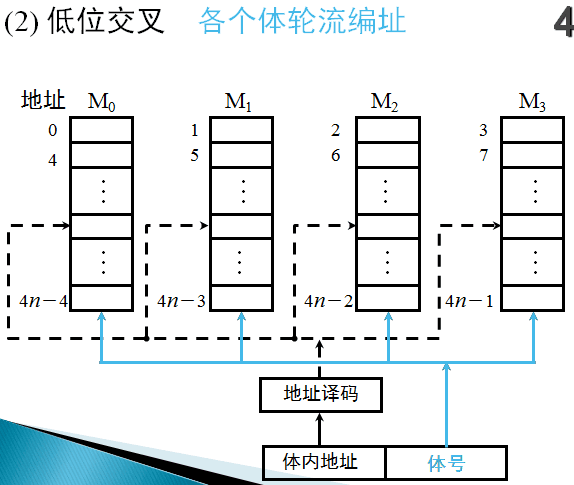
图是低位交叉编址的多体模块结构示意图。由于程序连续存放在相邻体中,故又有交叉存储之称。
低位地址用来表示体号,高位地址为体内地址。这种编址方式又称为模M编址(M等于模块数),一般模块数取2的方幂,使硬件电路比较简单。有的机器为了减少存储器冲突,采取质数个模块。
4.理解
对于高位交叉编址比较好理解,就像单元号与房号。体号就是单元号,找到程序在体,体内地址就是房号,找到程序的开始位置。
如何理解程序连续放在相邻的体中,我们举个实际例子:
存储体的有2个存储芯片,存储周期为100ns,数据按放置方法,先放第一个芯片,放满后再放第2个芯片(顺序方式)。
那么你读数据的过程就是这样:读0位置数据,等100ns,读1位置数据,等100ns读2位置数据。
但如果换个方式来放,0位置是1号芯片起始,1位置是2号芯片起始位置,2位置是1号芯片第2个单元,3位置是2号芯片的第2个单元这样交叉来编址。
再回忆存取周期的概念:存取周期等于存取时间+恢复时间,你读一个芯片后,必须间隔一段时间才能去读。采用交叉编址后,你的读过程就像这样:
读0位置数据到缓冲区,40ns后,CPU取走了数据。这时1号芯片的100ns的周期还没过,不能去读,但幸运的是我们读的不是1号芯片,而是2号芯片,这样,我们就把2号芯片的数据读到缓冲区。过了40ns后,CPU取走数据,此时过去了80ns,我们只需再等20ns就可以继续去读3号位置数据,这样速度就比以前快了很多。
参考博客链接:https://blog.csdn.net/nuo_Shar/article/details/79048019