概要
最近的语义分割方法都在探索encoder-decoder结构。一般这种结构中的encoder产生较小分辨率的feature map,然后最后的decoder通过双线性上采样来得到像素级的预测。作者认为这种方法太简单粗暴是次优的,所以提出了一种新的上采样方法:Dupsampling,这种方法最大的优势在于它能应用于比较小分辨率的feature map,而且得到的结果比之前的更好。也就是这种方法重构能力强,灵活性高,而且计算消耗少。

DeepLabV3+的结构
双线性上采样是独立于数据的,没有考虑每一个像素预测之间的关联,主要有两个问题:
-
若从较高分辨率去恢复预测结果,计算消耗高
-
高分辨率的feature才能得到较精确的预测结果,不灵活限制了feature聚合策略的设计空间
方法
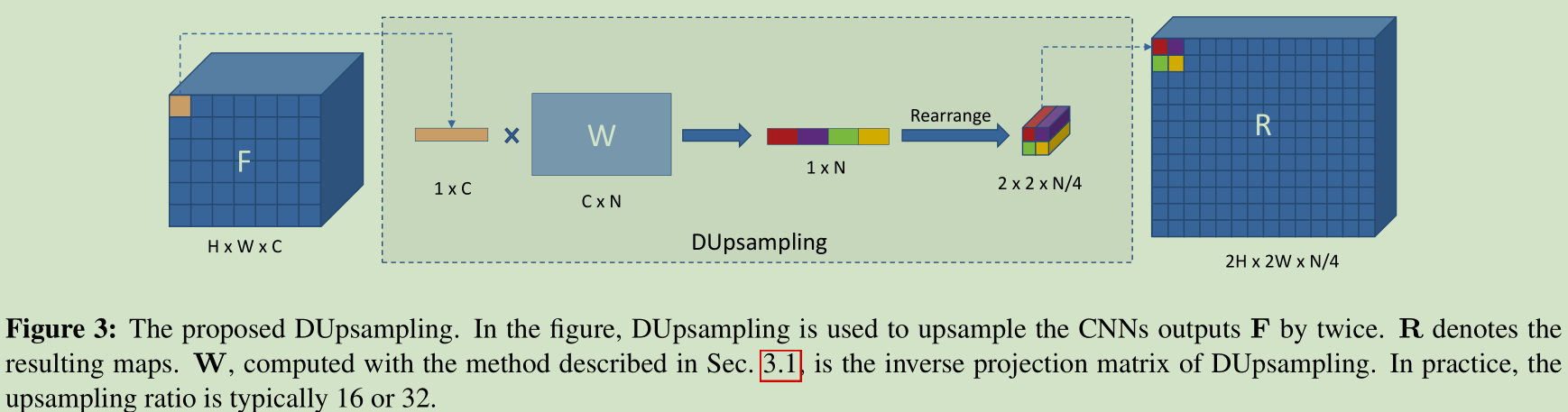
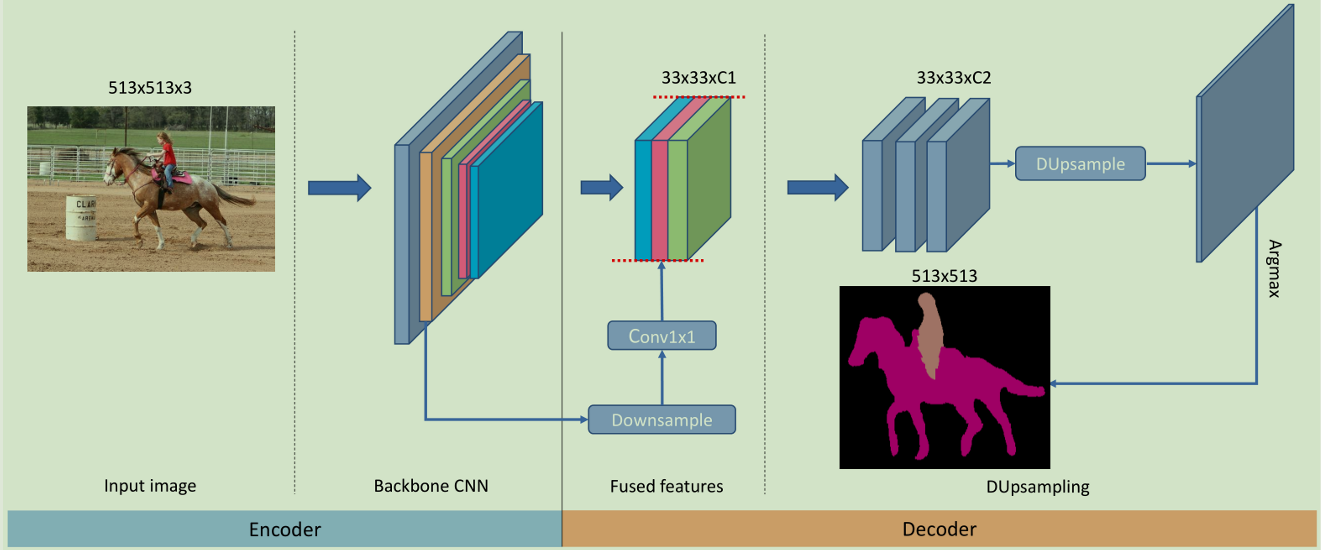
作者的一个重要发现就是一张图像的label不是i.i.d(独立同分布)的,包含着结构信息也就是存在关联,因此可以压缩label而且能够依赖这种结构信息重构label而不会有太多的损失。所以作者先把label进行压缩,压缩首先将label分成多个格子,每个格子大小是t x t(就是图像大小比例,如16,32),然后对每一个格子中的内容reshape成一个向量v,然后将v压缩成x,然后堆叠x就能得到压缩后的标签
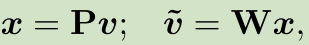
通过P将v线性映射到x,W是反映射矩阵也就是重构矩阵。通过下面公式最小化重构误差,通过SGD迭代进行优化,使用PCA能够求得闭合解P,W
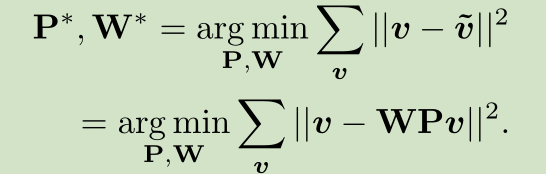
以压缩后的标签为目标,可以构造如下损失函数,就能去训练网络,这个网络能够使F趋近于压缩后的标签,然后 F*W 计算就得到预测结果。
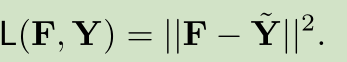
但作者没有这么做,而是采用了更直接的方式,直接在label空间计算损失。这里的DUpsampling是F*W,相比于上面的公式,这个只是直接计算和label的损失,而不是上面计算和压缩label的损失。

这里的DUsampling在本质上可以用1x1conv来实现,W就是卷积核的参数
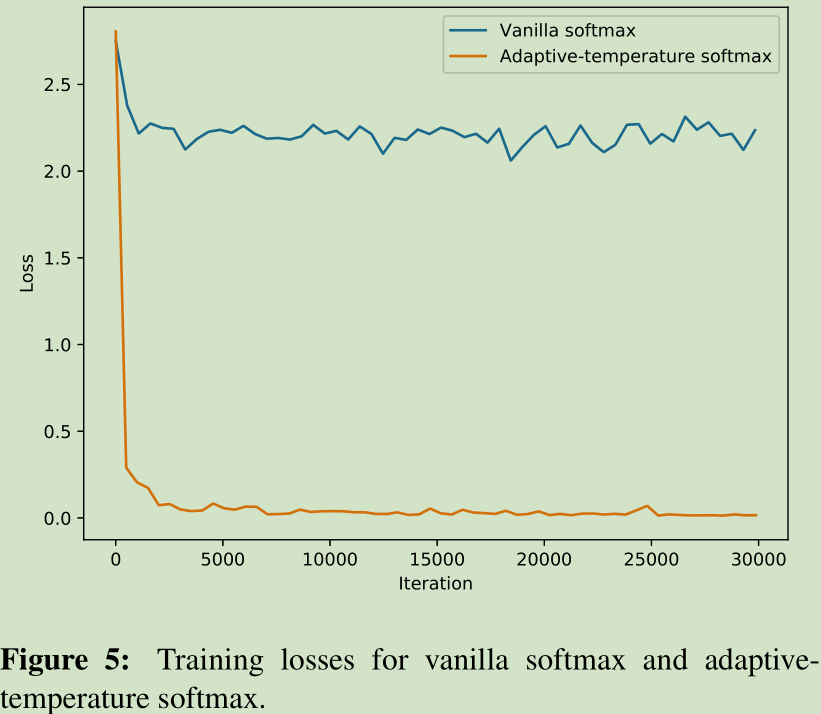
但是DUpsampling与softmax的这种组合难以产生尖锐的激活(我认为是产生的各元素的概率差别很大),也就是概率分布比较平滑,这样导致训练时的损失计算会卡住。产生这种现象的原因作者认为可能是因为W是根据one-hot的label计算得到的,因此为了解决这个问题引入了 adaptive-temperature softmax
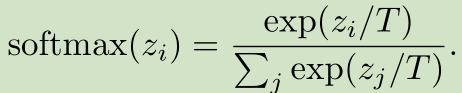
就是在计算时给各元素除以T即可,当T>0时,会变得比较soft;当T<0时,会变得比较sharp,另外T是可以自动的去学习得到
采用了上述方法后可以将low_level feature下采样后与last feature融合,然后DUpsampling进行预测,这种方式比DeepLabV3+中的上采样-融合-再上采样的策略更灵活,计算消耗也小,速度更快。
实验
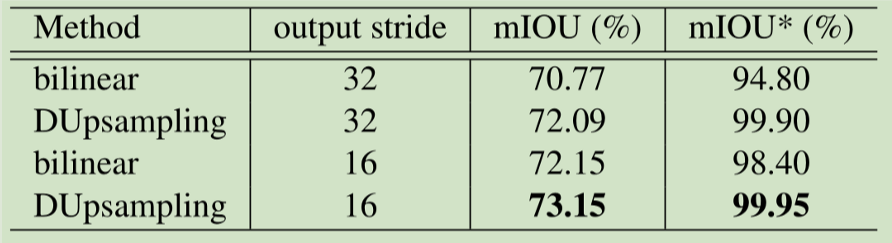
PASCAL VOC val set 的结果


总结
提出了针对decoder的一个上采样方法DUpsampling,最大的特点是在较低的分辨率进行上采样也能够得到较好的效果,不过需要去预训练网络得到1x1conv核参数W,从论文中看W好像是固定的,那如果随着网络的优化去学习W,那效果不知道会怎么样。