概要
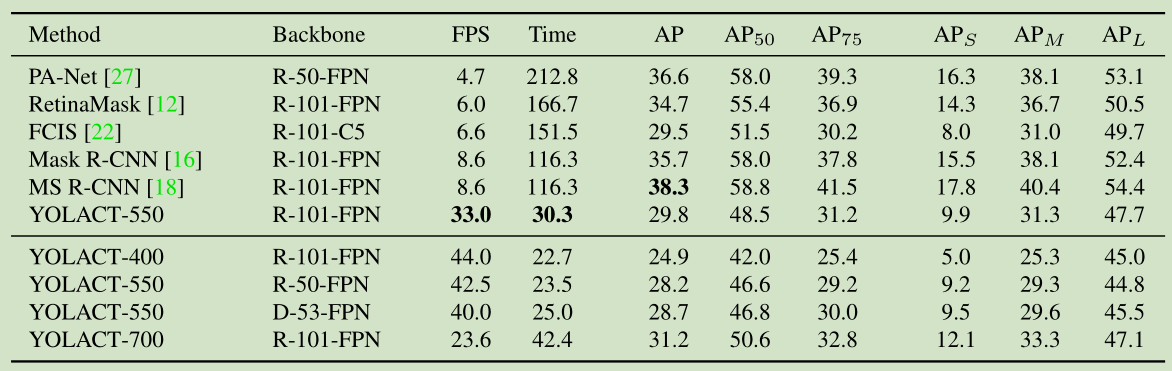
达到实时的实例分割模型:29.8mAP,33fps,单GPU。将实例分割分为两个子任务:(1)生成一组针对全图的原型mask(2)预测每一个实例的mask系数,然后线性组合原型和mask系数。不依赖于repooling,能得到高质量的mask,而且很快。
结构方法
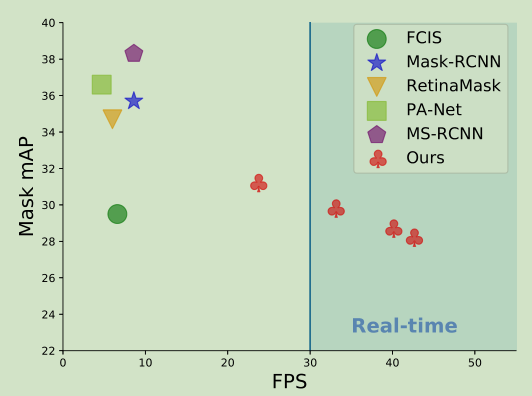
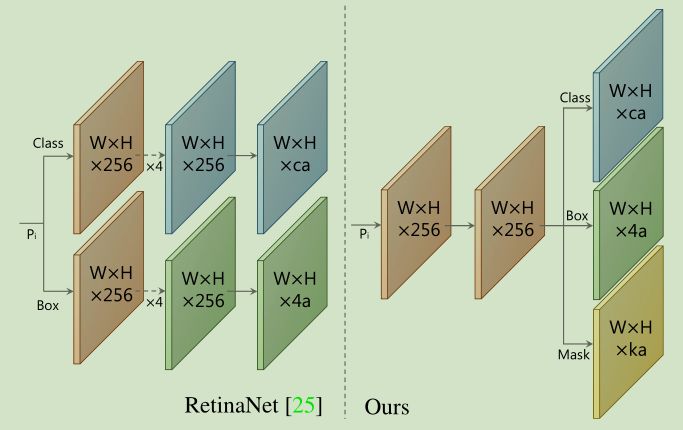
整体结构不是特别复杂,backbone采用的是retinanet。backbone之后是两个并行分支:一个是protonet,另一个是prediction head。然后将两个分支的结果线性组合起来得到mask。
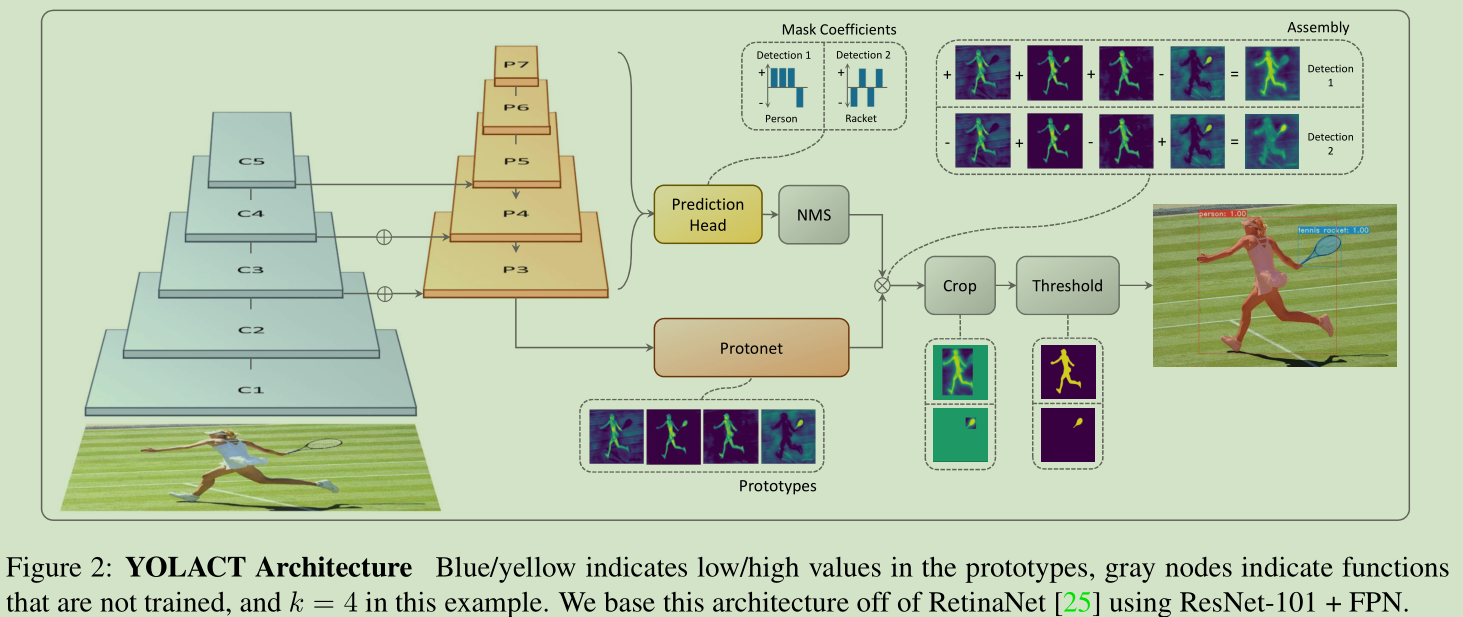
backbone采用ResNet-101-FPN,其中FPN的结构变为和retina相同,从P3到P7,相应的anchor的大小为[24, 48, 96, 192, 384]
首先是protonet,将backbone中的P3层特征抽取出来经过3个(3 imes3)卷积,然后再upsampling + (3 imes3)卷积变为原图的四分之一大小,最后(1 imes1)卷积降低通道数至k,k对应着prototypes的个数。这个prototypes实际上就是一些单通道的特征图,只不过经过训练后这些特征图能对于目标产生不同的激活,每个prototype负责不同部位的激活,那么组合起来就能够得到整个目标的激活。另外k也是可以变化的,不过实验表明不同的k对于结果影响不大。
然后是mask系数。典型的基于anchor的目标检测器有两个输出:分类数和边框回归量。这里又加了一个输出mask系数。也就是对于每一个边框输出c个分数,4个回归量,k个mask系数。mask系数一一对应着上面的prototypes。因为可能要减去背景,所以mask系数需要有负数,采用tanh非线性函数。
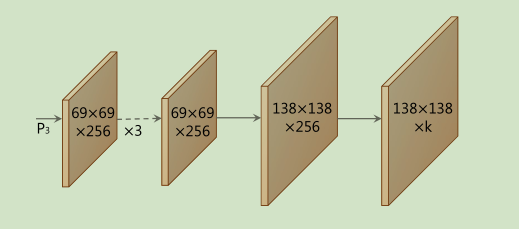
prediction head如下所示,和retina不同三个输出仅共享一个(3 imes3)卷积,然后各自经过(3 imes3)的卷积。其中a是P3中的anchor数
最后,线性组合mask系数和prototypes,公式如:
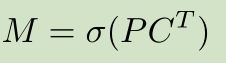
其中(P)为(h imes w imes k)的prototype mask的矩阵,是用边框裁剪出来的,而不是原图大小,(C)为(n imes k)的mask系数矩阵,(n)为NMS后的边框个数,(sigma)是sigmoid函数。就是相当于给prototypes分别给了一个权重,然后线性组合在一起。
3个损失函数:(L_{cls}, L_{box}, L_{mask}),(L_{mask} = BCE(M, M_{gt})),这里的(M)是边框大小的最终的mask,然后在计算(L_{mask})时还除以了ground truth边框的面积,也就是缩小了(L_{mask})。论文中说是为了保护小目标,我理解的是对于小物体面积小,mask损失就大,对于大目标面积大,mask损失小,因此对于小目标预测不准确的惩罚更大一些,网络也就更重视小目标。当然在预测的时候,用预测边框进行裁剪。

另外作者解释了为什么YOLACT能够根据prototypes中不同的激活来定位目标,作者认为在ResNet中有着平移变化的属性,而YOLACT正好利用了这种属性。我们常说的神经网络具有平移不变性指的是卷积+池化所具有的的,而且我认为这种平移不变性也只是一定限度的。生成prototypes所用的P3层特征也只经过一次(3 imes 3)的最大池化,所以可以说ResNet具有平移变化属性,也就是对位置敏感,因而能够得到在不同位置的激活。
Fast NMS比传统的NMS要更快,但会损失一些性能。传统NMS会去除与最高分框重叠高于一定阈值的框,而Fast NMS却允许那些已经确定要被去除的框来抑制分数更低的框。具体过程如下:假设有c类,n个预测框,首先按分数对框排序,然后计算彼此之间的IoU值,得到一个(c imes n imes n)的IoU矩阵X,因为每个框都可以进行c个类别的回归修正,可得到(c imes n)个框,再求两两框之间的IoU就得到矩阵。之后将矩阵下三角置零只用上三角,在列方向上去寻找最大值:
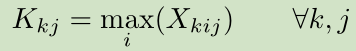
,对于每一类k,寻找每一列k中IoU的最大值,记为(K_{ij})。对于(K)中(K_{ij} < t)表明第(j)框与前面所以的框重叠没有超过阈值,是要保留下来的框,(K_{ij} > t)表明第(j)框与前面的某一个框的重叠超过阈值,因此对应的(j)框是要去掉的框。
Fast NMS为什么会快呢?传统的NMS一类一类的去遍历,在每一类的框中先排序,然后遍历每一个框去除那些与当前框重叠高于阈值的框,可以看出这几个过程都是顺序的进行的。论文中说Fast NMS的排序在GPU上进行batch 排序,感觉就并行的进行多个类别的排序吧,然后计算IoU矩阵也可以向量化的去计算。最后是在IoU矩阵列方向上求最大值得到的还是矩阵,与阈值比较就能确定要保留和去除的框。也就是说Fast NMS将这整个过程用矩阵或者向量并行化了,而不是顺序的去计算。
论文中提到Fast NMS会比传统NMS多去除一些框,为什么?假设在计算时(j =2)的框是要被去除掉的,但计算(j=3)时与它重叠最高的框是(j =2),若是传统NMS则只会去除(j=2),不会去除(j=3),因为计算(j = 3)时(j=2)的框已经去除掉了不作比较,因此(j=3)框保留下来。而Fast NMS因为是并行计算所以也会同时去除(j= 2, j=3)的框。如果这种情况多一些,多去除一些框也就说的通了。
实验结果

YOLACT快是挺快,但AP就不行了。不过在阈值为0.95时的表现还是挺好的,超过了Mask R-CNN,上图中的可视化结果表现出的mask质量确实YOLACT好一些。