MNIST是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会被用作深度学习的入门样例。而TensorFlow的封装让使用MNIST数据集变得更加方便。MNIST数据集是NIST数据集的一个子集,它包含了60000张图片作为训练数据,10000张图片作为测试数据。在MNIST数据集中的每一张图片都代表了0~9中的一个数字。图片的大小都为28*28,且数字都会出现在图片的正中间,如下图所示:
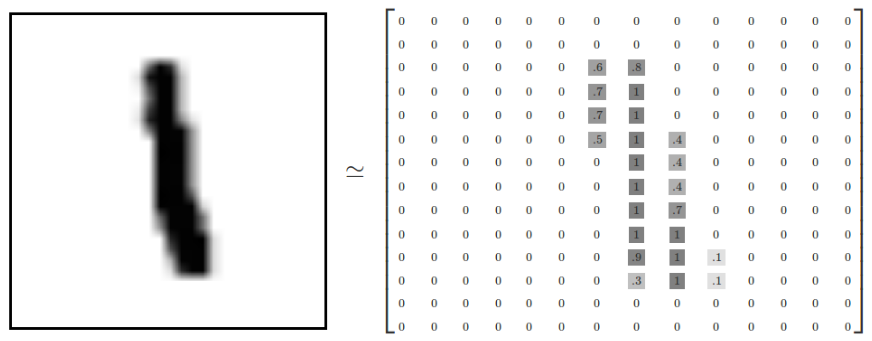
在上图中右侧显示了一张数字1的图片,而右侧显示了这个图片所对应的像素矩阵,MNIST数据集提供了4个下载文件,具体参考①,在tensorflow中可将这四个文件直接下载放于一个目录中并加载,如下代码input_data.read_data_sets所示,如果指定目录中没有数据,那么tensorflow会自动去网络上进行下载。下面代码介绍了如何使用tensorflow操作MNIST数据集。
from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf mnist = input_data.read_data_sets('/home/workspace/python/tf/data/mnist',one_hot=True) # 打印“Training data size: 55000” print "Training data size: ",mnist.train.num_examples # 打印“Validating data size: 5000” print "Validating data size: ",mnist.validation.num_examples # 打印“Testing data size: 10000” print "Testing data size: ",mnist.test.num_examples # 打印“Example training data: [0. 0. 0. ... 0.380 0.376 ... 0.]” print "Example training data: ",mnist.train.images[0] # 打印“Example training data label: [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]” print "Example training data label: ",mnist.train.labels[0] batch_size = 100 # 从train的集合中选取batch_size个训练数据 xs, ys = mnist.train.next_batch(batch_size) # 输出“X shape:(100,784)” print "X shape: ", xs.shape # 输出"Y shape:(100,10)" print "Y shape: ", ys.shape
从上面的代码中可以看出,通过input_data.read_data_sets函数生成的类会自动将MNIST数据集划分为train, validation和test三个数据集,其中train这个集合内含有55000张图片,validation集合内含有5000张图片,这两个集合组成了MNIST本身提供的训练数据集。test集合内有10000张图片,这些图片都来自与MNIST提供的测试数据集。处理后的每一张图片是一个长度为784的一维数组,这个数组中的元素对应了图片像素矩阵中的每一个数字(28*28=784)。因为神经网络的输入是一个特征向量,所以在此把一张二维图像的像素矩阵放到一个一维数组中可以方便tensorflow将图片的像素矩阵提供给神经网络的输入层。像素矩阵中元素的取值范围为[0, 1],它代表了颜色的深浅。其中0表示白色背景,1表示黑色前景。为了方便使用随机梯度下降,input_data.read_data_sets函数生成的类还提供了mnist.train.next_batch函数,它可以从所有的训练数据中读取一小部分作为一个训练batch。
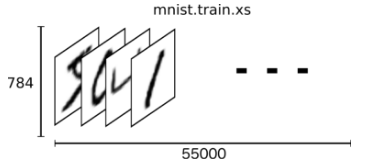
mnist.train.xs训练集特征
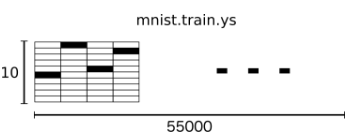
mnist.train.ys训练集分类标签
软件版本
TensorFlow 1.0.1 + Python 2.7.12
参考
①、Yann LeCun教授网站中对MNIST数据集的详细介绍及数据下载。
②、tensorflow官网对MNIST数据集的介绍及部分操作。
③、《TensorFlow实战Google深度学习框架》第五章。