第一讲:介绍
1.学习大数据原因:
数据源∶非结构化数据(语音、视频、文本、网络数据)
模型和计算能力∶深度学习、GPU、分布式系统
广泛的应用场景∶营销、广告、金融、交通、医疗等
2.公式
Data Data:数据 丨 X︰表示、特征、指标
丨 F︰模型
↓ Y : 智慧,也即预测任务或目标 Y =F(X)
大数据是指数据采集、清洗、分析和应用的整个流程中的理论、技术和方法。
机器学习是大数据分析的核心内容。由XY找到F。
深度学习是机器学习的一部分,其核心是自动找到对特定任务有效的特征,也即自动完成Data到X的转换。
3.方法
有监督学习( supervised learning ) 数据集中的样本带有标签,有明确目标。
应用场景∶垃圾邮件分类、病理切片分类、客户流失预警、客户风险评估、房价预测等。
典型方法:
回归模型:线性回归、岭回归、LASSO和回归样条等
分类模型:逻辑回归、K近邻、决策树、支持向量机等
无监督学习( unsupervised learning ) 数据集中的样本没有标签,没有明确目标 聚类、降维、排序、密度估计、关联规则挖掘
聚类:将数据集中相似的样本进行分组,使得同一组对象之间尽可能相似;不同组对象之间尽可能不相似。
应用场景:基因表达水平聚类、篮球运动员划分、客户分析。
强化学习( reinforcement learning ) 智慧决策的过程,通过过程模拟和观察来不断学习、提高决策能力。
4.基本概念
数据集:一组样本的集合。 样本∶数据集的一行。一个样本包含一个或多个特征,此外还可能包含一个标签。 特征:在进行预测时使用的输入变量。
训练集:用于训练模型的数据集 测试集:用于测试模型的数据集 模型∶建立数据的输入x和输出y之间的映射关系y = f()。
损失函数:L(yi, f(xi))例如,对回归问题可以定义为(f(xi)一 yi)^2。
一般流程(有监督):
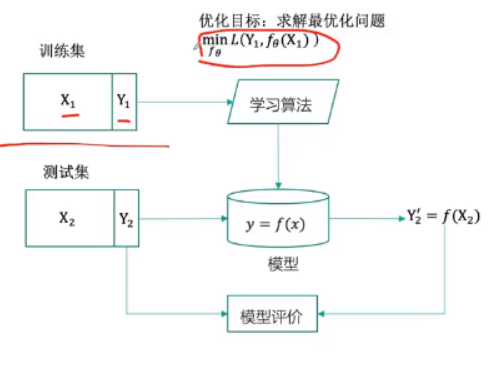
过度拟合:模型过于复杂,会导致对位置数据预测很差。解决方式:正则化.
数据选取:交叉验证、K折交叉验证。
交叉验证:基本想法是重复地使用数据。将数据集随机切分,将切分的数据集组合为训练集和测试集,在此基础上反复进行训练,测试和模型选择。
5.数学结构
度量、网格、代数、几何等结构。
①度量结构:
距离:曼哈顿、欧式、极大距离。
方法:K近邻。
②网格结构:有度量结构定义一个网格结构。表示为G=<V,E>V:节点 E:边
例如两个样本的距离小于某个阈值,就连一条边。 也可以进一步将边赋予权重,权重就是两个样本的相似度。
算法:PageRank算法
