实验室最近有同学在训练ImageNet数据集,训练的开始阶段训练的十分的缓慢,由于这个项目是国家级的项目,实验室的领导也是十分在意,或者说是非常的关切,作为服务器的维护人员我就被拽出来解决问题了。刚看到这个问题我也有些懵逼,反馈的是CPU和GPU的使用率占比不高,怀疑是服务器坏了,这个怀疑着实吓了我一跳,赶紧核实情况,给出运行时CPU、GPU的使用情况:
CPU使用情况:
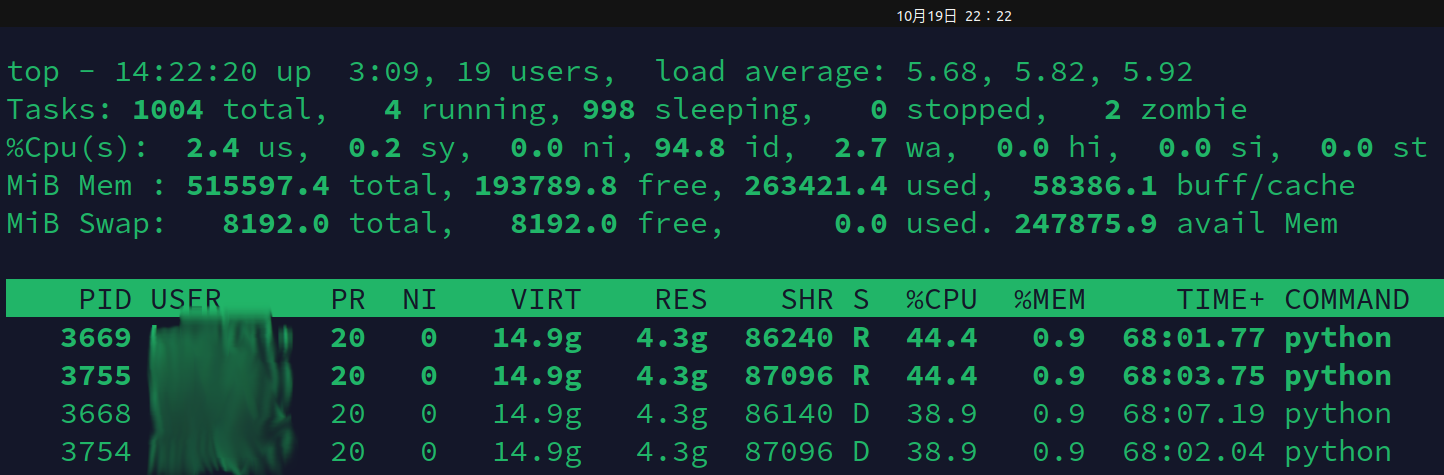
虽然跑的的是深度学习的代码,但是计算操作应该都是在GPU端进行的,因此CPU端应该都是单进程单线程的,这种大的假设之下可以看到项目运行的几个进程:
3754、3755、3668、3669都是运行在单核心的50%使用率以内的,甚至可以说是运行在单核心的40%使用率左右的,由于深度学习可以视作计算密集形的计算任务,因此可以认为这个项目的运行状态是在半速的情况下运行的,甚至还不到半速。
然后看一下这几个进程的线程关系:
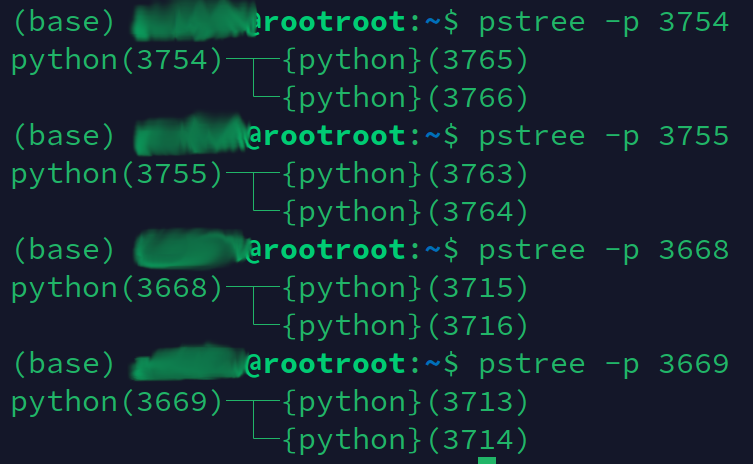
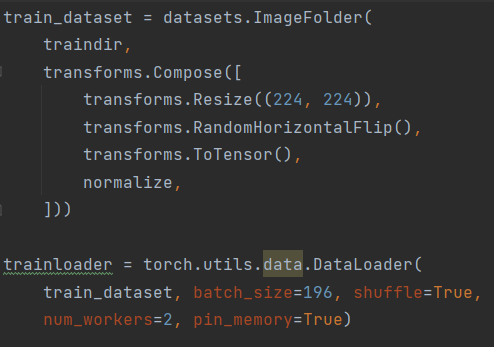
和用户沟通后得知这个项目的代码是pytorch读取数据集,然后进行训练,读取数据时采用的是双线程,代码如下:
查看完CPU后再查看GPU的使用情况:


其中,占用显卡计算的进程为3313和3508,虽然这两个进程和之前的对数据集进行读取和预处理的进程不同,但是以经验和现有情况来看这两个GPU上运行的进程和之前的四个进程是相关的,不过这里我们看到的重点是这两个GPU运行的进程有大致70%的时间使用率为0%,而有大致30%的时间使用率为100%,再结合之前CPU上运行的四个进程3754、3755、3668、3669时而是状态R(运行状态)时而是状态D(睡眠状态),由此可以大致得出结论,那就是这个项目代码在读取磁盘上数据时耗时成为计算瓶颈,导致对数据预处理的时候CPU速度只有40%左右,在CPU计算进程进行数据预处理时则为R状态,而当进行磁盘读取时则为D状态,而由于CPU端进行计算时需要周期性睡眠来等待数据读取从而导致GPU端也会存在空转现象(GPU使用率由100%周期性掉到0%)。
从进程号上我们可以得出一个推断,那就是四个进程3754、3755、3668、3669中有两个进程是为进程3313提供数据的,另外两个进程是为3508提供数据的,于是打印出进程3313和3508的线程关系:
pstree -p 3313
python(3313)─┬─python(3668)─┬─{python}(3715)
│ └─{python}(3716)
├─python(3669)─┬─{python}(3713)
│ └─{python}(3714)
├─sh(3352)
├─{python}(3356)
├─{python}(3466)
├─{python}(3470)
├─{python}(3524)
├─{python}(3525)
├─{python}(3526)
├─{python}(3527)
├─{python}(3528)
├─{python}(3529)
├─{python}(3530)
├─{python}(3531)
├─{python}(3532)
├─{python}(3533)
├─{python}(3534)
├─{python}(3535)
├─{python}(3536)
├─{python}(3537)
├─{python}(3538)
├─{python}(3539)
├─{python}(3540)
├─{python}(3541)
├─{python}(3542)
├─{python}(3543)
├─{python}(3544)
├─{python}(3545)
├─{python}(3546)
├─{python}(3547)
├─{python}(3548)
├─{python}(3549)
├─{python}(3550)
├─{python}(3551)
├─{python}(3552)
├─{python}(3553)
├─{python}(3554)
├─{python}(3555)
├─{python}(3556)
├─{python}(3557)
├─{python}(3558)
├─{python}(3559)
├─{python}(3560)
├─{python}(3561)
├─{python}(3562)
├─{python}(3563)
├─{python}(3564)
├─{python}(3565)
├─{python}(3566)
├─{python}(3567)
├─{python}(3568)
├─{python}(3569)
├─{python}(3570)
├─{python}(3670)
├─{python}(3671)
├─{python}(3672)
└─{python}(3729)
pstree -p 3508
python(3508)─┬─python(3754)─┬─{python}(3765)
│ └─{python}(3766)
├─python(3755)─┬─{python}(3763)
│ └─{python}(3764)
├─sh(3515)
├─{python}(3519)
├─{python}(3582)
├─{python}(3584)
├─{python}(3593)
├─{python}(3594)
├─{python}(3595)
├─{python}(3596)
├─{python}(3597)
├─{python}(3598)
├─{python}(3599)
├─{python}(3600)
├─{python}(3601)
├─{python}(3602)
├─{python}(3603)
├─{python}(3604)
├─{python}(3605)
├─{python}(3606)
├─{python}(3607)
├─{python}(3608)
├─{python}(3609)
├─{python}(3610)
├─{python}(3611)
├─{python}(3612)
├─{python}(3613)
├─{python}(3614)
├─{python}(3615)
├─{python}(3616)
├─{python}(3617)
├─{python}(3618)
├─{python}(3619)
├─{python}(3620)
├─{python}(3621)
├─{python}(3622)
├─{python}(3623)
├─{python}(3624)
├─{python}(3625)
├─{python}(3626)
├─{python}(3627)
├─{python}(3628)
├─{python}(3629)
├─{python}(3630)
├─{python}(3631)
├─{python}(3632)
├─{python}(3633)
├─{python}(3634)
├─{python}(3635)
├─{python}(3636)
├─{python}(3637)
├─{python}(3638)
├─{python}(3639)
├─{python}(3756)
├─{python}(3757)
├─{python}(3758)
└─{python}(3771)
看到这里也就基本证实了我们的猜想,为了更进一步我们打印出磁盘的读取情况:
命令:
sudo pidstat -d 1



可以看到这四个读取数据的进程每秒一共可以读取5MB数据多些,为了好计算,我们把每秒总共读数据的大小看做5MB,那么一分钟就是读300MB,一小时就是读18GB,那么100多G的数据全部遍历完至少需要六个小时以上。到了这里我们就可以下结论了,在开始训练的6个小时内需要从磁盘读取数据,假设内存空间足够大,这些读进内存的数据会一直保存在缓存中,那么6个小时后训练就可以满速运行,也就是说开始的6小时内即使假设内存足够大(可以保证数据集全部缓存在内存中)也难以得到满速的运行状态。
这里需要说下,服务器真实的内存为500GB,平时运行基本都可以保证有200GB的free空间。
现在的问题已经定位了,那么怎么解决呢,这时候就冒出了这样的一个疑问,那就是linux系统默认的内存cache缓存空间到底有多大呢,如果这个空间足够大那么我们是不是可以把数据集中的数据进行预读从而实现在cache缓存里面进行保存呢。
====================================
linux系统中cache空间的大小是由多个因素所决定的,为此我们可以做一个大致的调查:
查看系统中的最小自由内存空间的设置(free):
命令:
cat /proc/sys/vm/min_free_kbytes
输出:
91896
可以看到,系统默认的最小free空间为91MB,但是这个数据并不一定是触发系统自动清理cache的最低free空间,也就是说有可能有其他因素可以在free空间大于这个数值的时候就触发系统自动清理cache。
根据:http://www.04007.cn/article/159.html 中的描述,我们可以暂时认为系统即使是被触发自动清理cache空间也不会一次性清空所有的cache空间,往往也是尽可能少的清空cache空间。
但是实际使用过程中发现影响cache的最大空间的因素还是不能确定的,在该服务器实际运行过程中发现当内存free空间在2.5GB左右依然没有对cache空间进行释放(在free空间在2.5GB左右的时候依然可以小体量的申请free内存空间),当然为了服务器能够稳定运行我们还是可以手动释放掉一些cache空间的,给出主动释放cache中clean数据空间的python代码:
>>> import numpy as np
>>> y=np.random.randint(0,2,size=(16*(2**30),))
该操作可以主动释放掉128GB的cache中的clean数据空间。
之所以采用这种方式释放clean空间而不是使用命令sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"来释放clean空间,是因为后者会释放掉所有的clean空间,而很多clean空间本身是为运行的进程加速用的,而使用python代码申请一定空间内存,而该内存空间大于free空间时就会触发系统自动清理clean数据的操作,而这种系统的自动清理clean数据的操作并不是一次性清空而是根据需求而适当的清理出相应的空间。
而为什么我们要手动清理一些clean空间呢,首先本文所讲述的背景就是cache中基本都为clean数据,还有一点就是如果cache中的dirty数据达到最高上限后会进行将cache中的所有dirty数据全部一次性的写回到磁盘,而这个对dirty数据的同步操作又往往是同步和阻塞的,因此如果触发系统对dirty数据全部写回磁盘的操作就会造成对这些dirty数据进行读写的进程必然陷入阻塞状态,如果越来越多的进程需要读取和写入这些正在存盘的数据,那么就会造成IO系统响应缓慢,导致越来越多的请求堆积,写回到磁盘的数据被再次读入内存,甚至会造成系统内存全部被占用,然后一部分进程数据被存入到swap中,这又更加加剧了磁盘的存操作的压力,基本就是刚存入磁盘的数据被再次读回内存然后再写回磁盘,这样就会造成CPU基本空转而系统的大部分时间都在做内存和磁盘数据的同步,如果此时导致dirty数据同步到磁盘的时间超过120s(2分钟),就会引起报错现象,由于此时的进程数据很多都被保存在硬盘的swap中,此时的系统就会陷入低效的运行状态,甚至与死机状态相差不大。
既然分析出来此时服务器的瓶颈在于数据读取上,那么我们只要进行数据的预读操作就可以进行提速。
所谓的数据预读就是在深度学习进程开始之前就把数据集中的数据遍历一遍读到内存中,但是不要进行保存和修改,这样这个数据集的内容就会被保存到缓存中。假设内存空间比较大,此时缓存空间中存储的数据集的数据为clean数据,而且由于是存在内核空间,这样只要再次访问这些文件就会直接从内存的cache空间中读取而不是从硬盘上读取,这样就可以成倍数的提高运算效率,不过需要注意这种方式主要是面对超大数据集的情况,并且内存中有足够的空间。
就如刚才分析的,程序以30%的速度(GPU的运算速度,不考虑IO情况下GPU为计算瓶颈)运行6个小时以上才会把数据全部读入,然后才会以100%的速度运行,那么如果这6个小时的时间都是与100%的运算速度进行那么就可以在1.8小时之内运行相同的运算量,这样就可以节省掉4.2个小时的总运算时间,而这里都是比较乐观的计算,这个节省的时间在实际中往往可能是5、6个小时。那么把所有数据读到硬盘的时间是多少呢,磁盘的读写速度不低于300MB每秒,108GB的数据只需要6分钟就可以全部导入到内存的cache中,而这样一个操作以后就可以省掉总运行时长的5个小时,而这就是所谓的“数据预读”加速机器学习训练的方法。
由于数据集是存放在cache空间的,并且为clean数据,因此只要访问硬盘的地址相同,所有用户的所有进程都可以直接高速访问这些cache中的数据,如果是服务器的话多个用户多个训练进程都把数据的硬盘原地址写为相同的地址,那么就可以实现一份cache数据大家一起用的效果了。
如何实现这个“数据预读”呢,给出一个示意代码:
dataset_list=['/home/xxx/dataset/1.png', '/home/xxx/dataset/2.png','/home/xxx/dataset/3.png','/home/xxx/dataset/4.png','/home/xxx/dataset/5.png']
for data in dataset_list:
f=open(data, "r")
content=f.read()
f.close()
上面的这个代码就可以实现遍历,由于我们的目的是把数据都导入到内存的cache中而不是used中,所以只需要遍历即可。
===============================================
由于cache所占空间过大引起的其他问题?
cache空间过大有系统自动清理和手动清理两种方式:
1. 如果cache过大触发系统的自动清理操作,会按照需求进行适当空间大小的清理cache操作,此时的清理cache操作包括对clean数据和dirty数据的清理。
2. 如果选择手动清空cache,则不同于系统清理cache那样适当的清理出来部分空间,而是把几乎全部的cache空间都进行清理操作,具体的手动清空cache操作为:
sudo sync
sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"
需要注意:
linux系统内存的cache空间中数据分为clean和dirty两种,其中dirty数据不能通过sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"操作写回磁盘,这个操作只会把clean数据清空,为此我们需要在之前手动进行sync操作来将cache中的dirty数据变为clean数据(把dirty数据同步到磁盘上,这样就变成clean数据了)。
cache中对clean数据进行清理是不需要存盘操作的,如果是系统自动清理cache空间会直接释放掉clean数据,而把dirty数据存盘变成clean数据后再释放掉,即使是手动清理cache空间也需要手动把dirty数据同步回磁盘变成clean数据后再释放其空间。在整个过程中只有dirty数据同步回磁盘的操作才会涉及到磁盘操作。
关于sync操作可以参考:
https://www.cnblogs.com/YLJ666/p/14994177.html
由于本文是对数据集进行读取从而形成大量占用buffer/cache空间的情况,因此可以把cache空间中的数据大多数看做是clean数据,本文所讲的加速机制本身与dirty数据关系不大,不过以前也对cache中的dirty数据进行一定的分析:
Buffer和Cache的区别:
A buffer is something that has yet to be "written" to disk.
A cache is something that has been "read" from the disk and stored for later use.
在操作系统的buffer/cache空间中我们可以把clean数据看做是cache空间下的数据,而dirty数据看做是buffer空间下的数据。
===============================================