caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model。这个model将图片分为1000类,应该是目前为止最好的图片分类model了。
假设我现在有一些自己的图片想进行分类,但样本量太小,可能只有几百张,而一般深度学习都要求样本量在1万以上,因此训练出来的model精度太低,根本用不上,那怎么办呢?
那就用caffe团队提供给我们的model吧。
因为训练好的model里面存放的就是一些参数,因此我们实际上就是把别人预先训练好的参数,拿来作为我们的初始化参数,而不需要再去随机初始化了。图片的整个训练过程,说白了就是将初始化参数不断更新到最优的参数的一个过程,既然这个过程别人已经帮我们做了,而且比我们做得更好,那为什么不用他们的成果呢?
使用别人训练好的参数,必须有一个前提,那就是必须和别人用同一个network,因为参数是根据network而来的。当然,最后一层,我们是可以修改的,因为我们的数据可能并没有1000类,而只有几类。我们把最后一层的输出类别改一下,然后把层的名称改一下就可以了。最后用别人的参数、修改后的network和我们自己的数据,再进行训练,使得参数适应我们的数据,这样一个过程,通常称之为微调(fine tuning).
既然前两篇文章我们已经讲过使用digits来进行训练和可视化,这样一个神器怎么能不使用呢?因此本文以此工具为例,讲解整个微调训练过程。
一、下载model参数
可以直接在浏览器里输入地址下载,也可以运行脚本文件下载。下载地址为:http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel
文件名称为:bvlc_reference_caffenet.caffemodel,文件大小为230M左右,为了代码的统一,将这个caffemodel文件下载到caffe根目录下的 models/bvlc_reference_caffenet/ 文件夹下面。也可以运行脚本文件进行下载:
# sudo ./scripts/download_model_binary.py models/bvlc_reference_caffenet
二、准备数据
如果有自己的数据最好,如果没有,可以下载我的练习数据:http://pan.baidu.com/s/1MotUe
这些数据共有500张图片,分为大巴车、恐龙、大象、鲜花和马五个类,每个类100张。编号分别以3,4,5,6,7开头,各为一类。我从其中每类选出20张作为测试,其余80张作为训练。因此最终训练图片400张(放在train文件夹内,每个类一个子文件夹),测试图片100张(放在test文件夹内,每个类一个子文件夹)。
将图片下载下来后解压,放在一个文件夹内。比如我在当前用户根目录下创建了一个data文件夹,专门用来存放数据,因此我的训练图片路径为:/home/xxx/data/re/train
打开浏览器,运行digits,如果没有这个工具的,推荐安装,真的是学习caffe的神器。安装及使用可参见我的前两篇文章:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
新建一个classification dataset,设置如下图:
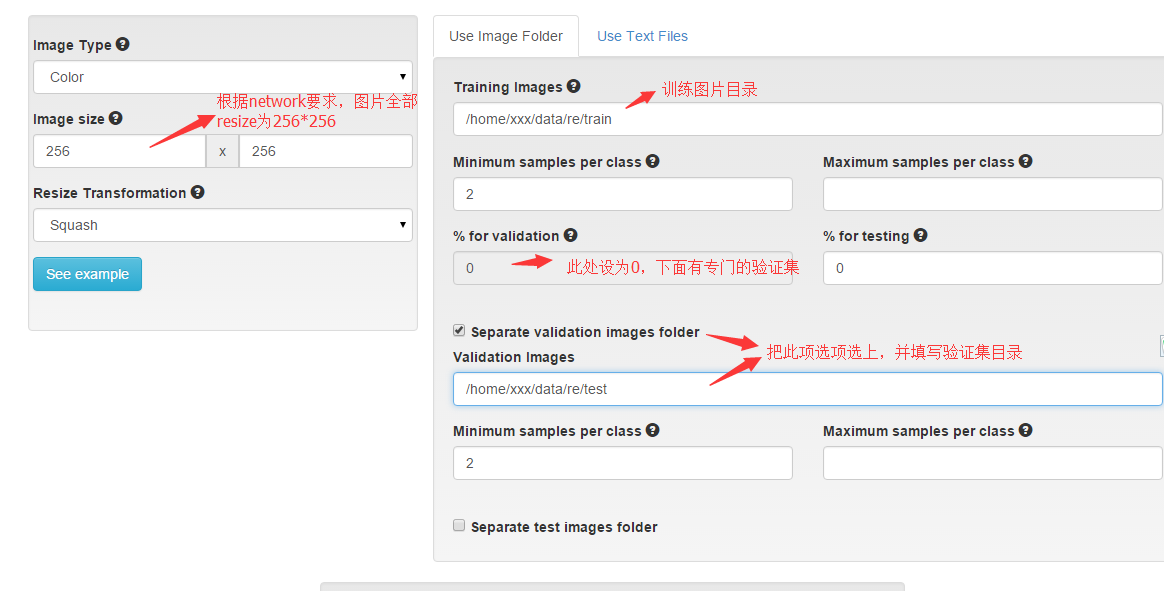
下面图片格式选为jpg, 为dataset取一个名字,就开始转换吧。结果如图:
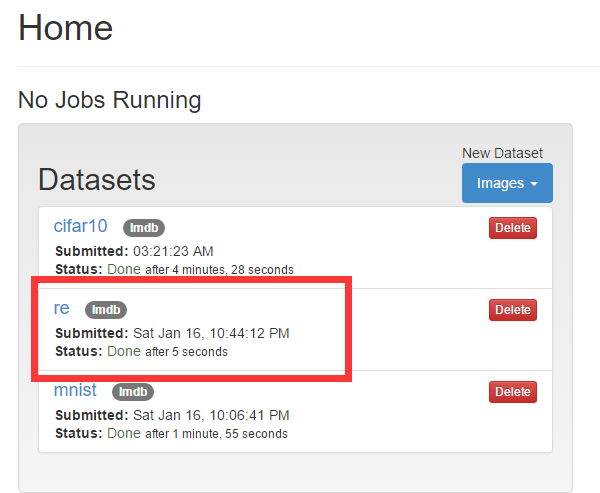
三、设置model
回到digits根目录,新建一个classification model, 选中你的dataset, 开始设置最重要的network.
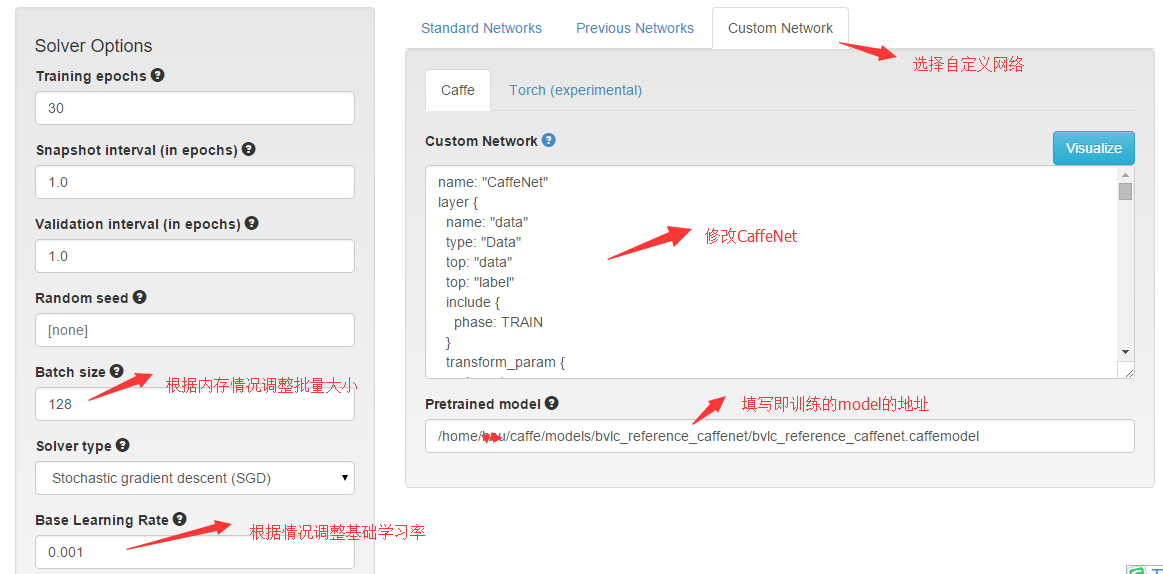
caffenet的网络配置文件,放在 caffe/models/bvlc_reference_caffenet/ 这个文件夹里面,名字叫train_val.prototxt。打开这个文件,将里面的内容复制到上图的Custom Network文本框里,然后进行修改,主要修改这几个地方:
1、修改train阶段的data层为:
layer { name: "data" type: "Data" top: "data" top: "label" include { phase: TRAIN } transform_param { mirror: true crop_size: 227 } }
即把均值文件(mean_file)、数据源文件(source)、批次大小(batch_size)和数据源格式(backend)这四项都删除了。因为这四项系统会根据dataset和页面左边“solver options"的设置自动生成。
2、修改test阶段的data层:
layer { name: "data" type: "Data" top: "data" top: "label" include { phase: TEST } transform_param { mirror: false crop_size: 227 } }
和上面一样,也是删除那些项。
3、修改最后一个全连接层(fc8):
layer { name: "fc8-re" #原来为"fc8" type: "InnerProduct" bottom: "fc7" top: "fc8" param { lr_mult: 1.0 decay_mult: 1.0 } param { lr_mult: 2.0 decay_mult: 0.0 } inner_product_param { num_output: 5 #原来为"1000" weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0.0 } } }
看注释的地方,就只有两个地方修改,其它不变。
设置好后,就可以开始微调了(fine tuning).
训练结果就是一个新的model,可以用来单张图片和多张图片测试。具体测试方法前一篇文章已讲过,在此就不重复了。
在此,将别人训练好的model用到我们自己的图片分类上,整个微调过程就是这样了。如果你不用digits,而直接用命令操作,那就更简单,只需要修改一个train_val.prototxt的配置文件就可以了,其它都是一样的操作。
2016.12.6更新
这篇文章是将近一年前写的,digits版本已经升级,所以有些地方设置有点变化,导致很多网友出现错误。最多的错误提示如下:
ERROR: Layer 'accuracy' references bottom 'label' at the TEST stage however this blob is not included at that stage. Please consider using an include directive to limit the scope of this layer.
我当时用的版本是digits 3.0, 现在大家用的是digits 4.0, 因此会出现这个错误。修改如下:
最后四层的设置:
layer {
name: "re-fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
stage:"val"
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
exclude{
stage:"deploy"
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc8"
top: "prob"
include{
stage:"deploy"
}
}
原来网络结构中的全连接层fc8, 需要改一下名字,如我的改成"re-fc8". 因为我们做的是微调。微调的意思就是先在别的数据集上进行训练,把训练好的权值,作为我们现在数据集的权值初始化,就不再需要随机初始化了。现在的数据和训练时的数据不一致,因此有些层数的设置就会有点区别。比如这个例子中,用来训练模型的数据集是imagenet,分为1000类,而我们的数据集就只有5类,因此在fc8这层上的num_output就会有区别,因此在这一层上就不能用人家的权值了,就需要把这层的名字改得和原来的网络结构不一样。
在digits 4.0版本中,最后的全连接层不再需要num_output这个参数了,因此大家需要把这行删除掉。digits会自动根据你的类别数把这个参数补充上。
也许原来的配置文件中没有Softmax层,现在需要加上这一层,因为digits会根据这里的设置自动生成train_test.prototxt和deploy.prototxt两个文件。其它需要修改的地方,就是最后三层的include和exclude了。
最后还有一个问题就是显存的问题。实话讲我的这个训练数据选得不太好,很吃显存,有些GPU不好的同学,运行起来很吃力。因此大家非要用这个数据的话,建议把batch_size调低些。我用的是nvidia k20, 4G显存,batch_size设置为16—32之间,运行得不错,1分钟左右运行完。