一、数据为什么需要归一化处理?
归一化的目的是处理不同规模和量纲的数据,使其缩放到相同的数据区间和范围,以减少规模、特征、分布差异对模型的影响。
方法:
1. 极差变换法
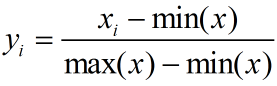
2. 0均值标准化(Z-score方法)
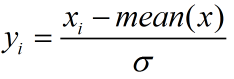
1. Max-Min(线性归一化)
Max-Min归一化是对原始数据进行线性变化,利用取值的最大值和最小值将原始数据转换为某一范围的数据
缺点:归一化过程与最大值和最小值有关,容易受到极端值的影响。会一定程度破坏原有数据的结构
应用:图像处理中,将RGB图像转换为灰度图像后将其值限定在[0, 255]的范围
2. Z-Score标准化
基于原始数据的均值和标准差进行标准化。Z-score是一种中心化方法,会改变原有数据的分布结构,不适合对稀疏数据做处理。本方法要求原始数据的分布近似为高斯分布,否则归一化的效果很差。
应用:在分类和聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-Score标准化表现很好
二、应用场景
1. 概率模型不需要归一化,因为这种模型不关心变量的取值,而是关心变量的分布和变量之间的条件概率。
决策树(概率模型)、随机森林(基学习器是决策树)、朴素贝叶斯(概率模型)不需要归一化
2. SVM、线性回归之类的最优化问题需要归一化。归一化之后加快了梯度下降求最优解的速度,并有可能提高精度。
是否归一化主要在于是否关心变量取值
3. 神经网络需要标准化处理,一般变量的取值在-1到1之间,这样做是弱化某些变量的值较大而对某些产生影响。一般神经网络中的隐藏层采用tanh激活函数比sigmoid要好,因为取值[-1, 1],均值为0(需要)
4. 在k近邻算法中,如果不对解释变量进行标准化,那么具有小数量级的解释变量的影响就会微乎其微(需要)
参考地址: