参考地址:https://blog.csdn.net/leviopku/article/details/82660381
YOLO v3结构图
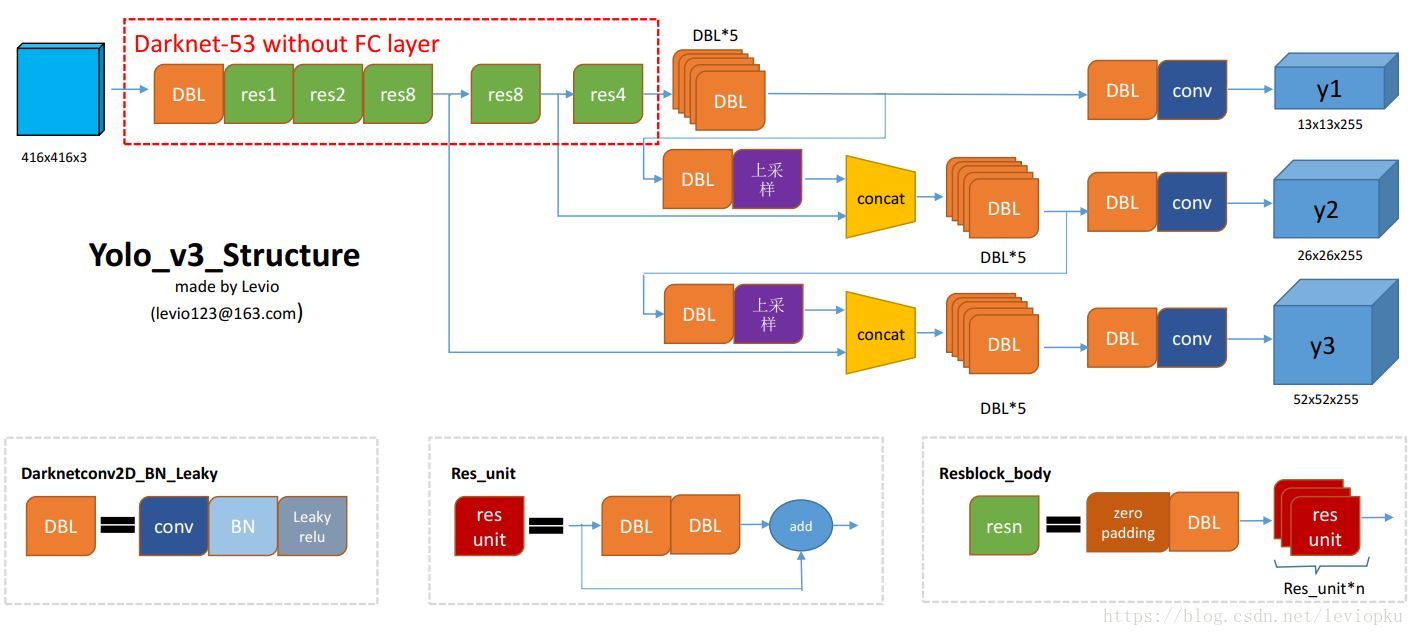
DBL:卷积+BN+leaky relu,是v3的最小组件
resn:n代表数字,有res1,res2,...,res8等,表示这个res_block里含有多少个res_unit。这是YOLO-v3的大组件,YOLO-v3借鉴了ResNet的残差结构,使用这个结构可以让网络更深(从v2的darknet-19上升到darknet-53,前者没有残差结构)。其实resn的基本组件也是DBL
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
可以使用netron来分析网络层,整个YOLO-v3包含252层
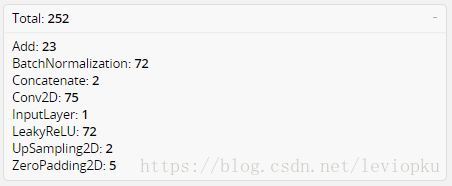
从图中可以看出,一共有252层。包括add层23层(主要用于res_block的构成,每个res_unit需要一个add层,一共有1+2+8+8+4=23层)。除此之外,BN层和LeakyReLU层数量完全一样(72层),在网络结构中表现为:每一层BN后面都会接一层LeakyReLU。卷积层一共有75层,其中72层后面都会接BN+LeakyReLU的组合构成基本组件DBL,还有三个卷积用于最后的输出。一共有5个零填充层,表现为每一个res_block都会用上一个零填充,一共有5个零填充
1. backbone(骨架)
整个v3结构里面,是没有池化层和全连接层的,前向传播中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在YOLO-v2中,要经历5次缩小,将特征图缩小到原输入尺寸的1/32,即输入为416x416,输出为13x13(416/32=13)。
YOLO-v3也和v2一样,backbone都会讲输出特征图缩小到输入的1/32。所以,通常要求输入图片是32的倍数。下图是v2和v3的backbone对比(DarkNet-19与DarkNet-53)

YOLO-v2中对于前两过程中张量尺寸变换,都是通过最大池化来进行,一共有5次,而v3是通过卷积核增大步长来进行,也是5次(darknet-53最后面有一个全局平均池化,在YOLO-v3里面没有这一层,所以张量维度变化只考虑前面那5次)
这也是416x416输入得到13x13输出的原因。从图中可以看出darknet-19不存在残差结构

从上表中也可以看出,darknet-19在速度上任然占据很大优势。其实在其他细节也可以看出(比如bounding box prior采用k=9,而v2中k=5,明显计算复杂度超过v2,随之而来的是速度比v2要慢),YOLO-v3并没有那么追求速度,而是在保证实时性的同时(fps>60)的基础上追求performance。当然,如果想速度更快,可以使用tiny-darknet作为backbone替代darknet-53,在官方里用一行代码就可以切换backbone。使用tiny-darknet的YOLO,也就是tiny-YOLO在轻量和高速两个特点上,显然是最先进的。

所以,有了YOLO v3,就真的用不着YOLO v2,更用不着YOLO v1了,这也是YOLO官方网站(https://pjreddie.com/darknet/),在v3出来以后,就没提供v1和v2代码下载链接的原因
2. Output

YOLO v3输出了3个不同尺度的feature map,如上图所示的y1,y2,y3,这也就是跨尺度预测 (predictions across scales)。这个借鉴了FPN(feature pyramid networks,特征金字塔网络),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体
y1,y2,y3的深度都是255,边长的规律是13:26:52
对于coco类别而言,有80个种类,所以每个box应该对每个种类都输出一个概率。YOLO v3设定的是每个网格单元预测3个box,所以每个box需要有(x,y,w,h,confidence)五个基本参数,然后还要有80个类别的概率。所以3*(5+80)=255。255就是这么来的
3. some tricks
Bounding Box Prediction
先说明一下v2的b-box预测:它借鉴了faster R-CNN RPN中的anchor机制,但不屑于手动设定anchor prior(模板框),于是用维度聚类的方法大来确定anchor box prior,最后选用了k=5。后来,v2又嫌弃anchor机制线性回归的不稳定性(因为回归的offset可以使box偏移到图片的任何地方),所以v2最后采用了自己的方法:直接预测相对位置。预测出b-box中心点相对于网格单元左上角的相对坐标


对于v3而言,选用的b-box priors的k=9,对于tiny-yolo的话,k=6。priors都是在数据集上聚类得来的。每个anchor prior(名字叫anchor prior,但不是用anchor机制)就是两个数字组成的,一个代表高度另一个代表宽度。
v3对b-box进行预测的时候,采用了logistic regression。v3每次对b-box进行预测时,输出和v2一样都是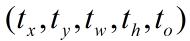 ,通过公式1计算出绝对的
,通过公式1计算出绝对的
(x,y,w,h,c)。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要的anchor,可以减少计算量。
如果模板框不是最佳的,即使它超过我们设定的阈值,我们还是不会对它进行预测,不同于faster R-CNN的是,YOLO v3只会对一个prior进行操作,也就是那个最佳的prior。而logistic回归就是从9个anchor priors中找到目标性评分最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模
4. 损失函数
在YOLO系列中,v1使用了sum-square error的损失计算方法,就是简单的差方相加而已。而在v3中没有明确的提到损失函数。在目标检测任务中,有几个关键信息是需要确定的:
(x,y),(w,h),class,confidence
根据关键信息的特点可以分为上述四类,损失函数应该由各自特点确定。最后加到一起就可以组成最终的loss_function了,也就是一个loss_function就搞定了端到端的训练。可以从代码分析出v3的损失函数,同样是对以上四类,不过相对于v1中简单的总方误差,还是有些调整的:
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2], from_logits=True) wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - raw_pred[..., 2:4]) confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + (1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) * ignore_mask class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[..., 5:], from_logits=True) xy_loss = K.sum(xy_loss) / mf wh_loss = K.sum(wh_loss) / mf confidence_loss = K.sum(confidence_loss) / mf class_loss = K.sum(class_loss) / mf loss += xy_loss + wh_loss + confidence_loss + class_loss
以上是keras框架描述的YOLO v3的loss_function代码。忽略恒定系数不看,可以从上述代码看出:除了w,h的损失函数依然采用总方误差之外,其他部分的损失函数用的是二元交叉熵(binary_crossentropy)。这个一般用作二分类的损失函数。