
作者:Great Learning Team
- 神经网络
- 什么是反向传播?
- 反向传播是如何工作的?
- 损失函数
- 为什么我们需要反向传播?
- 前馈网络
- 反向传播的类型
- 案例研究
在典型的编程中,我们输入数据,执行处理逻辑并接收输出。 如果输出数据可以某种方式影响处理逻辑怎么办? 那就是反向传播算法。 它对以前的模块产生积极影响,以提高准确性和效率。
让我们来深入研究一下。
神经网络(Neural network)
神经网络是连接单元的集合。每个连接都有一个与其相关联的权重。该系统有助于建立基于海量数据集的预测模型。它像人类的神经系统一样工作,有助于理解图像,像人类一样学习,合成语音等等。
什么是反向传播(What is backpropagation?)
我们可以将反向传播算法定义为在已知分类的情况下,为给定的输入模式训练某些给定的前馈神经网络的算法。当示例集的每一段都显示给网络时,网络将查看其对示例输入模式的输出反应。之后,测量输出响应与期望输出与误差值的比较。之后,我们根据测量的误差值调整连接权重。
在深入研究反向传播之前,我们应该知道是谁引入了这个概念以及何时引入。它最早出现在20世纪60年代,30年后由大卫·鲁梅尔哈特、杰弗里·辛顿和罗纳德·威廉姆斯在1986年的著名论文中推广。在这篇论文中,他们谈到了各种神经网络。今天,反向传播做得很好。神经网络训练是通过反向传播实现的。通过这种方法,我们根据前一次运行获得的错误率对神经网络的权值进行微调。正确地采用这种方法可以降低错误率,提高模型的可靠性。利用反向传播训练链式法则的神经网络。简单地说,每次前馈通过网络后,该算法根据权值和偏差进行后向传递,调整模型的参数。典型的监督学习算法试图找到一个将输入数据映射到正确输出的函数。反向传播与多层神经网络一起工作,学习输入到输出映射的内部表示。
反向传播是如何工作的?(How does backpropagation work?)
让我们看看反向传播是如何工作的。它有四层:输入层、隐藏层、隐藏层II和最终输出层。
所以,主要的三层是:
1.输入层
2.隐藏层
3.输出层
每一层都有自己的工作方式和响应的方式,这样我们就可以获得所需的结果并将这些情况与我们的状况相关联。 让我们讨论有助于总结此算法所需的其他细节。
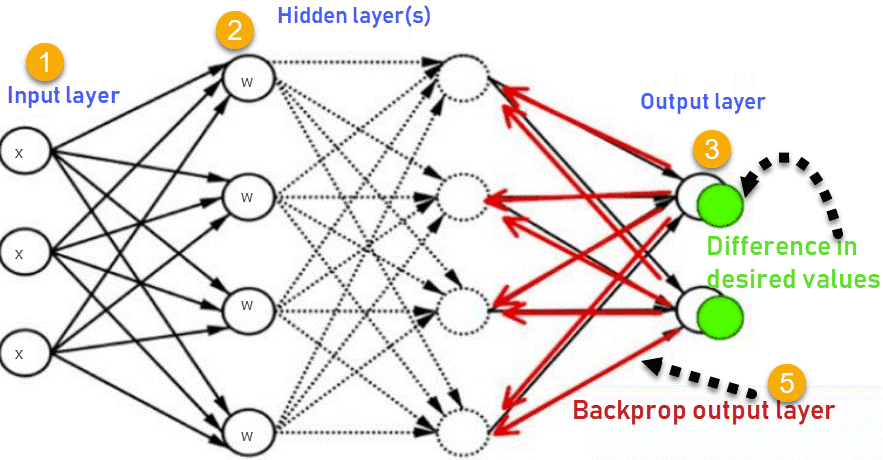
这张图总结了反向传播方法的机能。
1.输入层接收x
2.使用权重w对输入进行建模
3.每个隐藏层计算输出,数据在输出层准备就绪
4.实际输出和期望输出之间的差异称为误差
5.返回隐藏层并调整权重,以便在以后的运行中减少此错误
这个过程一直重复,直到我们得到所需的输出。训练阶段在监督下完成。一旦模型稳定下来,就可以用于生产。
损失函数(Loss function)
一个或多个变量被映射到实数,这些实数表示与这些变量值相关的某个数值。为了进行反向传播,损失函数计算网络输出与其可能输出之间的差值。
为什么我们需要反向传播?(Why do we need backpropagation?)
反向传播有许多优点,下面列出一些重要的优点:
•反向传播快速、简单且易于实现
•没有要调整的参数
•不需要网络的先验知识,因此成为一种灵活的方法
•这种方法在大多数情况下都很有效
•模型不需要学习函数的特性
前馈网络(Feed forward network)
前馈网络也称为MLN,即多层网络。 之所以称为前馈,是因为数据仅在NN(神经网络)中通过输入节点,隐藏层并最终到达输出节点。 它是最简单的人工神经网络。
反向传播的类型(Types of backpropagation)
有两种类型的反向传播网络。
•静态反向传播(Static backpropagation)
•循环反向传播(Recurrent backpropagation)
- 静态反向传播(Static backpropagation)
在这个网络中,静态输入的映射生成静态输出。像光学字符识别这样的静态分类问题将是一个适合于静态反向传播的领域。
- 循环反向传播(Recurrent backpropagation)
反复进行反向传播,直到达到某个阈值为止。 在到达阈值之后,将计算误差并向后传播。
这两种方法的区别在于,静态反向传播与静态映射一样快。
案例研究(Case Study)
让我们使用反向传播进行案例研究。 为此,我们将使用Iris数据(鸢尾花卉数据集),该数据包含诸如萼片和花瓣的长度和宽度之类的特征。 在这些帮助下,我们需要确定植物的种类。
为此,我们将构建一个多层神经网络,并使用sigmoid函数,因为它是一个分类问题。
让我们看一下所需的库和数据。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split为了忽略警告,我们将导入另一个名为warnings的库。
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)接着让我们读取数据。
iris = pd.read_csv("iris.csv")
iris.head()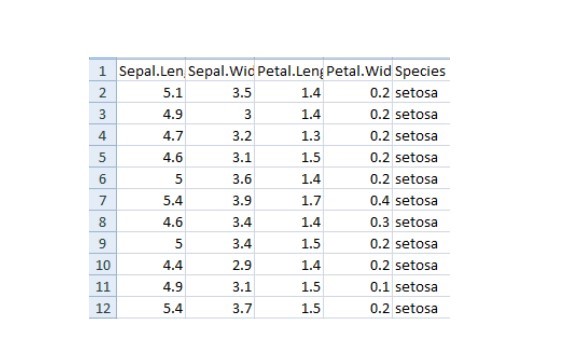
现在我们将把类标记为0、1和2。
iris. replace (, , inplace=True)我们现在将定义函数,它将执行以下操作。
1.对输出执行独热编码(one hot encoding)。
2.执行sigmoid函数
3.标准化特征
对于独热编码,我们定义以下函数。
def to_one_hot(Y):
n_col = np.amax(Y) + 1
binarized = np.zeros((len(Y), n_col))
for i in range(len(Y)):
binarized ] = 1.
return binarized现在我们来定义一个sigmoid函数
def sigmoid_func(x):
return 1/(1+np.exp(-x))
def sigmoid_derivative(x):
return sigmoid_func(x)*(1 – sigmoid_func(x))现在我们将定义一个用于标准化的函数。
def normalize (X, axis=-1, order=2):
l2 = np. atleast_1d (np.linalg.norm(X, order, axis))
l2 = 1
return X / np.expand_dims(l2, axis)现在我们将对特征进行规范化,并对输出应用独热编码。
x = pd.DataFrame(iris, columns=columns)
x = normalize(x.as_matrix())
y = pd.DataFrame(iris, columns=columns)
y = y.as_matrix()
y = y.flatten()
y = to_one_hot(y)现在是时候应用反向传播了。为此,我们需要定义权重和学习率。让我们这么做吧。但在那之前,我们需要把数据分开进行训练和测试。
#Split data to training and validation data(将数据拆分为训练和验证数据)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.33)
#Weights
w0 = 2*np.random.random((4, 5)) - 1 #for input - 4 inputs, 3 outputs
w1 = 2*np.random.random((5, 3)) - 1 #for layer 1 - 5 inputs, 3 outputs
#learning rate
n = 0.1我们将为错误设置一个列表,并通过可视化查看训练中的更改如何减少错误。
errors = []让我们执行前馈和反向传播网络。对于反向传播,我们将使用梯度下降算法。
for i in range (100000):
#Feed forward network
layer0 = X_train
layer1 = sigmoid_func(np.dot(layer0, w0))
layer2 = sigmoid_func(np.dot(layer1, w1))
Back propagation using gradient descent
layer2_error = y_train - layer2
layer2_delta = layer2_error * sigmoid_derivative(layer2)
layer1_error = layer2_delta.dot (w1.T)
layer1_delta = layer1_error * sigmoid_derivative(layer1)
w1 += layer1.T.dot(layer2_delta) * n
w0 += layer0.T.dot(layer1_delta) * n
error = np.mean(np.abs(layer2_error))
errors.append(error)准确率将通过从训练数据中减去误差来收集和显示
accuracy_training = (1 - error) * 100现在让我们直观地看一下如何通过减少误差来提高准确度。(可视化)
plt.plot(errors)
plt.xlabel('Training')
plt.ylabel('Error')
plt.show()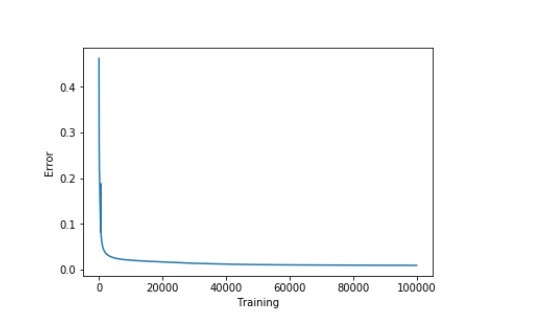
现在让我们查看一下准确率。
print ("Training Accuracy of the model " + str (round(accuracy_training,2)) + "%")Output: Training Accuracy of the model 99.04%
我们的训练模型表现很好。现在让我们看看验证的准确性。
#Validate
layer0 = X_test
layer1 = sigmoid_func(np.dot(layer0, w0))
layer2 = sigmoid_func(np.dot(layer1, w1))
layer2_error = y_test - layer2
error = np.mean(np.abs(layer2_error))
accuracy_validation = (1 - error) * 100
print ("Validation Accuracy of the model "+ str(round(accuracy_validation,2)) + "%")Output: Validation Accuracy 92.86%
这个性能符合预期。
应遵循的最佳实践准则(Best practices to follow)
下面讨论一些获得好模型的方法:
•如果约束非常少,则系统可能不起作用
•过度训练,过多的约束会导致过程缓慢
•只关注少数方面会导致偏见
反向传播的缺点(Disadvantages of backpropagation)
•输入数据是整体性能的关键
•有噪声的数据会导致不准确的结果
•基于矩阵的方法优于小批量方法(mini-batch)
综上所述,神经网络是具有输入和输出机制的连接单元的集合,每个连接都有相关联的权值。反向传播是"误差的反向传播",对训练神经网络很有用。它快速、易于实现且简单。反向传播对于处理语音或图像识别等易出错项目的深度神经网络非常有益。
