awk命令不仅仅是Linux系统的命令,也是一种编程语言,用来处理数据和生成报告(Exel),处理的数据可以是一个或多个文件(标准输入和管道获取标准输入)。可在命令行上编辑操作,也可以写成awk程序运用。
查看awk版本
# awk --version
awk格式
# awk -F “参数” ‘BEGIN{} 模式 {动作} END{}’ 文件路径
参数
-F 指定awk按照什么符号进行文本切割,将原文件内容切割成一列一列,如果不指定-F参数,awk默认按照空格进行文本切割
{} 代表print输出 输出多个值用逗号“,”分隔;{}中双引号里的内容原封不动输出
$ 代表取列
$1 代表第一列,以此类推 $0表示所有内容 $NF表示输出最后一列(最后一组元素)
BEGIN{}:告知awk,数据要如何读取
END{}:告知awk,程序要如何结束
awk指令是由模式、动作,或者模式和动作的组合组成。
awk [awk参数] ‘模式 {动作}’ 文件名
模式:过滤条件
动作:执行
在指定文件中,awk先根据分隔符进行切割,再在模式中过滤所需的数据,再通过动作去执行(无动作时,默认输出全部内容)
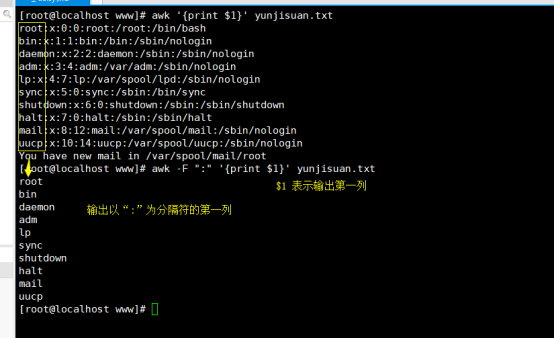
# awk -F “: ” ‘NR==3{print $1}’ yunjisuan.txt
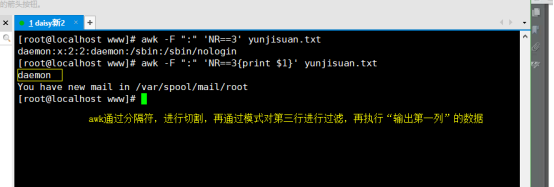
awk执行过程
从BEGIN模块开始,一行一行读数据,看模式,是否符合条件,符合则执行动作;若不符合,则执行下一行。执行到结尾,会执行END模块后输出文本内容
1)awk读入第一行内容
2)判断是否符合模式中的条件NR>=2
a,如果匹配则执行对应的动作{print $0}
b,如果不匹配条件,继续读取下一行
3)继续读取下一行
4)重复过程1-3,直到读取到最后一行(EOF:end of file)
分隔符
通过-F参数指定分隔符,换行符默认
NR这个符号的真正含义不是行号,二十数据被awk读取一段以后,NF就会记录一次。
由于awk默认以 作为每次读取数据的结束标志,NR就恰好等于行号。
awk的换行符
通过BEGIN{},在awk读取数据之前设定它的读入换行符、输出换行符;通常,默认awk的读入换行符和输出换行符为
RS 是输入记录分隔符,决定awk如何读取或分隔每行(记录)
ORS表示输出记录分隔符,决定awk如何输出一行(记录)的,默认是回车换行( )
FS是输入区域分隔符,决定awk读入一行后如何再分为多个区域。
OFS表示输出区域分隔符,决定awk输出每个区域的时候使用什么分隔他们。
awk无比强大,你可以通过RS,FS决定awk如何读取数据。你也可以通过修改ORS,OFS的值指定awk如何输出数据。

更改换行符,用RS,ORS操作
RS=””读入换行符(输入输出数据记录分隔符) ORS=””输出换行符(输出记录分隔符) NR 记录行号
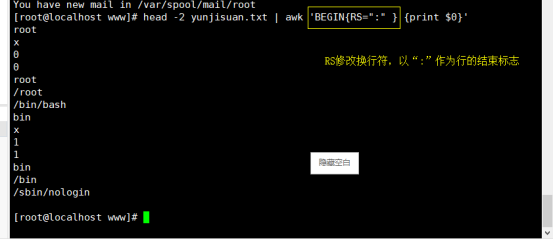
当更改输出换行符时,输出换行符会替换掉读入换行符
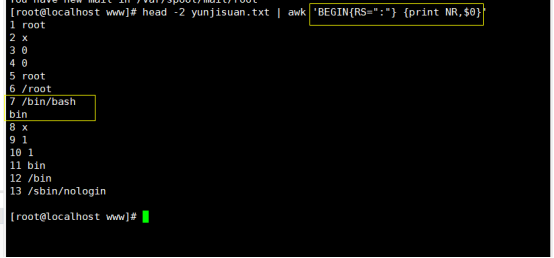
因为设定了读入换行符RS=”:”,因此,在awk的内存里的数据是按照如下排列的:
1 root
2 x
3 0
4 0
5 root
6 /root
7 /bin/bash bin
8 x
9 1
10 1
由于awk默认输出换行符是 ,因此在输出时,awk会在内存行的每行结尾附加输出换行符号 ,因此输出时效果如下:
1 root
2 x
3 0
4 0
5 root
6 /root
7 /bin/bash
Bin
8 x
9 1
10 1
按单词出现频率降序排序(计算文件中每个单词的重复数量)
方法(1)将所有非小写字母和非大写字母替换成空,剩余都是英文单词,再计数并排序
# cat count.txt | xargs -n1 | sort | uniq -c | sort -rn
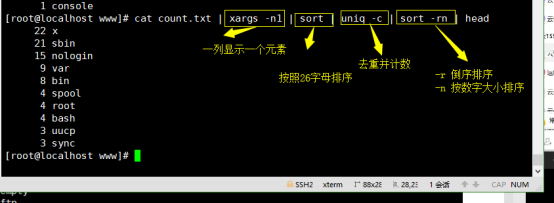
引申:
sort 默认按26个字母排序(默认指定排序为第一列)
sort -n 按照数字大小排序
sort -r 倒序排序
sort -k 数字 从第“数字”列,按大小排序
uniq 相同元素去重
uniq -c 去重并计数
替换tr
# tr “” “”
tr “a-z” “A-Z” 转换大小写
tr “:” ”?” 把:替换成?
方法(2)将文件里面的所有空格替换为回车换行符“ ”
# cat count.txt | tr " " " " | sort | uniq -c | sort -rn
方法(3)grep所有连续的字母,grep -o参数让他们排成一列
# grep -o "[a-zA-Z]+" count.txt | sort | uniq -c | sort
awk的模式分类
(1)正则表达式模式
(2)比较表达式模式
(3)范围模式
(4)特殊模式BEGIN和END
正则表达式模式
显示第9列是200的行的IP地址
# awk ‘$9~/^200$/ {print $1}’ access.log
在第9列模式下,~进行正则匹配操作,以200开头,以200结尾过滤,
打印$1,显示IP地址
# awk ‘$9~/^404$/ {print $1}’ access.log | sort | uniq -c
在上述基础上,排序并去重、计数
或# awk ‘$9==”404” {print $1}’ access.log | sort | uniq -c
awk不支持的正则符号“{}”,需要加--posix或--re-interval实现
x{m}
x{m,}
x{m,n}
~ b表示进行正则匹配
!~ 表示与~相反
表示以第五列匹配正则表达式,过滤含有shutdown的字符串,显示这一行
# awk -F “:” ‘$5~/shutdown/’ yunjisuan.txt
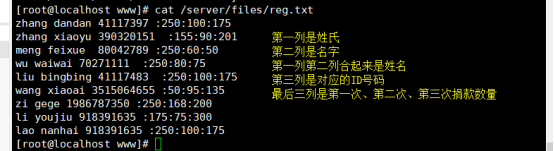
显示姓zhang的人的第二次捐款金额及他的名字
# awk -F “[ :]+” ‘$1~/^zhang/ {print $2,$(NF-1)}’ /server/files/reg.txt

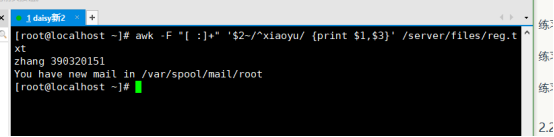
显示xiaoyu的姓氏和ID号码
# awk -F “[ : ]+” ‘$2~/^xiaoyu/ {print $1,3$}’ /server/files/reg.txt
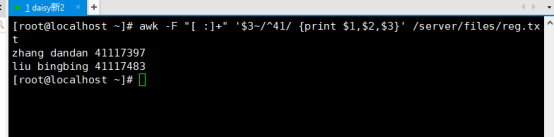
显示所有以41开头的ID号码的人的全名和ID号码
# awk -F “[ :]+” ‘$3~/~41/ {print $1,$2,$3}’ /server/files/reg.txt
显示所有以一个D或X开头的人名全名
# awk -F “[: ]+” ‘$2~/^d|^x/ {print $1,$2}’ /server/files/reg.txt

显示所有ID号码最后一位数字是1或5的人的全名
# awk -F “[ :]+” ‘$3~/1$|5$/ {print $1,$2}’ /server/files/reg.txt
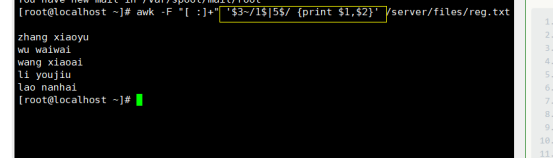
显示xiaoyu的捐款,每个值都有以$开头,如$520$200$135
# awk -F “[ :]+” ‘$2~/xiaoyu/ {print “$”$4”$”$5”$”$6}’ /server/files/reg.txt

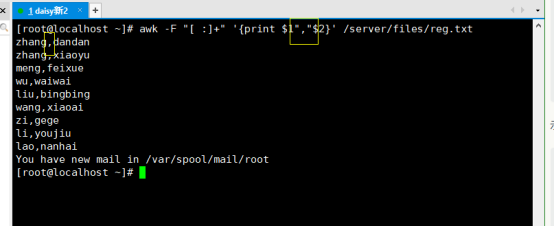
显示所有人的全名,以姓、名的格式显示,如meng,feixue
# awk -F “[ :]+” ‘{print $1”,”$2}’ /server/files/reg.txt
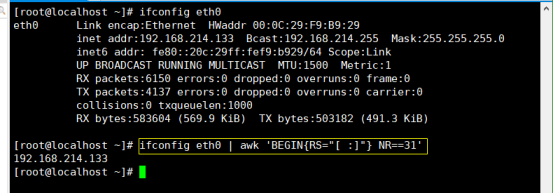
取网卡eth0的IP地址
默认分隔符,第一个字符前面不占位
指定分隔符,第一个字符前面占位
方法一:
# ifconfig eth0 | awk ‘BEGIN{RS=”[ :]”} NR==31’
方法二:
# ifconfig eth0 | awk -F “(addr:)|(Bcast:)” ‘NR==2{print $2}’

方法三:
# ifconfig eth0 | awk -F “[ :]+” ‘NR==2{print $4}’
# ifconfig eth0 | awk -F “[ :]” ‘NR==2{print $13}’

方法四:
# ifconfig eth0 | awk -F “[^0-9.]+” ‘NR==2{print $2}’

比较表达式模式
取出文件/etc/services的23-30行
# awk ‘NR>=23&&NR<=30’ /etc/services
# awk ‘NR>22&&NR<31’ /etc/services
判断某一列是否等于某个字符,找出/etc/passwd中第五列是root的行
# awk -F":" '$5=="root"' /server/files/awk_equal.txt
# awk -F":" '$5~/^root$/' /server/files/awk_equal.txt
找出工资在(40000,60000)之间的员工名字
# awk -F: ‘$3>=”40000” && $3<=”60000” {print $1}’ test2
范围模式
显示第二行到第五行的行好和整行的内容
# awk 'NR==2,NR==5{print NR,$0}' count.txt
显示以bin开头,到第五行的行号及整行内容
# awk '/^bin/,NR==5{print NR,$0}' awkfile.txt
从第三列以bin开始的行到以lp开头的行并显示其行号和整行内容
awk -F":" '$5~/^bin/,/^lp/{print NR,$0}' awkfile.txt
从第三列以bin开头字符串的行到第三列以lp开头字符串的行
# awk -F: '$5~/^bin/,$5~/^lp/{print NR,$0}' awkfile.txt
BEGIN模块
(1)定义内置变量(-F本质式修改的FS变量)
# ifconfig eth0|awk -F "(addr:)|( Bcast:)" 'NR==2{print $2}'
相当于# ifconfig eth0 | awk 'BEGIN{FS="(addr:)|( Bcast:)"} NR==2{print $2}'
# ifconfig eth0 | awk -F "[ :]+" 'NR==2{print $4}'
相当于# ifconfig eth0 | awk 'BEGIN{FS="[ :]+"}NR==2{print $4}'
# ifconfig eth0 | awk -F "[^0-9.]+" 'NR==2{print $2}'
相当于# ifconfig eth0 | awk 'BEGIN{FS="[^0-9.]+"}NR==2{print $2}'
(2)在读取文件之前,输出提示性信息(表头)
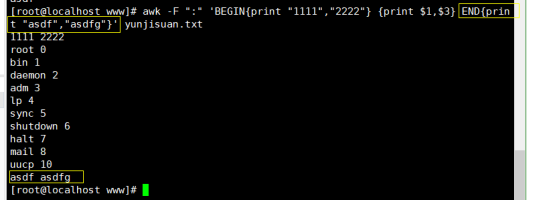
# awk -F ":" 'BEGIN{print "1111","2222"} {print $1,$3} ' yunjisuan.txt
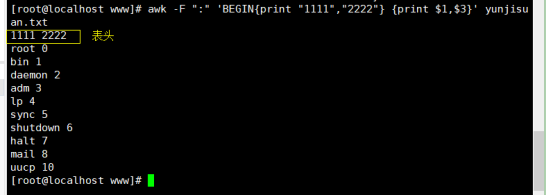
# awk -F ":" 'BEGIN{print "1111","2222"} {print $1,$3} END{print "asdf","asdfg"}' yunjisuan.txt
(3)使用BEGIN 模块的特殊性质,进行一些测试(计算)
计算数值
# awk 'BEGIN{print 10/3}'

赋值变量
# awk 'BEGIN{a=1;b=2;print a,b,a+b}'

awk中字母会被认为是变量,给一个变量赋值字母(字符串),用双引号
# awk 'BEGIN{abcd=123456;a=abcd;print a}'
123456
# awk 'BEGIN{a="abcd";print a}'
abcd
表示a的b次方
# awk ‘BEGIN{a=2;b=3;print a**b}’
查看/etc/services空行个数
方法一:
# grep -c “^$” /etc/services 
方法二:
# awk ‘/^$/ {i=i+1} END{print i}’ /etc/services
其中,i=i+1 等同于i++
查看test文件一共有多少行
# awk ‘{i++}END{print i}’ test

求test文件每行的值之和
# awk ‘{i=i+$0}END{print i}’ test

求 test文件每行的值之积(BEGIN初始变量设定位置)
# awk ‘BEGIN{i=1}{i=i*$1}END{print i}’ test

awk数组
用一个变量表示多组数据,通常优先考虑数组,eg:变量名[数字]=不同的值
awk数组结构
arrayname[string]=value
arrayname为数组名
string为元素名
value为值
循环语句
for(变量1 in 变量2) 表示变量1在变量2 中取值,变量1被变量2循环赋值
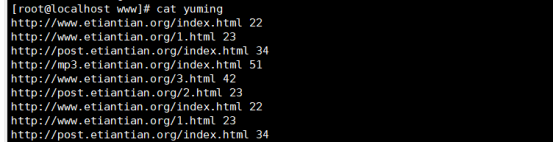
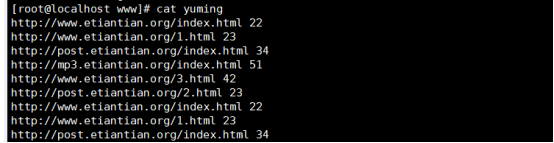
统计域名访问次数
(1)取出域名
(2)将域名去重
(3)统计次数
方法一:
# awk -F “/+” ‘{print $2}’ yuming | sort uniq -c
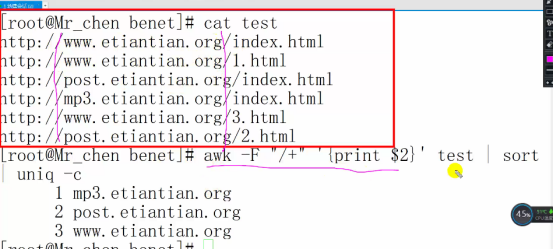
方法二:
# awk -F "[ /]+" '{h[$2]++}END{for(i in h)print i,h[i]}' yuming
统计域名访问次数并累计流量
(1)取出域名
(2)将域名去重
(3)统计流量大小
# awk -F "[ /]+" '{h[$2]=h[$2]+$4}END{for(i in h)print i,h[i]}' yuming

第一列字母去重,并求和
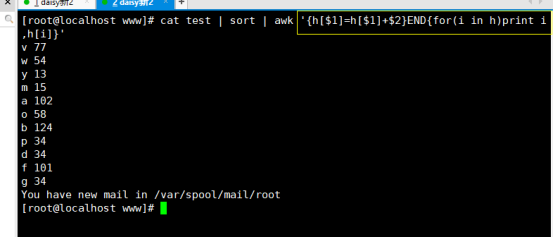
# awk ‘{h[$1]+$2}END{for(i in h)print i,h[i]}’ test
WEB服务器日志文件
access.www.log
(企业应用) 分析图片服务日志,把日志(每个图片访问次数*图片大小的总和)排行,取top10,也就是计算每个url的总访问大小
(在Web服务器日志文件中查看哪个IP地址(用户)浏览本机次数,使用流量最多)
思路:用awk过滤出出现的IP地址,去重IP地址,统计其使用流量,并排序
说明:本题生产环境应用:这个功能可以用于IDC网站流量带宽很高,然后通过分析服务器日志哪些元素占用流量过大,进而进行优化或裁剪该图片,压缩js等措施。
