- 编译器直接支持的数据类型成为基元类型(primitive type)。基元类型直接映射到 Framework类库(FCL)中存在的类型。
1 int a =0;// Most convenient syntax 2 System.Int32 a =0;// Convenient syntax 3 int a =newint();// Inconvenient syntax 4 System.Int32 a =newSystem.Int32();// Most inconvenient syntax
-
上述4行代码都能正确编译,并且生成相同的IL。


-
作者不支持使用 FCL 类型名称,原因如下:
- 开发人员会纠结使用 string 还是 String,string 实际上是直接映射到 System.String 。不知道 int 是指 Int32 还是 Int64。int 映射到 System.Int32,与操作系统无关。
- C# long 映射岛 System.Int64,但在其他编程语言中,long 可能映射到 Int16 或 Int32。(C++/CLI 将long 视为Int32)许多语言不将long 作为关键字。
- FCL 的许多方法都将类型名作为方法名的一部分,如ReadBoolean,ReadInt32,ReadSingle 等。
- 只是用C#的许多程序员忘掉还可以用其他语言写面向CLR的代码。如 Array的 GetLongLength 返回 Int64 的值,在C#中为long,但是在其他语言中(C++/CLI)中却不是。
//第3条示例
//第3条示例1 BinaryReader br =newBinaryReader(...); 2 float val = br.ReadSingle();// OK, but feels unnatural 3 Single val = br.ReadSingle();// OK and feels good
- 不同类型,并且没有继承关系,正常情况下是不能直接转换的。但是 Int32 就可以隐式转换为 Int64。 因为C#编译器非常熟悉基元类型,会在编译代码时应用自己的特殊规则。示例:
1 Int32 i =5;// Implicit cast from Int32 to Int32 2 Int64 l = i;// Implicit cast from Int32 to Int64 3 Single s = i;// Implicit cast from Int32 to Single 4 Byte b =(Byte) i;// Explicit cast from Int32 to Byte 5 Int16 v =(Int16) s;// Explicit cast from Single to Int16
- 只有在类型安全的时候(不会发生数据丢失),C#才允许隐式转换。
- 不同编译器可能生成不同代码来处理转型。如将6.8的 Single 类型转换为 Int32 时,有的编译器可能截断(向下取整),有的则可能转换为7(向上取整)。C# 总是对结果截断(向下取整)
- 基本类型可以被写成字面值(literal),字面值为类型本身的实例。所以可以对其使用实例方法:
Console.WriteLine(123.ToString() + 456.ToString()); // "123456" - 如果表达式由字面值构成,编译器在编译时就能完成表达式的求值。
1 Boolean found =false;// Generated code sets found to 0 2 Int32 x =100+20+3;// Generated code sets x to 123 3 String s ="a "+"bc";// Generated code sets s to "a bc"
checked 和 unchecked 基元类型操作
- 基元类型执行的许多算数运算都可能造成溢出:
1 Byte b =100; 2 b =(Byte)(b +200);
- 执行上述运算时,第一步把操作数扩大为32位(或64位),计算结果,在存回变量 b 之前必须转型为 Byte。
- 不同语言处理移除的方式不同。 C 和 C++ 不将溢出视为操作,允许值回滚(wrap), 而 VB 总是将溢出视为错误。
- CLR 提供了一些特殊的 IL 指令,允许编译器选择它认为最恰当的行为。 CLR 的 加、减、乘、除都提供了相关指令:add/add.ovf,sub/sub.ovf,mul/mul.ovf,conv/conv.ovf。带.ovf表示异常时会抛出 System.OverflowException异常,不带.ovf 则表示不会执行溢出检查。
- C# 默认关闭溢出检查。
- C# 编译器使用 /checked+ 编译开关。开启时生成的代码在执行时会稍微慢一些,因为需要检查计算结果。
- C# 提供 checked 和 unchecked 操作符来控制代码指定区域的溢出检查。
1 Uint32 invalid =unchecked((Uint32)(-1));// OK 2 Byte b =100; 3 b =checked((Byte)(b +200));// OverflowException is thrown 4 b =(Byte)checked(b +200);// b contains 44; no OverflowException
- 最后一个例子, b + 200 首先会转换为32位值, 所以不会被检测为溢出。
- C# 支持checked 和 unchecked 语句,它们语句块内的表达式都进行/不进行溢出检查。
1 checked 2 {// Start of checked block 3 Byte b =100; 4 b +=200;// This expression is checked for overflow. 5 }// End of checked block
- checked 操作符和 checked 语句的唯一作用是决定生成哪个版本的加、减、乘、除和数据转换IL指令,所以在 checked 操作符和语句中调用方法,不会对该方法造成任何影响。
1 checked 2 { 3 // Assume SomeMethod tries to load 400 into a Byte. 4 SomeMethod(400); 5 // SomeMethod might or might not throw an OverflowException. 6 // It would if SomeMethod were compiled with checked instructions. 7 }
- 一些建议:
- 尽量使用有符号数(如 Int32,Int64)而不是无符号数,这允许编译器检测更多的上溢/下溢错误。许多类库(Array 和 String 的Length 属性)被硬编码为返回有符号值,这样可以减少类型转换。无符号数不符合CLS(公共语言规范)。
- 在写代码时,不希望溢出的部分放到 checked 块中,同时捕获 OverflowException,并做相应处理。
- 写代码时,将允许发生溢出的代码显示的放到 unchecked 块中,如计算校验和。
- 对于没有使用 checked 和 unchecked 的代码,都假定希望在溢出时产生异常,视溢出为bug。
- 开发程序时,打开编译开关/checked+,检测异常,在发布时应用编译器的/checked-,可以确保运行效率。
- 如果在效率允许的情况下,开启/checked+,防止数据损坏。
- System.Decimal 被许多语言(如 C# 和 VB)认为是基元类型,但是 CLR 不把它当做基元类型。CLR 没有处理 Decimal 的 IL 指令。编译器会生成代码来调用 Decimal 的成员,并通过这些成员来进行运算,这意味着 Decimal 值的处理速度慢于 CLR 基元类型的值。
- 由于 CLR 没有处理 Decimal 的 IL 指令,所以checked 和 unchecked 对其无效,如果产生溢出,一定会抛出 OverflowException。
补充
- 下列操作受溢出检查的影响:
- 表达式在整型上使用下列预定义运算符:
++ — -(一元) + - * / - 整型间的显式数字转换。
- 表达式在整型上使用下列预定义运算符:
- checked unchecked IL 测试:
1 static void CheckUncheckTest() 2 { 3 byte a = 100; 4 a = (byte)( a + 200 ); 5 6 a = 100; 7 checked 8 { 9 a = (byte)( a + 200 ); 10 } 11 }

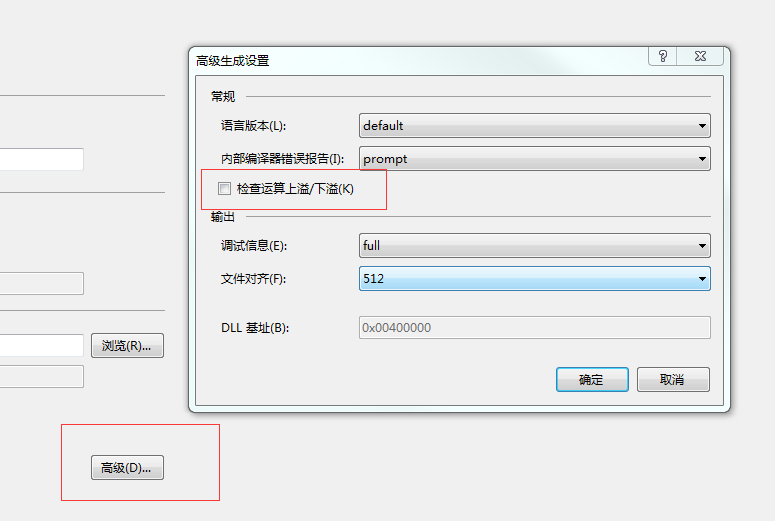
- Vs 对 checked 编译选项开启关闭设置:属性->生成->高级->检查运算上溢/下溢