一、什么是神经网络(吴恩达教授视频笔记)
假设你有一个房子信息的数据集(六个房子的信息),房子信息可能是房屋面积,然后就可以拟合一个根据房屋面积预测房价的函数。
根据我们以前的数学基础,我们可以根据数据集做出一个xy轴的散点图,然后根据线性回归大致拟合出一条直线
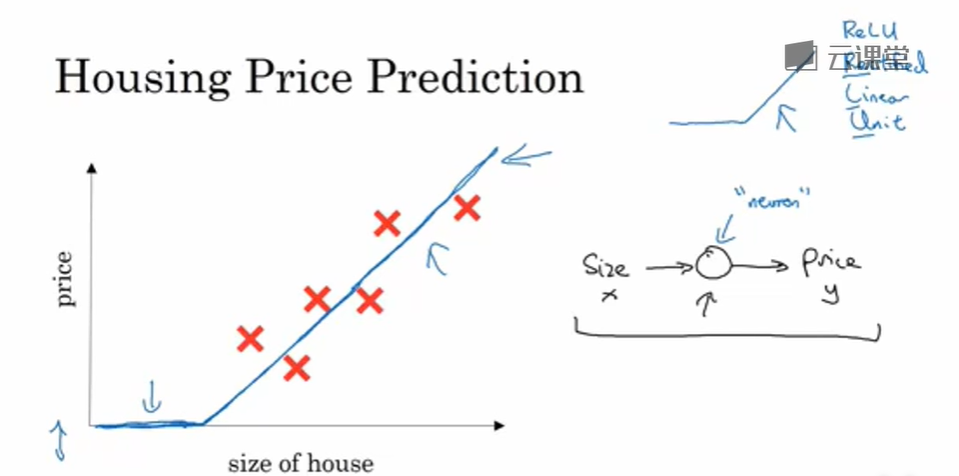
因为价格是不可以为负数的,所以拟合的直线到了与x轴相交时的部分变为水平,最终蓝线为我们要求的房间函数
作为一个神经网络,这几乎可能是最简单的神经网络。我们把房屋的面积作为神经网络的输入(我们称之为x xx),通过一个节点(一个小圆圈),最终输出了价格(我们用y yy表示)。其实这个小圆圈就是一个单独的神经元。接着你的网络实现了左边这个函数的功能。
让我们来看一个例子,我们不仅仅用房屋的面积来预测它的价格,现在你有了一些有关房屋的其它特征,比如卧室的数量,或许有一个很重要的因素,一家人的数量也会影响房屋价格,这个房屋能住下一家人或者是四五个人的家庭吗?而这确实是基于房屋大小,以及真正决定一栋房子是否能适合你们家庭人数的卧室数。
换个话题,你可能知道邮政编码或许能作为一个特征,告诉你步行化程度。比如这附近是不是高度步行化,你是否能步行去杂货店或者是学校,以及你是否需要驾驶汽车。有些人喜欢居住在以步行为主的区域,另外根据邮政编码还和富裕程度相关(在美国是这样的)。但在其它国家也可能体现出附近学校的水平有多好。
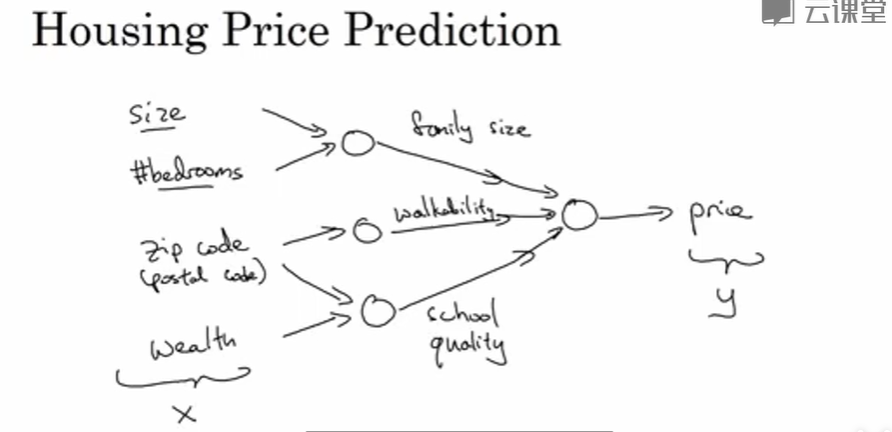
在图上每一个画的小圆圈都可以是ReLU的一部分,也就是指修正线性单元,或者其它稍微非线性的函数。基于房屋面积和卧室数量,可以估算家庭人口,基于邮编,可以估测步行化程度或者学校的质量。最后你可能会这样想,这些决定人们乐意花费多少钱。
对于一个房子来说,这些都是与它息息相关的事情。在这个情景里,家庭人口、步行化程度以及学校的质量都能帮助你预测房屋的价格。以此为例,x xx 是所有的这四个输入,y yy 是你尝试预测的价格,把这些单个的神经元叠加在一起,我们就有了一个稍微大一点的神经网络。这显示了神经网络的神奇之处,虽然我已经描述了一个神经网络,它可以需要你得到房屋面积、步行化程度和学校的质量,或者其它影响价格的因素。
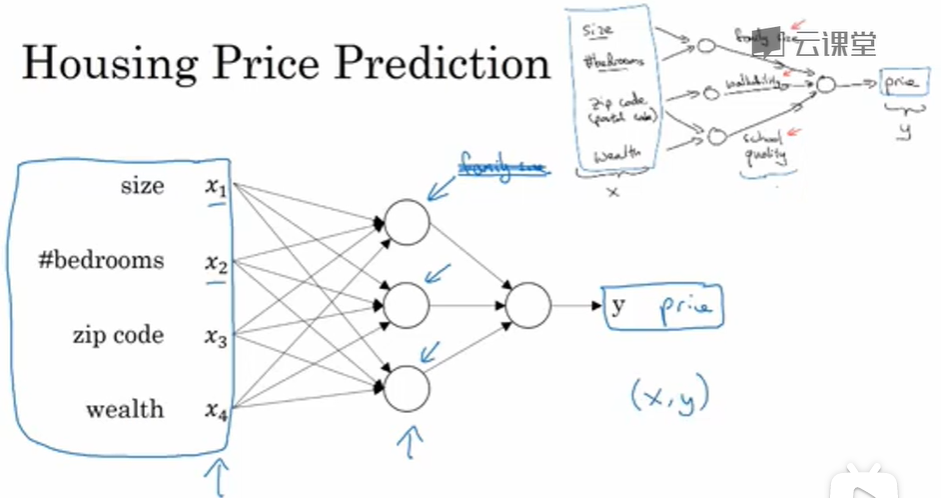
神经网络的一部分神奇之处在于,当你实现它之后,你要做的只是输入 x xx,就能得到输出 y yy。因为它可以自己计算你训练集中样本的数目以及所有的中间过程。所以,你实际上要做的就是:这里有四个输入的神经网络,这输入的特征可能是房屋的大小、卧室的数量、邮政编码和区域的富裕程度。给出这些输入的特征之后,神经网络的工作就是预测对应的价格。同时也注意到这些被叫做隐藏单元圆圈,在一个神经网络中,它们每个都从输入的四个特征获得自身输入,比如说,第一个结点代表家庭人口,而家庭人口仅仅取决于 x 1 x_1x1 和 x 2 x_2x2 特征,换句话说,在神经网络中,你决定在这个结点中想要得到什么,然后用所有的四个输入来计算想要得到的。因此,我们说输入层和中间层被紧密的连接起来了。
值得注意的是神经网络给予了足够多的关于 x xx 和 y yy 的数据,给予了足够的训练样本有关 x xx 和 y yy 。神经网络非常擅长计算从 x xx 到 y yy 的精准映射函数。
这就是一个基础的神经网络。你可能发现你自己的神经网络在监督学习的环境下是如此的有效和强大,也就是说你只要尝试输入一个 x xx ,即可把它映射成 y yy ,就好像我们在刚才房价预测的例子中看到的效果。
二、用神经网络进行监督学习
在监督学习中你有一些输入x,你想学习到一个函数来映射到一些输出 y,比如我们之前提到的房价预测的例子,你只要输入有关房屋的一些特征,试着去输出或者估计价格 y 。我们举一些其它的例子,来说明神经网络已经被高效应用到其它地方。
1、根据房屋的特征输出预测的房价
2、在线广告——根据一些用户信息和广告的信息预测你是否会去点击这个广告
3、计算机视觉——可以输入一个图像,然后想输出一个索引
4、语音识别——音频片段输入神经网络,然后让它输出文本记录
5、机器翻译——利用神经网络输入英语句子,接着输出一个中文句子
6、自动驾驶——可以训练一个神经网络,来告诉汽车在马路上面具体的位置

也许对于房地产和在线广告来说可能是相对的标准一些的神经网络,正如我们之前见到的。对于图像应用,我们经常在神经网络上使用卷积(Convolutional Neural Network),通常缩写为CNN。对于序列数据,例如音频,有一个时间组件,随着时间的推移,音频被播放出来,所以音频是最自然的表现。作为一维时间序列(两种英文说法one-dimensional time series / temporal sequence).对于序列数据,经常使用RNN,一种递归神经网络(Recurrent Neural Network),语言,英语和汉语字母表或单词都是逐个出现的,所以语言也是最自然的序列数据,因此更复杂的RNNs版本经常用于这些应用
1、标准的神经网络SNN
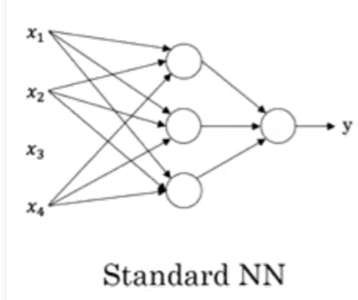
2、卷积神经网络CNN
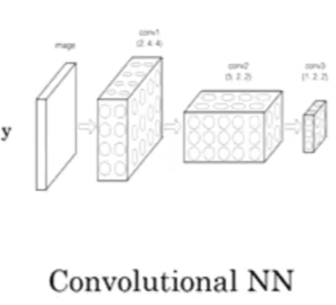
3、卷积神经网络RNN
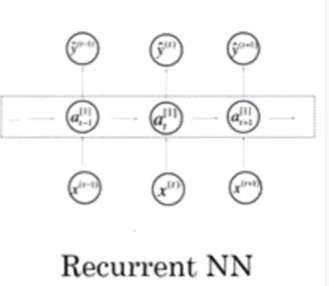
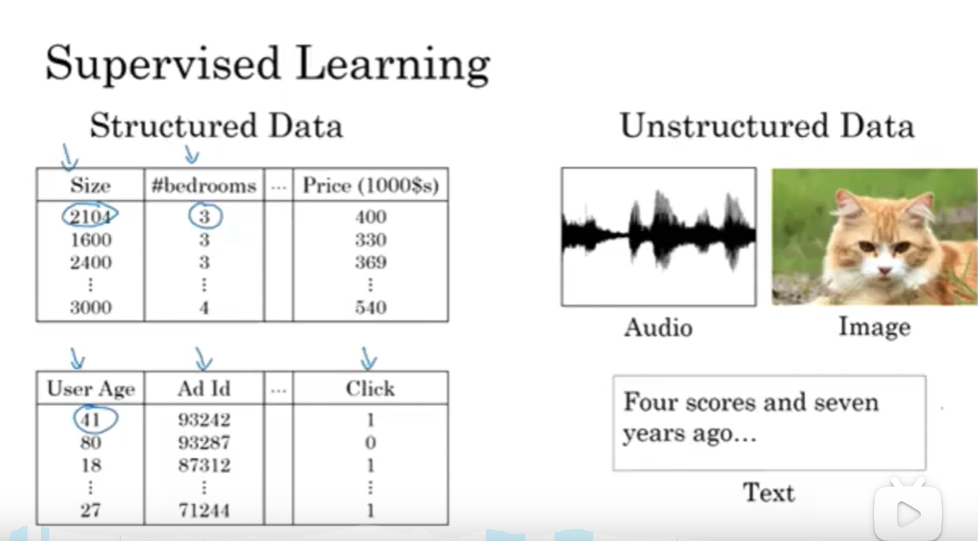
你可能也听说过机器学习对于结构化数据和非结构化数据的应用,结构化数据意味着数据的基本数据库。例如在房价预测中,你可能有一个数据库,有专门的几列数据告诉你卧室的大小和数量,这就是结构化数据。或预测用户是否会点击广告,你可能会得到关于用户的信息,比如年龄以及关于广告的一些信息,然后对你的预测分类标注,这就是结构化数据,意思是每个特征,比如说房屋大小卧室数量,或者是一个用户的年龄,都有一个很好的定义。
相反非结构化数据是指比如音频,原始音频或者你想要识别的图像或文本中的内容。这里的特征可能是图像中的像素值或文本中的单个单词。
三、深度学习为什么会兴起
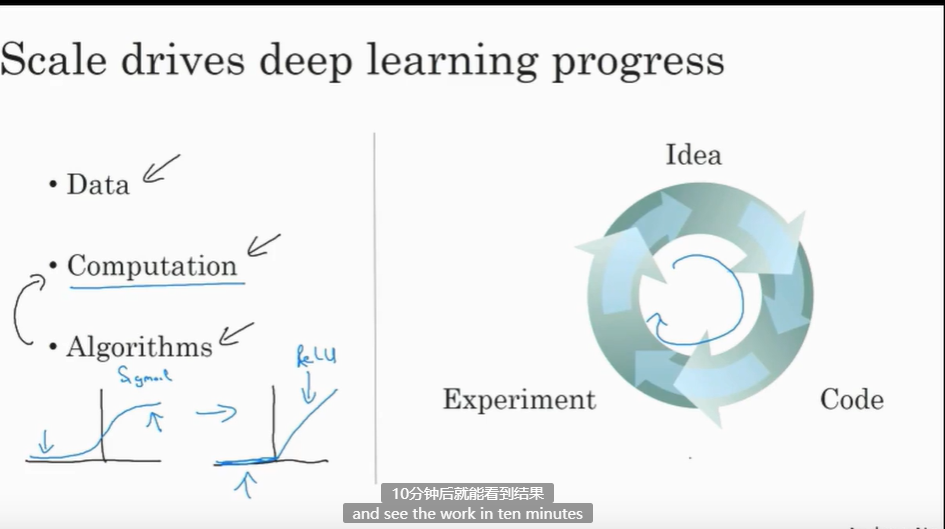
深度学习和神经网络之前的基础技术理念已经存在大概几十年了,为什么它们现在才突然流行起来呢?本节课程主要讲述一些使得深度学习变得如此热门的主要驱动因素,这将会帮助你在你的组织机构内发现最好的时机来应用这些东西。
在过去的几年里,很多人都问我为什么深度学习能够如此有效。当我回答这个问题时,我通常给他们画个图,在水平轴上画一个形状,在此绘制出所有任务的数据量,而在垂直轴上,画出机器学习算法的性能。比如说准确率体现在垃圾邮件过滤或者广告点击预测,或者是神经网络在自动驾驶汽车时判断位置的准确性,根据图像可以发现,如果你把一个传统机器学习算法的性能画出来,作为数据量的一个函数,你可能得到一个弯曲的线,就像图中这样,它的性能一开始在增加更多数据时会上升,但是一段变化后它的性能就会像一个高原一样。假设你的水平轴拉的很长很长,它们不知道如何处理规模巨大的数据,而过去十年的社会里,我们遇到的很多问题只有相对较少的数据量。

多亏数字化社会的来临,现在的数据量都非常巨大,我们花了很多时间活动在这些数字的领域,比如在电脑网站上、在手机软件上以及其它数字化的服务,它们都能创建数据,同时便宜的相机被配置到移动电话,还有加速仪及各类各样的传感器,同时在物联网领域我们也收集到了越来越多的数据。仅仅在过去的20年里对于很多应用,我们便收集到了大量的数据,远超过机器学习算法能够高效发挥它们优势的规模。
神经网络展现出的是,如果你训练一个小型的神经网络,那么这个性能可能会像下图黄色曲线表示那样;如果你训练一个稍微大一点的神经网络,比如说一个中等规模的神经网络(下图蓝色曲线),它在某些数据上面的性能也会更好一些;如果你训练一个非常大的神经网络,它就会变成下图绿色曲线那样,并且保持变得越来越好。因此可以注意到两点:如果你想要获得较高的性能体现,那么你有两个条件要完成,第一个是你需要训练一个规模足够大的神经网络,以发挥数据规模量巨大的优点,另外你需要能画到 x xx 轴的这个位置,所以你需要很多的数据。因此我们经常说规模一直在推动深度学习的进步,这里的规模指的也同时是神经网络的规模,我们需要一个带有许多隐藏单元的神经网络,也有许多的参数及关联性,就如同需要大规模的数据一样。事实上如今最可靠的方法来在神经网络上获得更好的性能,往往就是要么训练一个更大的神经网络,要么投入更多的数据,这只能在一定程度上起作用,因为最终你耗尽了数据,或者最终你的网络是如此大规模导致将要用太久的时间去训练,但是仅仅提升规模的的确确地让我们在深度学习的世界中摸索了很多时间。为了使这个图更加从技术上讲更精确一点,我在 x xx 轴下面已经写明的数据量,这儿加上一个标签(label)量,通过添加这个标签量,也就是指在训练样本时,我们同时输入 x xx 和标签 y yy ,接下来引入一点符号,使用小写的字母 m mm 表示训练集的规模,或者说训练样本的数量,这个小写字母 m mm 就横轴结合其他一些细节到这个图像中。
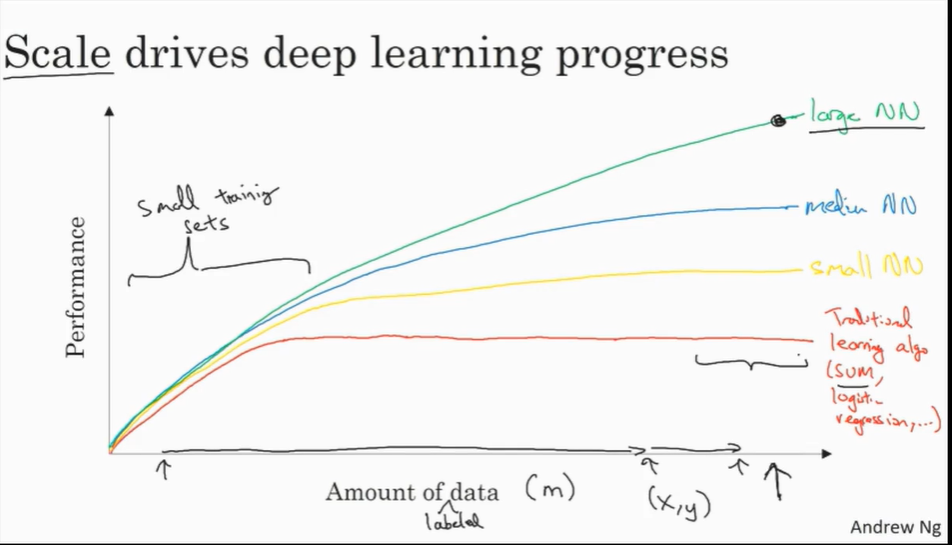
在这个小的训练集中,各种算法的优先级事实上定义的也不是很明确,所以如果你没有大量的训练集,那效果会取决于你的特征工程能力,那将决定最终的性能。假设有些人训练出了一个SVM(支持向量机)表现的更接近正确特征,然而有些人训练的规模大一些,可能在这个小的训练集中SVM算法可以做的更好。因此你知道在这个图形区域的左边,各种算法之间的优先级并不是定义的很明确,最终的性能更多的是取决于你在用工程选择特征方面的能力以及算法处理方面的一些细节,只是在某些大数据规模非常庞大的训练集,也就是在右边这个 m mm 会非常的大时,我们能更加持续地看到更大的由神经网络控制的其它方法,因此如果你的任何某个朋友问你为什么神经网络这么流行,我会鼓励你也替他们画这样一个图形。
所以可以这么说,在深度学习萌芽的初期,数据的规模以及计算量,局限在我们对于训练一个特别大的神经网络的能力,无论是在CPU还是GPU上面,那都使得我们取得了巨大的进步。但是渐渐地,尤其是在最近这几年,我们也见证了算法方面的极大创新。许多算法方面的创新,一直是在尝试着使得神经网络运行的更快。
作为一个具体的例子,神经网络方面的一个巨大突破是从sigmoid函数转换到一个ReLU函数,这个函数我们在之前的课程里提到过。
如果你无法理解刚才我说的某个细节,也不需要担心,可以知道的一个使用sigmoid函数和机器学习问题是,在这个区域,也就是这个sigmoid函数的梯度会接近零,所以学习的速度会变得非常缓慢,因为当你实现梯度下降以及梯度接近零的时候,参数会更新的很慢,所以学习的速率也会变的很慢,而通过改变这个被叫做激活函数的东西,神经网络换用这一个函数,叫做ReLU的函数(修正线性单元),ReLU它的梯度对于所有输入的负值都是零,因此梯度更加不会趋向逐渐减少到零。而这里的梯度,这条线的斜率在这左边是零,仅仅通过将Sigmod函数转换成ReLU函数,便能够使得一个叫做梯度下降(gradient descent)的算法运行的更快,这就是一个或许相对比较简单的算法创新的例子。但是根本上算法创新所带来的影响,实际上是对计算带来的优化,所以有很多像这样的例子,我们通过改变算法,使得代码运行的更快,这也使得我们能够训练规模更大的神经网络,或者是多端口的网络。即使我们从所有的数据中拥有了大规模的神经网络,快速计算显得更加重要的另一个原因是,训练你的神经网络的过程,很多时候是凭借直觉的,往往你对神经网络架构有了一个想法,于是你尝试写代码实现你的想法,然后让你运行一个试验环境来告诉你,你的神经网络效果有多好,通过参考这个结果再返回去修改你的神经网络里面的一些细节,然后你不断的重复上面的操作,当你的神经网络需要很长时间去训练,需要很长时间重复这一循环,在这里就有很大的区别,根据你的生产效率去构建更高效的神经网络。当你能够有一个想法,试一试,看效果如何。在10分钟内,或者也许要花上一整天,如果你训练你的神经网络用了一个月的时间,有时候发生这样的事情,也是值得的,因为你很快得到了一个结果。在10分钟内或者一天内,你应该尝试更多的想法,那极有可能使得你的神经网络在你的应用方面工作的更好、更快的计算,在提高速度方面真的有帮助,那样你就能更快地得到你的实验结果。这也同时帮助了神经网络的实验人员和有关项目的研究人员在深度学习的工作中迭代的更快,也能够更快的改进你的想法,所有这些都使得整个深度学习的研究社群变的如此繁荣,包括令人难以置信地发明新的算法和取得不间断的进步,这些都是开拓者在做的事情,这些力量使得深度学习不断壮大。