第六次作业——结对编程第二次
结对情况
自己
- 532
- 智慧
队友 - 327
- 帅珍
- 队友博客链接:http://www.cnblogs.com/llsz/p/7674003.html
使用语言:C/C++
[github作业地址](https://github.com/llsz/Stu_Depart
)
设计说明
接口设计(API)
内部实现设计(类图)
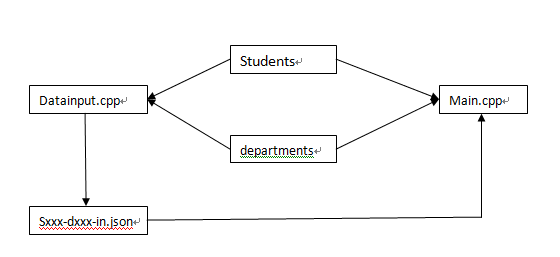
匹配算法设计(思想/流程等)
关于算法的原则,最基础的是基于绩点、兴趣、活动时间几点。而单纯的基于其中某点很容易造成结果匹配失衡。因此在经过初步讨论后,我们决定采用兴趣与活动时间相结合的方法。但在进一步讨论后,我们认为学生的部门志愿个数同样对匹配结果有很大影响:志愿少的选择也少,若要使未被部门选中的学生越少越好,那么志愿个数也是个重要参考项。所以最后总结出匹配算法原则为:
首先设定一优先级T,在部门与学生的匹配过程中,活动时间吻合一条T+4;兴趣标签吻合一条T+2;而部门志愿个数1~5依次对应优先级+5~1;除此之外,我们还考虑到了部门的受欢迎度,将部门按热度排序,热度高的部门优先选择学生。
测试数据如何生成?
在数据生成这一方面,我们选择了手动定义了标签、时间等的随机库数组
- all_tag[20]={"film","ps","ae"···},
- sche_time[6] = { "8:00-10:00","10:00-12:00","14:00-16:00","16:00-18:00","18:00-20:00","20:00-22:00" };
然后通过rand()函数随机确定部门学生标签及其个数[1,5],时间段及其个数[1,3]。此外学生的部门志愿同样随机选择其个数[1,5]。
学生
-学号
-兴趣标签
-标签在标签数组中位置
-时间
-时间标签数组中位置
-部门志愿
-部门部门数组中位置
部门
-部门编号
-限选人数
-兴趣标签
-标签在标签数组中位置
-时间
-时间标签数组中位置
如何评价自己的匹配算法?
关键代码解释
代码规范
函数定义采用驼峰法;缩进规定为四个空格。
关键代码
//统计个部门的意向人数
for(i=0; i<d_count; i++)
{
for(int j=0; j<s_count; j++)
{
for(int k=0; k<5; k++){
if(stu[j].de_app_num[k] == (i+1))
{
worker[i].follow_num++;
}
}
}
}
//对热门/冷门部门排序
for(i=0; i<d_count; i++){
for(int j=i+1; j<d_count; j++)
{
if(worker[i].follow_num < worker[j].follow_num)
{
Departments temp = worker[i];
worker[i] = worker[j];
worker[j] = temp;
}
}
}
//进行匹配
int pp[50][1000][2] = {{{0}}};
for(i=0; i<d_count; i++)
{
for(int j=0; j<s_count; j++)
{
for(int k=0; k<5; k++)
{
if(stu[j].de_app_num[k] == (i+1))
{
for(int m=0; m<5; m++)
{
for(int n=0; n<5; n++)
{
if(worker[i].tags_num[m] == stu[j].tags_num[n])
{
pp[i][j][0] = pp[i][j][0] + 2;
}
}
}
for(int m=0; m<3; m++)
{
for(int n=0; n<3; n++)
{
if(worker[i].sched_num[m] == stu[j].sched_num[n])
{
pp[i][j][0] = pp[i][j][0] + 3;
}
}
}
}
}
}
}
//进行筛选
for(i=0; i<d_count; i++)
{
int j = 0;
for(int k=0; k<s_count; k++)
{
if(pp[i][k][1] != 1 && pp[i][k][0] > 0 )
{
int t = k;
for(int m=k+1; m<s_count; m++)
{
if(pp[i][m][1] != 1 && pp[i][k][0] > 0 )
{
if(pp[i][k][0] < pp[i][m][0])
{
t = m;
}
}
}
pp[i][t][1] = 1;
j++;
}
if(j == worker[i].member_limit)
{
break;
}
}
cout<<endl;
}
//统计适配分数
for(i=0; i<d_count; i++)
{
for(int j=0; j<s_count; j++)
{
cout<<pp[i][j][0]<<":"<<pp[i][j][1]<<" // ";
}
cout<<endl;
}
遇到的困难及解决方法
代码实现时关于部门与学生标签及时间匹配上曾产生过问题:匹配时最暴力的方法就是直接双重循环,但这样就显得十分麻烦。而随机生成的标签及时间可能的重复增加了无用功。在一番讨论后我们决定另外定义数组用于记录随机生成的标签等在随机库中的位置信息,并作为部门、学生信息的一部分输入程序。这样在部门筛选学生时,而这分别持有一标签随机库的位置信息,分别定义数组以0/1表示而这是否有此标签,这样只需要一次循环便可匹配部门学生信息。而且避开了重复标签带来的影响。
有何收获
通过这次作业让我很清楚的体会到了合作的好处。在面对问题时两个人一起讨论使得思考更加全面,分析问题也更加透彻。而且两人在对问题不同看法的思考讨论中,能找到不少新的思路。再者由于代码有两人合作,所以在规范上也必须有意识的配合,个人觉得对养成良好的编码习惯有很大帮助。
对队友的评价
我觉得队友很棒啊。她会比较自觉、也比较可靠,我就比较懒散了,我要向她学习。两个人一起可以互帮互助,就学生和部门如何匹配的问题一起讨论程序的思路和实现,都获益良多。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 90 |
| · Design Spec | · 生成设计文档 | ||
| · Design Review | · 设计复审 (和同事审核设计文档) | ||
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 10 |
| · Design | · 具体设计 | 45 | 60 |
| · Coding | · 具体编码 | 240 | 240 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 50 | 60 |
| · Test Report | · 测试报告 | ||
| · Size Measurement | · 计算工作量 | ||
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | ||
| 合计 | 465 | 545 |