冒泡排序
每两个相邻的元素进行比较,前者大于后者则交换元素位置,直到所有的相邻元素均无法交换位置步骤
步骤
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
python代码:
lst = [43,56,53,33,1,23] def mpsort(ln): lenth = len(ln) while lenth: for i in range(lenth - 1): if ln[i] > ln[i + 1]: ln[i], ln[i + 1] = ln[i + 1], ln[i] lenth -= 1 return ln print mpsort(lst)
冒泡排序是稳定的排序,时间复杂度最好的为O(n) 最差的情况为O(n^2)
直接插入排序
介绍:
插入排序的工作原理是,对于每个未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
步骤:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果被扫描的元素(已排序)大于新元素,将该元素后移一位
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
排序演示:
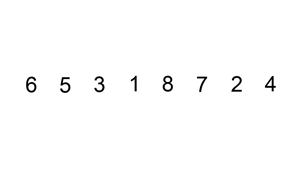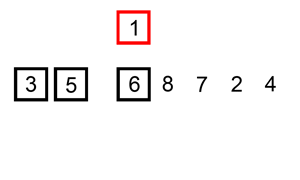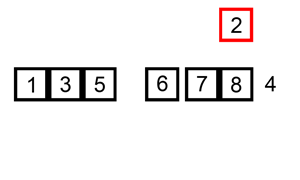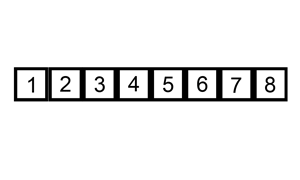
python代码:
lst = [1, 2, 4, 3, 1, 10] def insert_sort(ary): n = len(ary) for i in range(1,n): if ary[i] < ary[i-1]: temp = ary[i] index = i #待插入的下标 for j in range(i-1,-1,-1): #从i-1 循环到 0 (包括0) if ary[j] > temp : ary[j+1] = ary[j] index = j #记录待插入下标 else : break ary[index] = temp return ary print insert_sort(lst)