在数据量大的时候,需要使用文件参数化。
excel文件是其中一种。
-
安装xlrd读取excel文件。(这里是在pycharm安装)
发现选择豆瓣安装失败,阿里云安装成功。
-
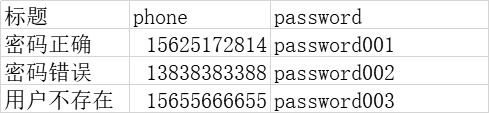
准备excel文件,放在test_data目录下

字典数据
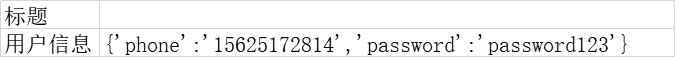
-
在common目录下定义函数
import xlrd
def get_excel_row(row): #row为第几行
excel=xlrd.open_workbook('../test_data/usermessage.xlsx') #使用相对路径,不要使用绝对路径
table=excel.sheets()[0] #读取第一页数据
return table.cell_value(row,1),table.cell_value(row,2) #读取传入行的第二列和第三列数据
def get_row(): #获取文件的总的函数
excel=xlrd.open_workbook('../test_data/usermessage.xlsx') #使用相对路径,不要使用绝对路径
table=excel.sheets()[0] #读取第一页数据
return table.nrows
def get_dict(row):
excel=xlrd.open_workbook('../test_data/dictmessage.xlsx') #使用相对路径,不要使用绝对路径
table=excel.sheets()[0] #读取第一页数据
return table.cell_value(row,1)
- 在testcase目录下进行测试
以登录幕布为例,url='https://mubu.com/login/password',请求方法get,请求为data参数(phone,password)
import requests
from common.get_excel import * #导入自定义的函数
url='https://mubu.com/login/password'
def test_get_excel_row(): #注意:测试用例与定义的的函数在同一
for i in range(1,get_row()): #调用get_row()获取文件的总的函数,循环访问
phone,password=get_excel_row(i)
params={'phone':phone,'password':password}
r=requests.get(url=url,params=params)
print(r.status_code)
print(r.text)
# 读取excel里的字典数据,如{'phone':15625172814,'password':'password123'}
def test_dict():
params=get_dict(1)
print(type(params)) #直接获取是str类型
print(get_dict(1))
r=requests.get(url=url,params=eval(get_dict(1)))
print(r.status_code)
print(r.text)