贝叶斯分类首先准备好数据材料

第一次获取20newsgroups时会花费数分钟时间来获取数据,通过获得target_names可以查看其中的类型。
为了进行分类,采用词袋模型的方法,即统计每篇新闻的单词,不考虑单词间的联系,仅仅考虑它们出现的频率。

11314代表有11314篇文章,130107意思为词典中一共有130107个单词,这11314篇文章中所有的单词都来自于此。
我们可以获得列表中每个对象(文章),并通过一些属性获得我们想要的信息

接下来进行贝叶斯分类,这里采用MultinomialNB
模型训练完成后对照测试集检查效果

对于这个模型的改进,可以有以下几种方法
1.词频反转,不过看起来不太明显

2.去除停用词
一下子提高3个百分点

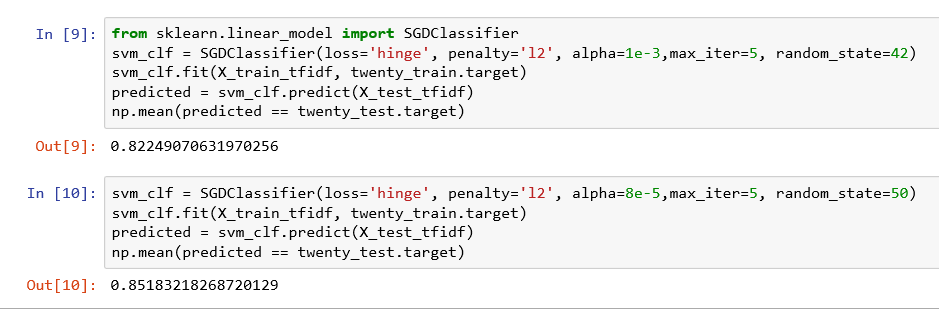
最后是支持向量机
可以通过修改参数进行调整模型,参考http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html