打开一个网站会发生什么?
1.URL解析
域名解析为IP
编码
对于一个完整的网址(URL),通常包括传输协议、域名、端口、路径、参数、哈希值等六个部分。比如对于 http://www.baidu.com/index.html?name=mo&age=25#dowell,它可以进行如下划分:

2.DNS查询
查询浏览器是否有缓存
查询操作系统是否有缓存
查询路由器是否有缓存
3.TCP连接
应用层:发送HTTP请求
传输层:传输报文,http 是基于 tcp 协议,需要进行三次握手。其实传输层还有一个协议UDP协议。
三次握手类似打电话:
客户端:向服务端拨打电话,说:你好,我要跟你谈论事情
服务端:好啊,那可以开始了
客户端:开始说事情
TCP重传
tcp 的三次握手确保了每一个消息都有去有回。一旦某个消息得不到有效回应 tcp 协议就会重发该消息,直到得到有效回应。
去重
网络层:将数据打包,寻找传输路线
链路层:发送数据
建立连接之后,浏览器开始向服务器发送 request 请求,请求数据包。请求信息包含一个头部和一个请求体。请求体告诉了服务器想要的资源是什么。
在 request 请求中,它大致包含以下信息:
GET / HTTP/1.1
Host: google.com
Accept:*/*
Pragma: no-cache
Cache-Control: no-cache
User-Agent:Mozilla/4.04[en](Win95;I;Nav)
GET / 指从服务器上请求一个资源,这个资源的位置是 /。另外,Host: google.com 代表请求的主机名是 google.com。
4.服务器处理
建立连接后,就可以互相传送数据了。客户端按照 http 协议的格式将数据组装好向服务器发起请求,服务器接收到请求并将处理结果响应给浏览器。
服务端的 http 服务器软件一般有 Apache 和 Nginx,Apache 或 Nginx 又将请求交由具体的编程语言(Java、Python、PHP 等)去处理。
服务器又将程序处理的结果按照 http 协议格式原路返回给客户端。这就是服务器响应,响应分为两个部分:响应头和响应主体。其中网页的代码包含在响应主体中。
一个 Response 大致包含以下内容:
HTTP/1.0200OK
Date:Mon,31Dec200104:25:57GMT
Server:Apache/1.3.14(Unix)
Content-type:text/html
Last-modified:Tue,17Apr200106:46:28GMT
Etag:"a030f020ac7c01:1e9f"
Content-length:39725426
Content-range:bytes554554-40279979/40279980
断开连接
在完成了数据通信之后,就要考虑断开连接了,毕竟任务完成了就要空出系统资源来。tcp 的断开相对于连接来说,其实是有四次握手的,通常被称作四次挥手,就是挥手拜拜了。
5.浏览器接收
浏览器根据状态码做不同的事情,
解压缩
存缓存
解析
6.页面渲染
浏览器将域名通过网络通信从服务器拿到html文件后:
1.根据html文件构建DOM树和CSSOM树。构建DOM树期间,如果遇到JS,阻塞DOM树及CSSOM树的构建,优先加载JS文件,加载完毕,再继续构建DOM树及CSSOM树。
2.构建渲染树(Render Tree)。
3.页面的重绘(repaint)与重排(reflow,也有称回流)。页面渲染完成后,若JS操作了DOM节点,根据JS对DOM操作动作的大小,浏览器对页面进行重绘或是重排。
参考:https://www.cnblogs.com/chenyoumei/p/9156849.html
浏览器收到 Response 后,首先对其进行加载,并根据其中的代码继续向服务器请求资源(css、javascript、img 等),加载完成后对页面进行解析。
解析的过程,其实就是生成解析树,即Dom树。Dom树是由Dom元素及属性节点组成,加上css解析的样式对象和js解析后的动作实现。
接下来对Dom树进行可视化表示,也就是渲染,生成一颗渲染树。
最后一步就是绘制网页,浏览器根据渲染树将元素绘制到屏幕上,同时执行js,完成整个页面的展示。
OSI七层模型和TCP五层模型
OSI七层模型从上到下依次为:
应用层:为应用程序提供网络服务;
表示层:数据格式转换、数据压缩和数据加密;
会话层:建立、断开和维护通信链接;
传输层:为上层协议提供端到端的可靠传输;
网络层:寻址和路由;
数据链路层:定义通过通信媒介互连的设备之间传输的规范;
物理层:利用物理传输介质为数据链路层提供物理连接。
TCP五层模型相比OSI七层模型,将OSI的应用层、表示层和会话层合为一层:应用层,其他不变。
什么是面向有连接型和面向无连接型?
面向有连接型传输包括会话建立、传输数据和会话断开,此外还包括保证传输可靠性的各种措施,比如超时重传、流量控制等,常见的面向有连接传输有TCP;
面向无连接型传输仅提供基本的传输数据的功能,即使接收端不存在,发送端也能发送数据包,常见的面向无连接传输有UDP、IP。
UDP和TCP的区别是什么?
UDP和TCP都是传输层的协议,用来建立可靠的通信传输链接的。
UDP仅提供了最基本的数据传输功能,至于传输时连接的建立和断开、传输可靠性的保证这些UDP统统不关心,而是把这些问题抛给了UDP上层的应用层程序去处理,自己仅提供传输层协议的最基本功能。
TCP作为一种面向有连接的协议,只有在确认通信对端存在时才会发送数据,会在传输开始前建立连接,传输结束后断开连接,此外,TCP还采取了多种措施保障传输的可靠性。
TCP和UDP的区别如下:
TCP是面向有连接型,UDP是面向无连接型;
TCP是一对一传输,UDP支持一对一、一对多、多对一和多对多的交互通信;
TCP是面向字节流的,即把应用层传来的报文看成字节流,将字节流拆分成大小不等的数据块,并添加TCP首部;UDP是面向报文的,对应用层传下来的报文不拆分也不合并,仅添加UDP首部;
TCP支持传输可靠性的多种措施,包括保证包的传输顺序、重发机制、流量控制和拥塞控制;UDP仅提供最基本的数据传输能力。
TCP对应的应用层协议有哪些?UDP对应的应用层协议有哪些?
TCP对应的典型的应用层协议:
FTP:文件传输协议;
SSH:远程登录协议;
HTTP:web服务器传输超文本到本地浏览器的超文本传输协议。
UDP对应的典型的应用层协议:
DNS:域名解析协议;
TFTP:简单文件传输协议;
SNMP:简单网络管理协议。
什么是http协议?http和https的区别?
http协议是应用层的协议,中文名称是超文本传输协议,是客户端和服务端相互通信时将信息以http报文的形式传输。
https可以简单的理解为:https = http + 加密 + 认证 + 完整性保护。
http协议的缺点:
通信使用明文,内容可能被窃听。
通信双方的身份无法得到认证,身份可能遭遇伪装。
无法验证报文的完整性。
针对以上问题,https的改进措施:
加密。https协议通过SSL或者TLS协议将报文内容进行加密,client端进行加密,server端进行解密。
认证。通过值得信赖的第三方机构颁布证书,即可确认通信双方的身份。客户端持有证书即可完成客户端身份的确认,客户端通信前会查看服务端的证书。
完整性保护。可以通过MD5等散列码进行通信内容的校验。
为什么说http协议是无状态协议?怎么解决Http协议无状态协议?
http协议是一种无状态协议,协议自身不对请求和响应之间的通信状态进行保存,即对发送过来的请求和响应都不做持久化处理,把http协议设计的如此简单是为了更快地处理大量事务。
为了解决http协议不能保存通信状态的问题,引入了Cookie状态管理。Cookie技术通过在请求和响应报文中写入Cookie信息来控制客户端的状态。Cookie会根据从服务端发送的响应报文的一个叫Set-Cookie的首部字段,通知客户端保存Cookie。当下次客户端再往该服务端发送请求时,客户端会自动在请求报文中加入Cookie值发送出去,服务端发现客户端发来的Cookie后,会检查是哪一个客户端发来的连接请求,对比服务器上的记录,最后得到之前的状态信息。
URI和URL的区别?
URI: Uniform Resource Identifier,统一资源标识符,用来唯一标识互联网中的一份资源。
URL: Uniform Resource Locator,统一资源定位符,我们访问网站的网址就是URL。
URL是URI的子集。
URI的目的就是唯一标识互联网中的一份资源,具体可以用资源名称、资源地址等,但是资源地址是目前使用最广泛的,因此URL就容易和URI混淆。URI相当于抽象类,URL就是这个抽象类的具体实现类。
常见的http动词有哪些?
GET: 从服务器获取资源
POST: 在服务器新建资源
PUT: 在服务器更新资源
DELETE: 在服务器删除资源
HEAD: 获取资源的元数据
OPTIONAL: 查询对指定的资源支持的方法
常见的http返回码有哪些?
200:请求被正常处理
204:请求被受理但没有资源可以返回
206:客户端只是请求资源的一部分,服务器只对请求的部分资源执行GET方法,相应报文中通过Content-Range指定范围的资源。
301:永久性重定向
302:临时重定向
303:与302状态码有相似功能,只是它希望客户端在请求一个URI的时候,能通过GET方法重定向到另一个URI上
304:发送附带条件的请求时,条件不满足时返回,与重定向无关
307:临时重定向,与302类似,只是强制要求使用POST方法
400:请求报文语法有误,服务器无法识别
401:请求需要认证
403:请求的对应资源禁止被访问
404:服务器无法找到对应资源
500:服务器内部错误
503:服务器正忙
get和post有什么区别?
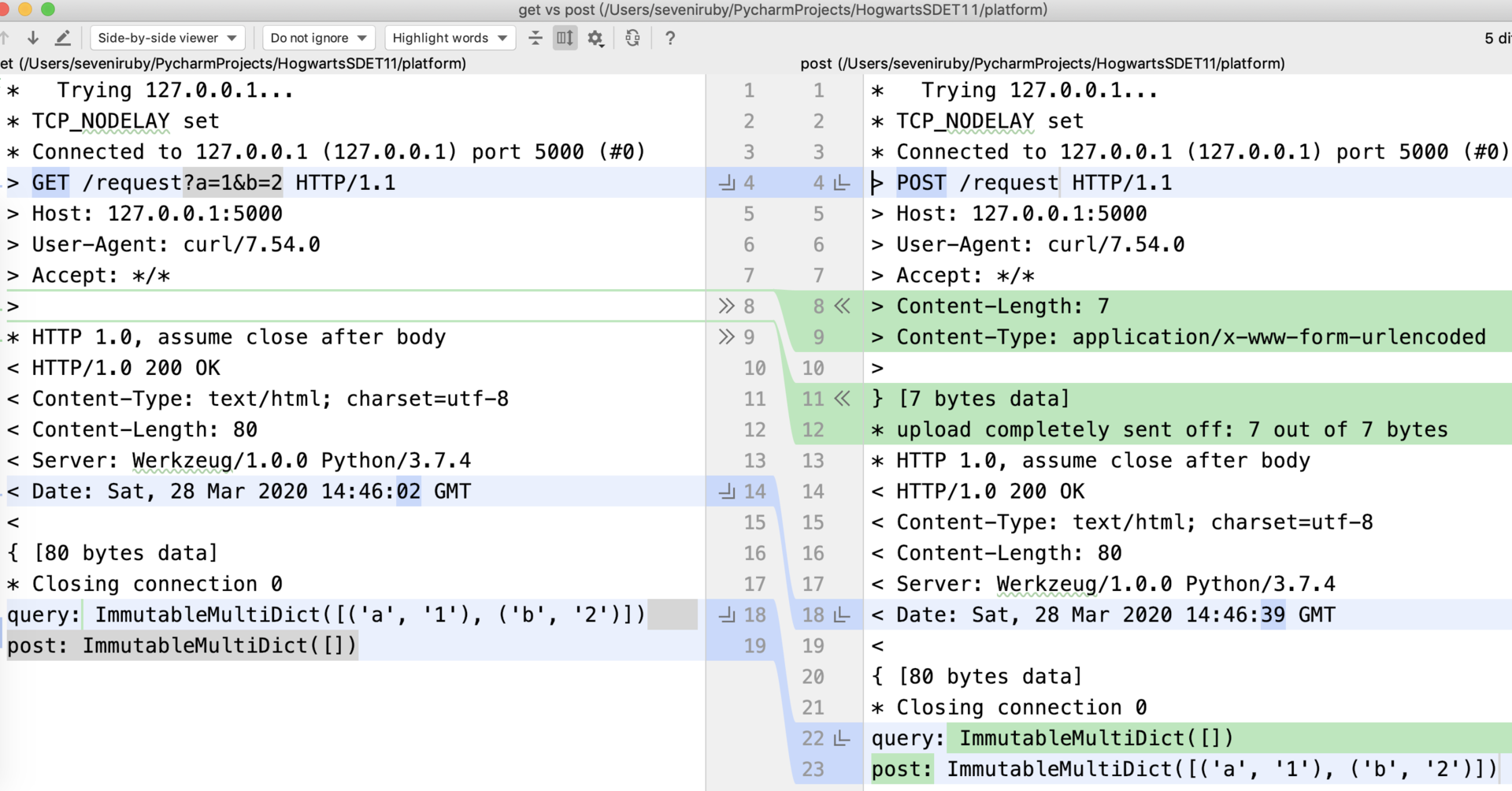
❖ http的method字段不同,一个是get,一个是post
❖ post可以附加body,可以⽀持form、json、xml、binary等各种数据格式
❖ ⾏业通⽤的规范
❖ ⽆状态变化的建议使⽤get请求
❖ 数据的写⼊与状态修改建议⽤post
cookie、session的区别
❖ cookie:浏览器接受服务器的Set-Cookie指令,并把cookie保存到电脑上,每
个⽹站保存的cookie只作⽤于⾃⼰的⽹站
❖ session:数据存储到服务端,只把关联数据的⼀个加密串放到cookie中标记
token、session的区别
❖ token是⼀个⽤户请求时附带的请求字段,⽤于验证⾝份与权限
❖ session可以基于cookie,也可以基于query参数,⽤于关联⽤户相关数据
❖ 跨端应⽤的时候,⽐如android原⽣系统不⽀持cookie
❖ 需要⽤token识别⽤户
❖ 需要⽤把sessionid保存到http请求中的header或者query字段中