论文地址:https://arxiv.org/abs/1905.08160
作者 : Joost Bastings, Wilker Aziz, Ivan Titov
机构:University of Amsterdam
研究的问题:
同样是关注神经网络可解释性的一篇论文,主要是分类任务中的可解释性。主要方法是使用联合训练的两个神经网络,一个网络从文本中提取基本原理,另一个网络学习从基本原理中做出预测。基本原理就是对原文简明扼要的陈述。
研究方法:
Kumaraswamy分布:模型的关键在于Kumaraswamy分布,它是在(0,1)区间上一个两个参数的分布,使用 表示,其中a,b>0。其图像如下:
表示,其中a,b>0。其图像如下:
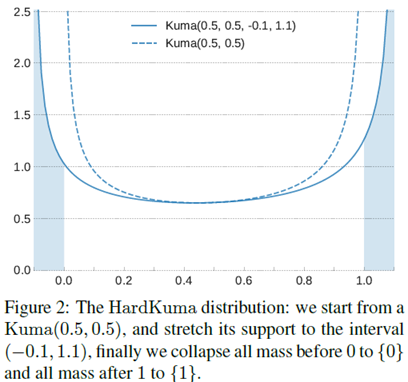
上图中的虚线表示的是Kuma(0.5,0.5)的分布,它和beta分布比较接近。其公式如下:
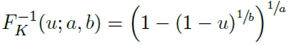
当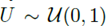 时,
时,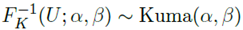
作者这里对Kumaraswamy分布做了扩展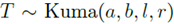 ,让它包括0和1.定义如下:
,让它包括0和1.定义如下:
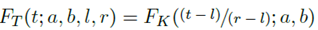
其中l<0,r>1
过程描述如下,首先在(0,1)之间采样得到一个数字,通过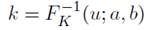 转化为一个Kumaraswamy变量,之后通过线性变化
转化为一个Kumaraswamy变量,之后通过线性变化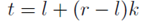 ,最后在[0,1]这个闭区间内得到结果,简记为
,最后在[0,1]这个闭区间内得到结果,简记为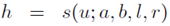 。
。
可以注意到,当t=1和t=1时,它是不可微的。不过对于两个点,被采样到的概率是0.
示例:情感分析
下面以情感分析任务为例来介绍,设x是一个句子,y是五类情感标签。模型包括:
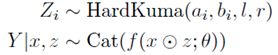
其中的形状参数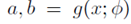 是由神经网络预测得到的。
是由神经网络预测得到的。
首先指定一个架构来参数化潜在的selector,决定限制输入的哪些部分用于分类。
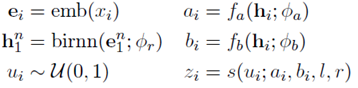
其中,emb表示embedding层,birnn是encoder。
之后使用采样的z来调整分类器的输入。
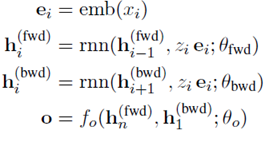
然后,通过蒙特卡洛采样得到梯度的估计:

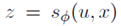 表示逐元素的从均分布到Kuma分布的转换。
表示逐元素的从均分布到Kuma分布的转换。
实验结果:

评价:
主要方法可以概括为,提出了一种提取基本原理的方法,为了重参数化梯度估计、支持二元输出,引入了Kuma分布。