先说结论:没经过仔细调参,打不开论文所说代码链接(fq也没打开),结果和普通卷积网络比较没有优势。反倒是BN对网络起着非常重要的作用,达到了99.17%的测试精度(训练轮数还没到过拟合)。
论文为《Training Very Deep Networks》,一说其在resnet前发表,resnet模仿了它。
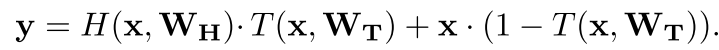
如上式,对于每个输入,都用一个layer去计算T(sigmoid激活),初始设置T的偏置为负,这样使得激活值开始比较小,便于信息流通。
以下对此做了2个测试,一个将图片Flatten后训练,一个使用卷积层。
1,Flatten
from keras.models import Model,Input from keras.datasets import mnist from keras.layers import Dense,Multiply,Add,Layer,Conv2D,Subtract,Lambda,Flatten,MaxPooling2D,BatchNormalization,Activation from keras.losses import categorical_crossentropy from keras import optimizers from keras.utils import to_categorical from keras import initializers import keras.backend as K
(x_train,y_train),(x_test,y_test)=mnist.load_data() X_train=x_train.reshape(60000,-1)/255. X_test=x_test.reshape(10000,-1)/255. y_train=to_categorical(y_train,num_classes=10) y_test=to_categorical(y_test,num_classes=10)
自定义Block层,对应上面的公式
# 自定义highway-network的一个block class Block(Layer): def __init__(self,units,**kwargs): self.units=units self.weight_initializer=initializers.truncated_normal() self.bh_initializer=initializers.constant(0.01) # 根据论文,转换层使用负的偏置。这样开始训练时转换层输出小,信息基本原样流通 # 开始设置为-1,不行,这个参数还是敏感的 self.bt_initializer=initializers.constant(-0.3) super(Block,self).__init__(**kwargs) def build(self,input_shape): self.h_w=self.add_weight(name='hw',shape=(input_shape[-1],self.units),initializer=self.weight_initializer,trainable=True) self.t_w=self.add_weight(name='tw',shape=(input_shape[-1],self.units),initializer=self.weight_initializer,trainable=True) self.h_b=self.add_weight(name='hb',shape=(input_shape[-1],),initializer=self.bh_initializer,trainable=True) self.t_b=self.add_weight(name='tb',shape=(input_shape[-1],),initializer=self.bt_initializer,trainable=True) super(Block,self).build(input_shape) def call(self,inputs): h_out=K.relu(K.dot(inputs,self.h_w)+self.h_b) t_out=K.sigmoid(K.dot(inputs,self.t_w)+self.t_b) out1=t_out*h_out out2=(1-t_out)*inputs return out1+out2
先降维一下,再叠加10个Block,使用带动量的SGD训练,参数为134,090
block_layers=10 inputs=Input(shape=(784,)) x=Dense(64,activation='relu')(inputs) for i in range(block_layers): x=Block(64)(x) x=Dense(10,activation='softmax')(x) model=Model(inputs,x) model.compile(optimizer=optimizers.Adam(),loss=categorical_crossentropy,metrics=['accuracy']) model.summary()
model.fit(X_train,y_train,batch_size=32,epochs=20,verbose=2,validation_split=0.3)
观测训练后,选定epochs为6,再用完整数据集训练一遍,测试精度97.5%
model.fit(X_train,y_train,batch_size=32,epochs=6,verbose=2) model.evaluate(X_test,y_test)# 97.5%
作为对比,以下简单卷积网络测试精度即可达到97.83%,参数159,010
inputs=Input(shape=(784,)) x=Dense(200,activation='relu')(inputs) x=Dense(10,activation='softmax')(x) model=Model(inputs,x)
2,CNN
此处不再赘述,仅对模型创建过程说明一下,叠加10层,参数172,010,batch_size调整为128,训练后未在完整数据集再训练一遍,直接测试集精度为98.48%。但这也不够高。
layer_size=10 inputs=Input((28,28,1)) x=Conv2D(16,3,activation='relu',padding='same')(inputs) for i in range(layer_size): t=Conv2D(16,3,activation='sigmoid',padding='same',bias_initializer=initializers.constant(-1.))(x) h=Conv2D(16,3,activation='relu',padding='same',bias_initializer=initializers.random_uniform())(x) out1=Multiply()([t,h]) sub=Lambda(lambda p:1-p)(t) out2=Multiply()([x,sub]) x=Add()([out1,out2]) x=Flatten()(x) x=Dense(10,activation='softmax')(x) model=Model(inputs,x) model.summary()
3,BatchNormalization
调整验证集比例为20%
inputs=Input((28,28,1)) x=Conv2D(32,3,padding='same')(inputs) x=BatchNormalization()(x) x=Activation('tanh')(x) x=Conv2D(32,3,padding='same',activation='tanh')(x) x=MaxPooling2D()(x) x=Conv2D(64,3,padding='same')(x) x=BatchNormalization()(x) x=Activation('tanh')(x) x=Conv2D(64,3,padding='same',activation='tanh')(x) x=MaxPooling2D()(x) x=Flatten()(x) x=Dense(10,activation='softmax')(x) model=Model(inputs,x) model.compile(optimizer=optimizers.SGD(momentum=0.8,nesterov=True),loss=categorical_crossentropy,metrics=['accuracy'])
model.fit(X_train,y_train,batch_size=128,epochs=30,validation_split=0.2,verbose=2)
看看训练过程,可以看到,到训练30轮为止,验证损失仍没有上升迹象
Train on 48000 samples, validate on 12000 samples
Epoch 1/30
- 23s - loss: 0.2314 - accuracy: 0.9346 - val_loss: 0.1393 - val_accuracy: 0.9606
Epoch 2/30
- 23s - loss: 0.0756 - accuracy: 0.9778 - val_loss: 0.0675 - val_accuracy: 0.9810
Epoch 3/30
- 23s - loss: 0.0565 - accuracy: 0.9843 - val_loss: 0.0570 - val_accuracy: 0.9834
Epoch 4/30
- 23s - loss: 0.0451 - accuracy: 0.9870 - val_loss: 0.0519 - val_accuracy: 0.9851
Epoch 5/30
- 23s - loss: 0.0390 - accuracy: 0.9890 - val_loss: 0.0444 - val_accuracy: 0.9871
Epoch 6/30
- 23s - loss: 0.0335 - accuracy: 0.9905 - val_loss: 0.0431 - val_accuracy: 0.9878
Epoch 7/30
- 23s - loss: 0.0294 - accuracy: 0.9921 - val_loss: 0.0413 - val_accuracy: 0.9883
Epoch 8/30
- 23s - loss: 0.0267 - accuracy: 0.9928 - val_loss: 0.0396 - val_accuracy: 0.9899
Epoch 9/30
- 23s - loss: 0.0241 - accuracy: 0.9933 - val_loss: 0.0385 - val_accuracy: 0.9886
Epoch 10/30
- 23s - loss: 0.0222 - accuracy: 0.9942 - val_loss: 0.0391 - val_accuracy: 0.9877
Epoch 11/30
- 23s - loss: 0.0200 - accuracy: 0.9950 - val_loss: 0.0378 - val_accuracy: 0.9887
Epoch 12/30
- 23s - loss: 0.0188 - accuracy: 0.9950 - val_loss: 0.0381 - val_accuracy: 0.9881
Epoch 13/30
- 23s - loss: 0.0166 - accuracy: 0.9960 - val_loss: 0.0354 - val_accuracy: 0.9902
Epoch 14/30
- 23s - loss: 0.0156 - accuracy: 0.9961 - val_loss: 0.0379 - val_accuracy: 0.9886
Epoch 15/30
- 23s - loss: 0.0145 - accuracy: 0.9967 - val_loss: 0.0341 - val_accuracy: 0.9906
Epoch 16/30
- 23s - loss: 0.0133 - accuracy: 0.9971 - val_loss: 0.0345 - val_accuracy: 0.9902
Epoch 17/30
- 23s - loss: 0.0122 - accuracy: 0.9973 - val_loss: 0.0341 - val_accuracy: 0.9908
Epoch 18/30
- 23s - loss: 0.0113 - accuracy: 0.9978 - val_loss: 0.0346 - val_accuracy: 0.9900
Epoch 19/30
- 23s - loss: 0.0102 - accuracy: 0.9983 - val_loss: 0.0334 - val_accuracy: 0.9902
Epoch 20/30
- 23s - loss: 0.0097 - accuracy: 0.9982 - val_loss: 0.0326 - val_accuracy: 0.9910
Epoch 21/30
- 23s - loss: 0.0091 - accuracy: 0.9984 - val_loss: 0.0325 - val_accuracy: 0.9907
Epoch 22/30
- 23s - loss: 0.0083 - accuracy: 0.9987 - val_loss: 0.0325 - val_accuracy: 0.9905
Epoch 23/30
- 23s - loss: 0.0077 - accuracy: 0.9989 - val_loss: 0.0324 - val_accuracy: 0.9908
Epoch 24/30
- 23s - loss: 0.0073 - accuracy: 0.9990 - val_loss: 0.0330 - val_accuracy: 0.9900
Epoch 25/30
- 23s - loss: 0.0067 - accuracy: 0.9992 - val_loss: 0.0337 - val_accuracy: 0.9913
Epoch 26/30
- 23s - loss: 0.0065 - accuracy: 0.9992 - val_loss: 0.0318 - val_accuracy: 0.9907
Epoch 27/30
- 23s - loss: 0.0062 - accuracy: 0.9993 - val_loss: 0.0328 - val_accuracy: 0.9907
Epoch 28/30
- 23s - loss: 0.0056 - accuracy: 0.9995 - val_loss: 0.0316 - val_accuracy: 0.9914
Epoch 29/30
- 23s - loss: 0.0052 - accuracy: 0.9996 - val_loss: 0.0313 - val_accuracy: 0.9912
Epoch 30/30
- 23s - loss: 0.0049 - accuracy: 0.9997 - val_loss: 0.0313 - val_accuracy: 0.9911
完整数据集训练30轮后,测试精度99.17%。
后续可以尝试更深的网络,使用resnet。或者直接使用inception等。