一文看懂pandas的透视表pivot_table
一、概述
1.1 什么是透视表?
透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
1.2 为什么要使用pivot_table?
- 灵活性高,可以随意定制你的分析计算要求
- 脉络清晰易于理解数据
- 操作性强,报表神器
二、如何使用pivot_table
首先读取数据,数据集是火箭队当家球星James Harden某一赛季比赛数据作为数据集进行讲解。数据地址。
先看一下官方文档中pivot_table的函数体:pandas.pivot_table - pandas 0.21.0 documentation
pivot_table(data, values=None, index=None, columns=None,aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
pivot_table有四个最重要的参数index、values、columns、aggfunc,本文以这四个参数为中心讲解pivot操作是如何进行。
2.1 读取数据
-
import pandas as pd
-
import numpy as np
-
df = pd.read_csv('h:/James_Harden.csv',encoding='utf8')
-
df.tail()
数据格式如下:
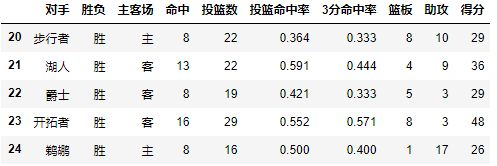
2.2 Index
每个pivot_table必须拥有一个index,如果想查看哈登对阵每个队伍的得分,首先我们将对手设置为index:
pd.pivot_table(df,index=[u'对手'])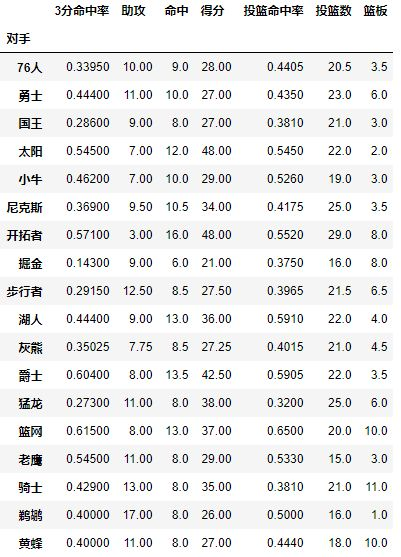
对手成为了第一层索引,还想看看对阵同一对手在不同主客场下的数据,试着将对手与胜负与主客场都设置为index,其实就变成为了两层索引
pd.pivot_table(df,index=[u'对手',u'主客场'])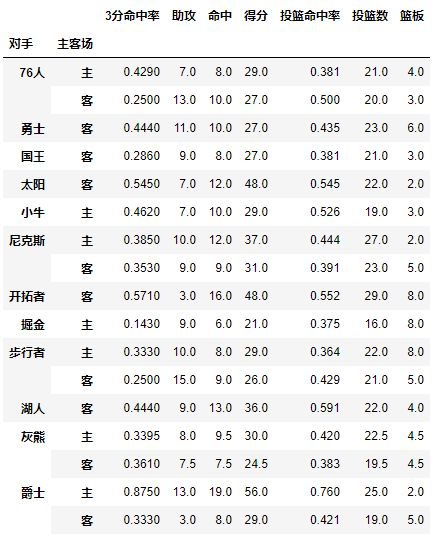
试着交换下它们的顺序,数据结果一样:
pd.pivot_table(df,index=[u'主客场',u'对手'])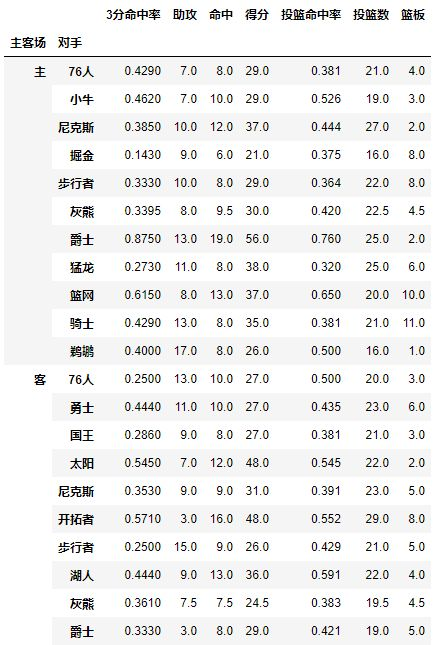
看完上面几个操作,Index就是层次字段,要通过透视表获取什么信息就按照相应的顺序设置字段,所以在进行pivot之前你也需要足够了解你的数据。
2.3 Values
通过上面的操作,我们获取了james harden在对阵对手时的所有数据,而Values可以对需要的计算数据进行筛选,如果我们只需要james harden在主客场和不同胜负情况下的得分、篮板与助攻三项数据:
pd.pivot_table(df,index=[u'主客场',u'胜负'],values=[u'得分',u'助攻',u'篮板'])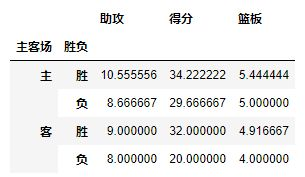
2.4 Aggfunc
aggfunc参数可以设置我们对数据聚合时进行的函数操作。
当我们未设置aggfunc时,它默认aggfunc='mean'计算均值。我们还想要获得james harden在主客场和不同胜负情况下的总得分、总篮板、总助攻时:
pd.pivot_table(df,index=[u'主客场',u'胜负'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.sum,np.mean])
2.5 Columns
Columns类似Index可以设置列层次字段,它不是一个必要参数,作为一种分割数据的可选方式。
-
#fill_value填充空值,margins=True进行汇总
-
pd.pivot_table(df,index=[u'主客场'],columns=[u'对手'],values=[u'得分'],aggfunc=[np.sum],fill_value=0,margins=1)
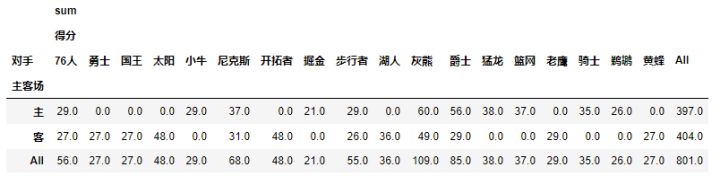
现在我们已经把关键参数都介绍了一遍,下面是一个综合的例子:
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.mean],fill_value=0)结果如下:
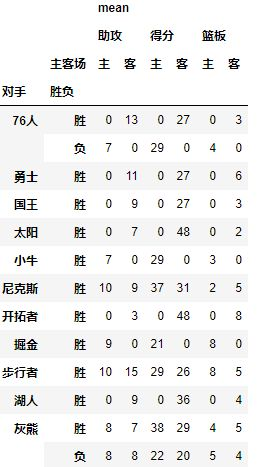
aggfunc也可以使用dict类型,如果dict中的内容与values不匹配时,以dict中为准。
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc={u'得分':np.mean, u'助攻':[min, max, np.mean]},fill_value=0)
结果就是助攻求min,max和mean,得分求mean,而篮板没有显示。
雪花
孙鑫C++视频教程 rmvb格式 全20CD完整版 精品分享
mac上用VMWare虚拟机装win7
阿里云如何解析域名,搭建云服务器环境
2. Windows编程基础
复制指定目录下的全部文件到另一个目录中
Select查询命令
使用OneNote2016发送博客
Linux数字雨