一 . 线程的两种创建方式
from threading import Thread
# 第一种创建方式
def f1(n):
print('%s号线程任务'%n)
def f2(n):
print('%s号线程任务'%n)
if __name__ == '__main__':
t1 = Thread(target=f1,args=(1,))
t2 = Thread(target=f2,args=(2,))
t1.start()
t2.start()
print('主线程')
# 第二种创建方式
class MyThread(Thread):
def __init__(self,name):
# super(MyThread, self).__init__() 和下面super是一样的
super().__init__()
self.name = name
def run(self):
print('hello girl :' + self.name)
if __name__ == '__main__':
t = MyThread('alex')
t.start()
print('主线程结束')
二 . 查看线程的pid
import os
from threading import Thread
def f1(n):
print('1号=>',os.getpid())
print('%s号线程任务' % n)
def f2(n):
print('2号=>',os.getpid())
print('%s号线程任务' % n)
if __name__ == '__main__':
t1 = Thread(target=f1,args=(1,))
t2 = Thread(target=f2,args=(2,))
t1.start()
t2.start()
print('主线程', os.getpid())
print('主线程')
# 由于这些线程都是在一个进程中的,所以pid一致
三 . 验证线程之间的数据共享
import time
from threading import Thread
num = 100
def f1(n):
global num
num = 3
time.sleep(1)
print('子线程的num', num) # 子线程的num 3
if __name__ == '__main__':
thread = Thread(target=f1,args=(1,))
thread.start()
thread.join() # 等待thread执行完在执行下面的代码
print('主线程的num', num) # 主线程的num 3
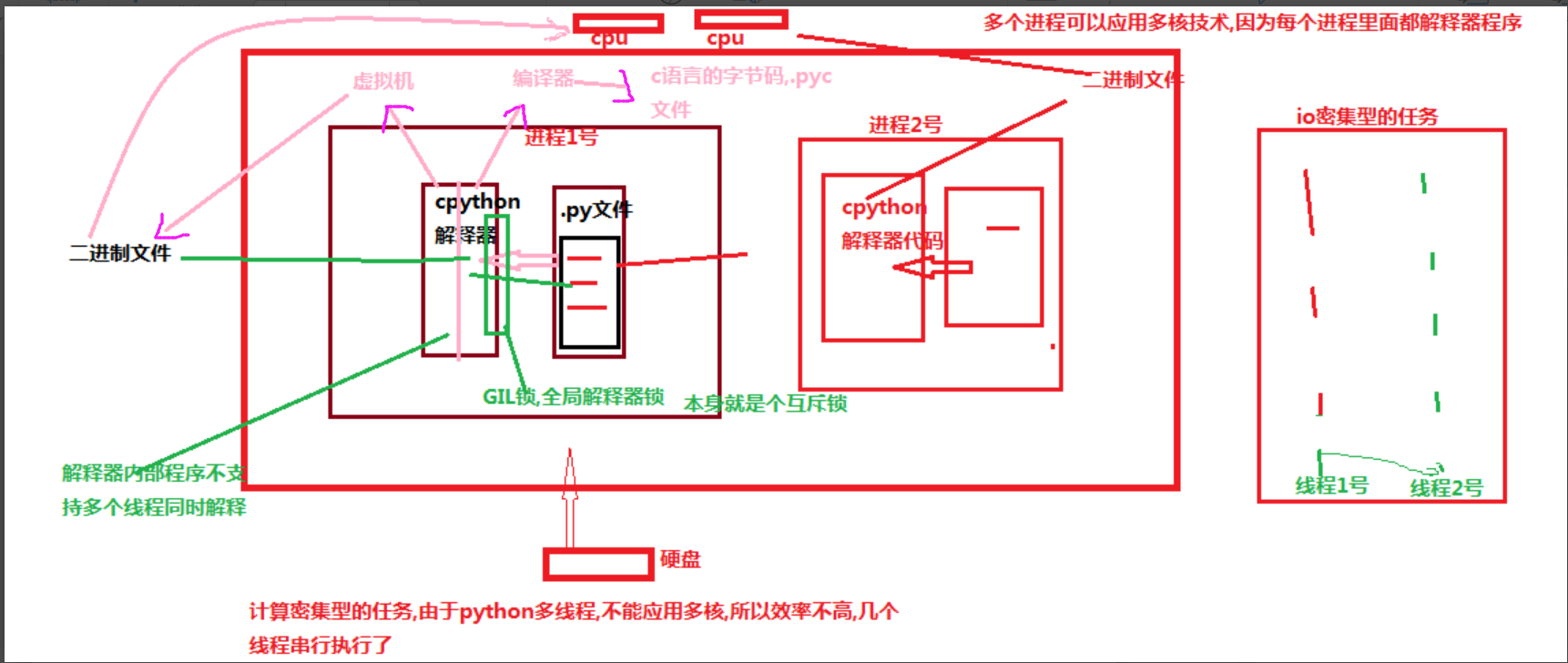
四. 多进程与多线程的效率对比
import time
from threading import Thread
from multiprocessing import Process
def f1():
# io密集型
# time.sleep(1)
# 计算型:
n = 10
for i in range(10000000):
n = n + i
if __name__ == '__main__':
#查看一下20个线程执行20个任务的执行时间
t_s_time = time.time()
t_list = []
for i in range(5):
t = Thread(target=f1,)
t.start()
t_list.append(t)
[tt.join() for tt in t_list]
t_e_time = time.time()
t_dif_time = t_e_time - t_s_time
#查看一下20个进程执行同样的任务的执行时间
p_s_time = time.time()
p_list = []
for i in range(5):
p = Process(target=f1,)
p.start()
p_list.append(p)
[pp.join() for pp in p_list]
p_e_time = time.time()
p_dif_time = p_e_time - p_s_time
# print('多线程的IO密集型执行时间:',t_dif_time) # 1.0017869472503662 还需要减1秒的time.sleep
# print('多进程的IO密集型执行时间:',p_dif_time) # 1.2237937450408936 也需要减1秒的time.sleep
print('多线程的计算密集型执行时间:', t_dif_time) # 3.58754563331604
print('多进程的计算密集型执行时间:', p_dif_time) # 2.1555309295654297
# 从上述代码中的执行效率可以看出来,多线程在执行IO密集型的程序的时候速度非常快,但是执行计算密集型的程序的时候很慢,所以说python这门语言不适合做大数据.
五 . 互斥锁,同步锁
import time
from threading import Lock, Thread
num = 100
def f1(loc):
# 加锁
with loc:
global num
tmp = num
tmp -= 1
time.sleep(0.001)
num = tmp
# 上面的代码相当于 num -= 1
if __name__ == '__main__':
t_loc = Lock()
t_list = []
for i in range(10):
t = Thread(target=f1,args=(t_loc,))
t.start()
t_list.append(t)
[tt.join() for tt in t_list]
print('主线的num',num)
六 . 死锁现象
import time
from threading import Thread,Lock,RLock
def f1(locA,locB):
locA.acquire()
print('f1>>1号抢到了A锁')
time.sleep(1)
locB.acquire()
print('f1>>1号抢到了B锁')
locB.release()
locA.release()
def f2(locA,locB):
locB.acquire()
print('f2>>2号抢到了B锁')
time.sleep(1)
locA.acquire()
print('f2>>2号抢到了A锁')
locA.release()
locB.release()
if __name__ == '__main__':
# locA = locB = Lock() # 不能这么写,这么写相当于这两个是同一把锁
locA = Lock()
locB = Lock()
t1 = Thread(target=f1,args=(locA,locB))
t2 = Thread(target=f2,args=(locA,locB))
t1.start()
t2.start()
# 上面的代码表示f1 先抢到了A锁,同时f2 抢到了B锁,一秒后f1想去想B锁,同时f2想去抢A锁,
# 由于锁需要先放开才能继续抢,导致了死锁现象
七.递归锁
import time
from threading import Thread, Lock, RLock
def f1(locA, locB):
locA.acquire()
print('f1>>1号抢到了A锁')
time.sleep(1)
locB.acquire()
print('f1>>1号抢到了B锁')
locB.release()
locA.release()
def f2(locA, locB):
locB.acquire()
print('f2>>2号抢到了B锁')
locA.acquire()
time.sleep(1)
print('f2>>2号抢到了A锁')
locA.release()
locB.release()
if __name__ == '__main__':
locA = locB = RLock() #递归锁,维护一个计数器,acquire一次就加1,release就减1 , acquire等于0的时候才可以抢
t1 = Thread(target=f1, args=(locA, locB))
t2 = Thread(target=f2, args=(locA, locB))
t1.start()
t2.start()
# 递归锁解决了死锁现象,会让代码继续执行.
八. 守护线程
守护线程会等到所有的非守护线程运行结束后才结束
import time
from threading import Thread
from multiprocessing import Process
#守护进程:主进程代码执行运行结束,守护进程随之结束
#守护线程:守护线程会等待所有非守护线程运行结束才结束
def f1():
time.sleep(2)
print('1号线程')
def f2():
time.sleep(3)
print('2号线程')
if __name__ == '__main__':
t1 = Thread(target=f1,)
t2 = Thread(target=f2,)
# t1.daemon = True # 1号进程 和 2 号进程都会打印
t2.daemon = True # 不会打印2号进程
t1.start()
t2.start()
print('主线程结束')
# 与进程对比
p1 = Process(target=f1, )
p2 = Process(target=f2, )
p1.daemon = True # 只会打印 2号进程
p2.daemon = True # 只会打印1号进程
p1.start()
p2.start()
print('主进程结束')
九 . GIL锁的解释